- Products

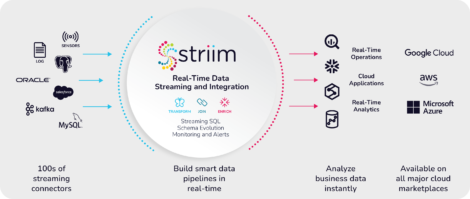
A fully managed SaaS solution that enables infinitely scalable unified data integration and streaming.

On-premise or in a self-managed cloud to ingest, process, and deliver real-time data.
- Solutions

Unify data in real time on a fully managed, SaaS-based platform optimized for the power and scalability of AI-ready data pipelines.

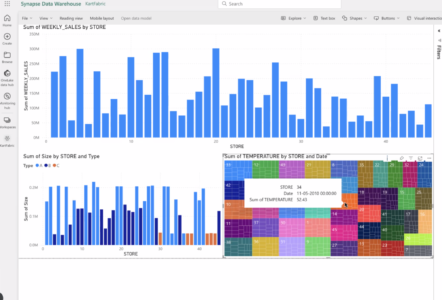
Quickly move data to Microsoft Azure and accelerate time-to-insight with Azure Synapse Analytics and Power BI.

Deliver real-time data to AWS, for faster analysis and processing.

Unify data on Google Cloud and power real-time data analytics in BigQuery.
- Pricing

Flexible Models for Every Business.
- Connectors

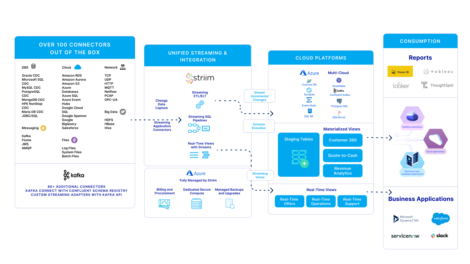
Striim can connect hundreds of source and target combinations. View a complete list.
- Resources

A podcast covering latest news and trends in data. cloud and analytics

Join us for an in-person, virtual, or on-demand event

Stay up to date on new product updates & join the discussion

Let Striim’s services and support experts bring your Data Products to life

Join us and discover self-directed learning courses tailored to your needs
- Company

Learn all about Striim, our heritage, leaders and investors

Looking to work for Striim? Find all the available job options

See how our customers are implementing our solutions

Find out more about Striim's partner network

Find all the latest news about Striim

Connect with the experts at Striim