We are excited to announce our new Striim Database Migration Service, StreamShift that provides native integration with Microsoft Azure Cosmos DB. We have worked hard to resolve any pain points around data integration, migration and data analytics for Azure Cosmos DB users. Striim provides a rich user experience, cost effective data movement, enhanced throughput throttling, and flexibility with over 100 native connectors.
Problem
Traditional ETL data movement methods are not suitable for today’s analytics or database migration needs. Batch ETL methods introduce latency by periodically reading from the source data service and writing to target data warehouses or databases after a scheduled time. Any analytics or conclusions made from the target data service are done on old data, delaying business decisions, and potentially creating missed business opportunities. Additionally, we often see a hesitancy to migrate to the cloud where users are concerned of taking any downtime for their mission critical applications.
Azure Cosmos DB users need native integration that supports relational databases, non-relational and document databases as sources and offers flexibility to fine-tune Azure Cosmos DB target properties.
Striim’s latest integration with Cosmos DB solves the problem
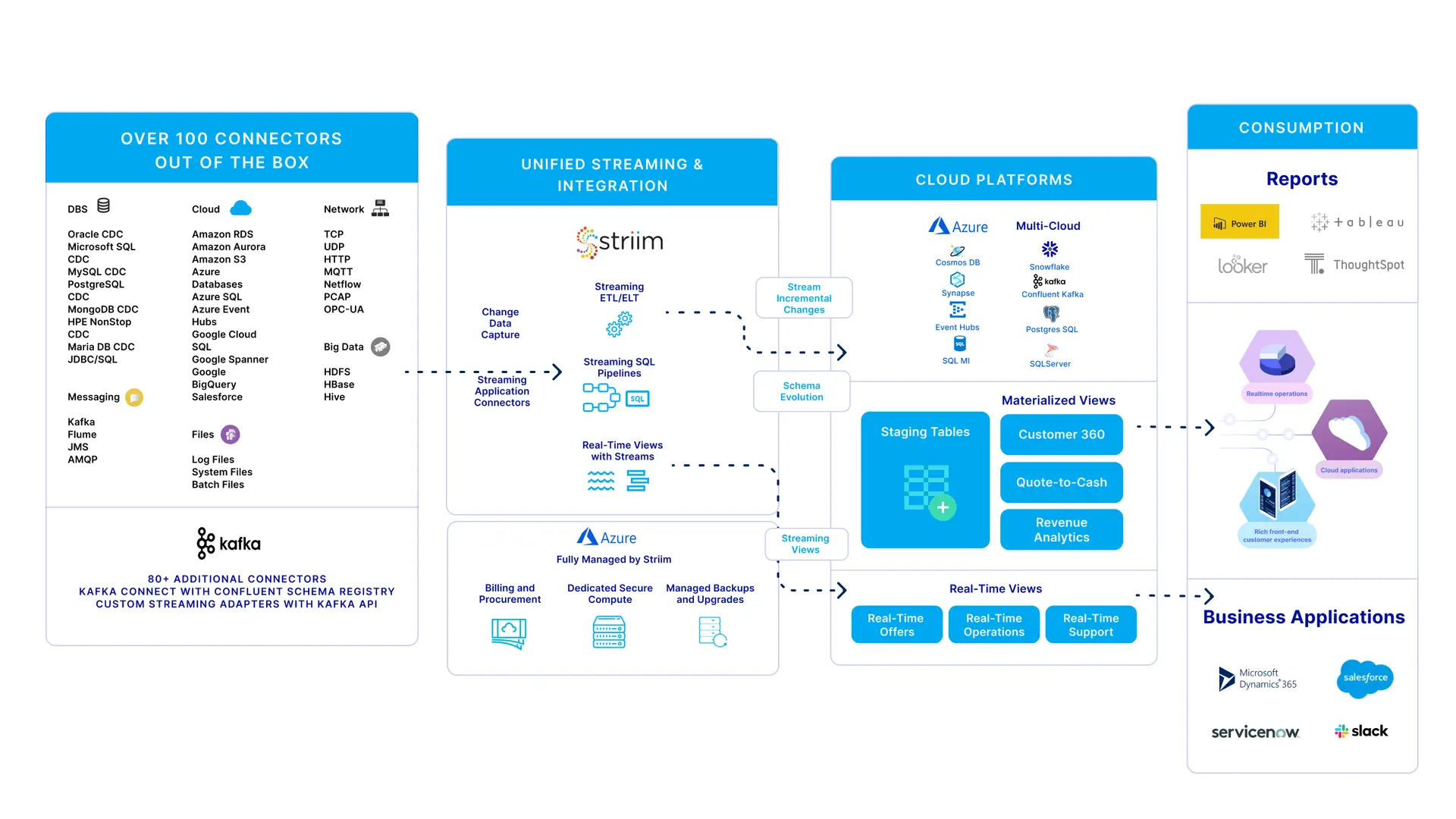
The Striim software platform offers continuous real-time data movement from a wide range of on-premises and cloud-based data sources to Azure. While moving the data, Striim has in-line transformation and processing capability (e.g., denormalization). You can use Striim to move data into the main Azure services, such as Azure Synapse, Azure SQL Database, Azure Cosmos DB, Azure Storage, Azure Event Hubs, Azure Database for MySQL and Azure Database for PostgreSQL, Azure HDInsight, in a consumable form, quickly and continuously.
Striim offers real-time uninterrupted continuous data replication with automatic data validation, which assures zero data loss and data corruption.
Even though Striim can move data to various other Azure targets, in this blog we will focus on Azure Cosmos DB use cases that were recently released.
Supported sources for Azure Cosmos DB as a target:
| Source | Target |
|---|---|
| SQL | Azure Cosmos DB |
| MongoDB | Azure Cosmos DB |
| Cassandra | Azure Cosmos DB |
| Oracle | Azure Cosmos DB |
| MySQL | Azure Cosmos DB |
| PostgreSQL | Azure Cosmos DB |
| Salesforce | Azure Cosmos DB |
| HDFS | Azure Cosmos DB |
| MSJet | Azure Cosmos DB |
Architecture
The architecture below shows how Striim can replicate data from a range of sources including heterogeneous databases to various targets on Azure. However, this blog will focus on Azure Cosmos DB.
Low-Impact Change Data Capture
Striim uses CDC (Change Data Capture) to extract change data from the database’s underlying transaction logs in real time, which minimizes the performance load on the RBMS by eliminating additional queries.
- Non-stop, non-intrusive data ingestion for high-volume data
- Support for data warehouses such as Oracle Exadata, Teradata, Amazon Redshift; and databases such as Oracle, SQL Server, HPE Nonstop, MySQL, PostgreSQL, MongoDB, Amazon RDS for Oracle, Amazon RDS for MySQL
- Real-time data collection from logs, sensors, Hadoop, and message queues to support operational decision making
Continuous Data Processing and Delivery
- In-flight transformations – including denormalization, filtering, aggregation, enrichment – to store only the data you need, in the right format
Built-In Monitoring and Validation
- Interactive, live dashboards for streaming data pipelines
- Continuous verification of source and target database consistency
- Real-time alerts via web, text, email
Use case: Replicating On-premises MongoDB data to Azure Cosmos DB
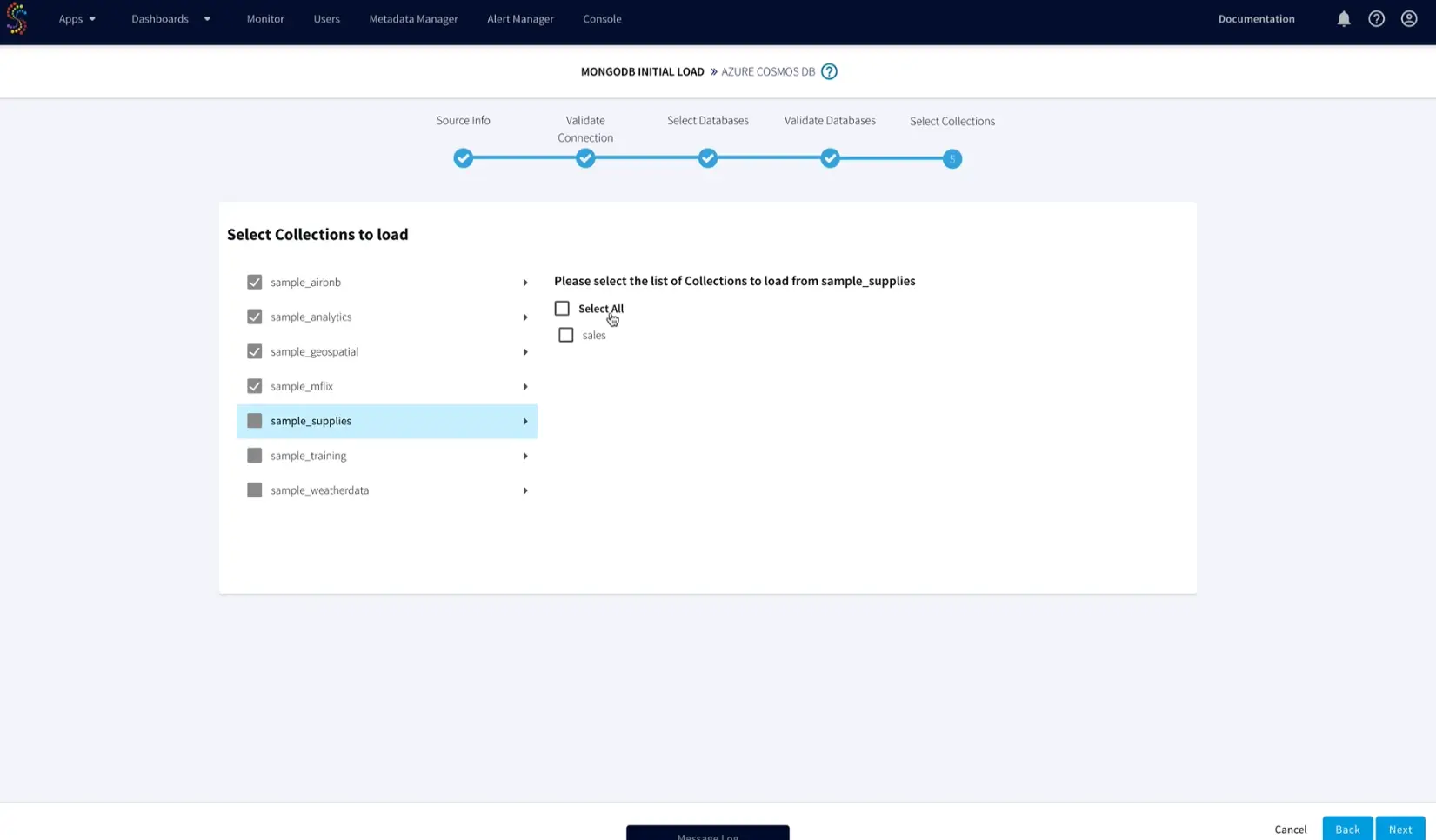
Let’s take a look at how to migrate data from MongoDB to the Azure Cosmos DB API for MongoDB within Striim. Using the new native Azure Cosmos DB connector users can now set properties like collections, RUs, partition key, exclude collections, batch policy, retry policy, etc. before replication.
To get started, in your Azure Cosmos DB instance, create a database mydb containing the collection employee with the partition key /name.
After installing Striim either locally or through the Azure Marketplace, you can take advantage of the Web UI and wizard-based application development to migrate and replicate data to Azure Cosmos DB in only a few steps.
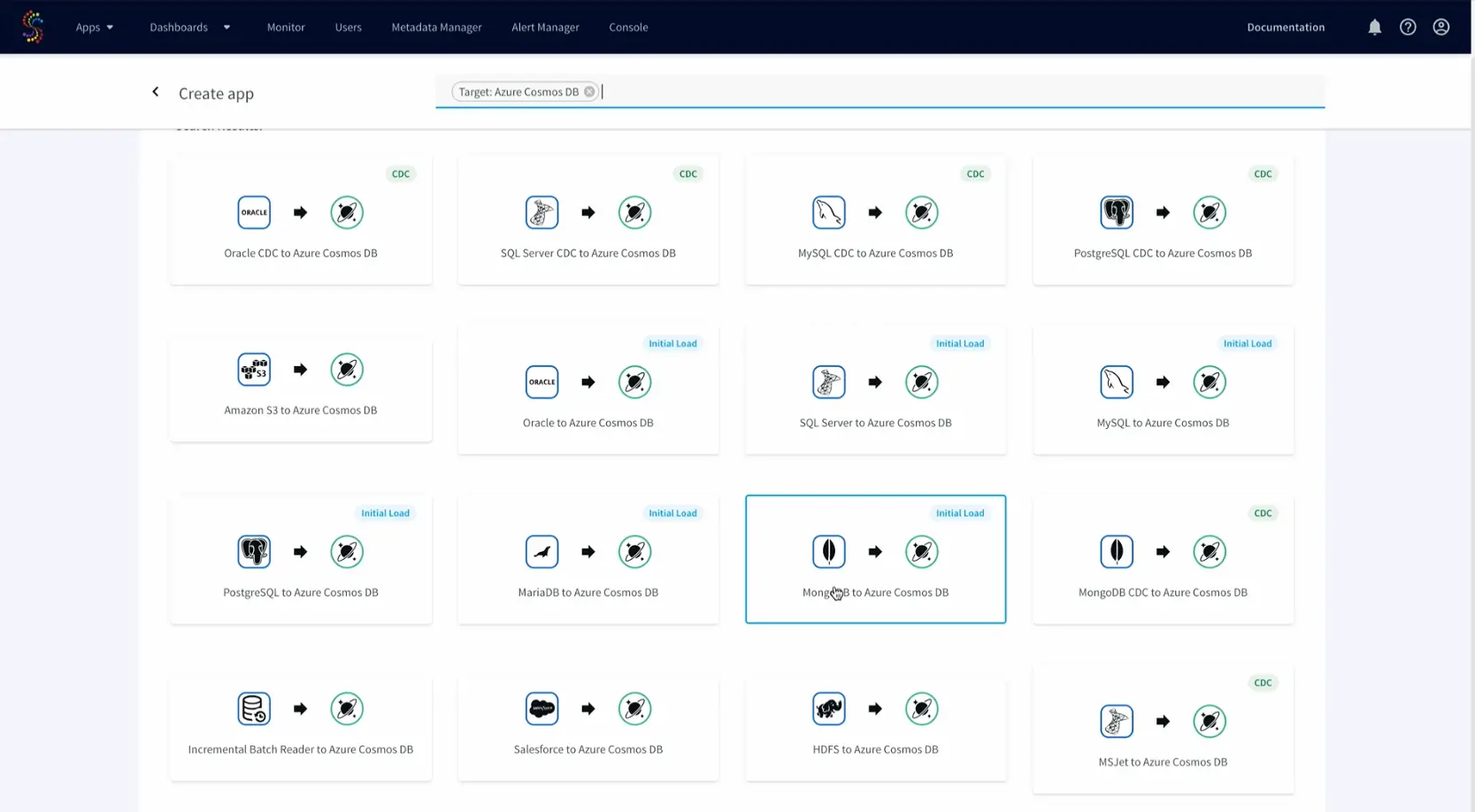
- Choose MongoDB to Azure Cosmos DB app from applications available on Striim

- Enter your source MongoDB connection details and select the databases and collections to be moved to Azure Cosmos DB.

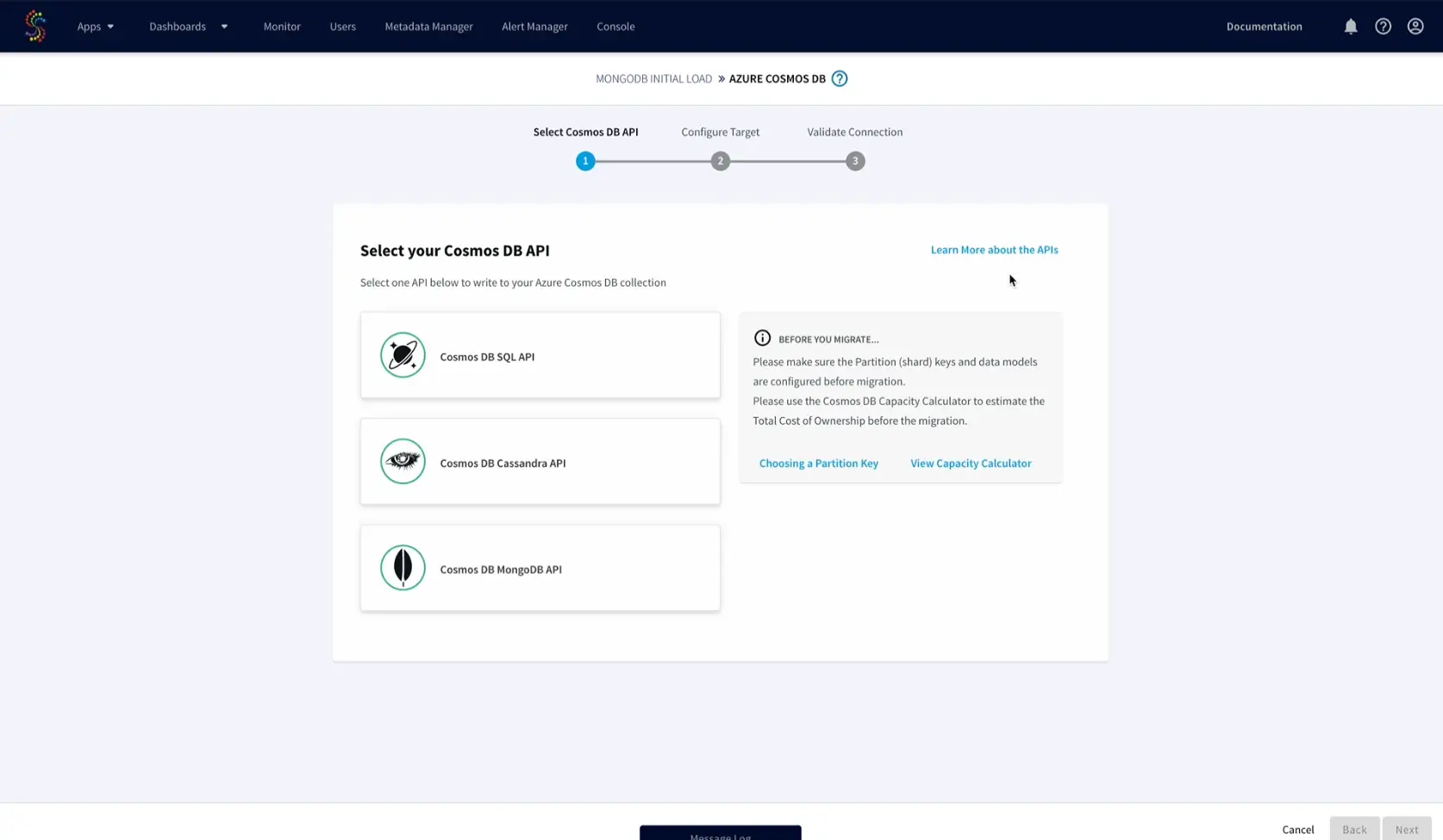
- Striim users now will have customized options to choose the Azure Cosmos DB target APIs between Mongo, Cassandra, or Core (SQL). Throughput (RU/s) calculation and cost can be calculated using Azure Cosmos DB capacity calculator and appropriate partition key must be chosen for the target. The details can be referred directly within Striim’s configuration wizard.

- Enter the target Azure Cosmos DB connection details and map the MongoDB to Azure Cosmos DB collections.

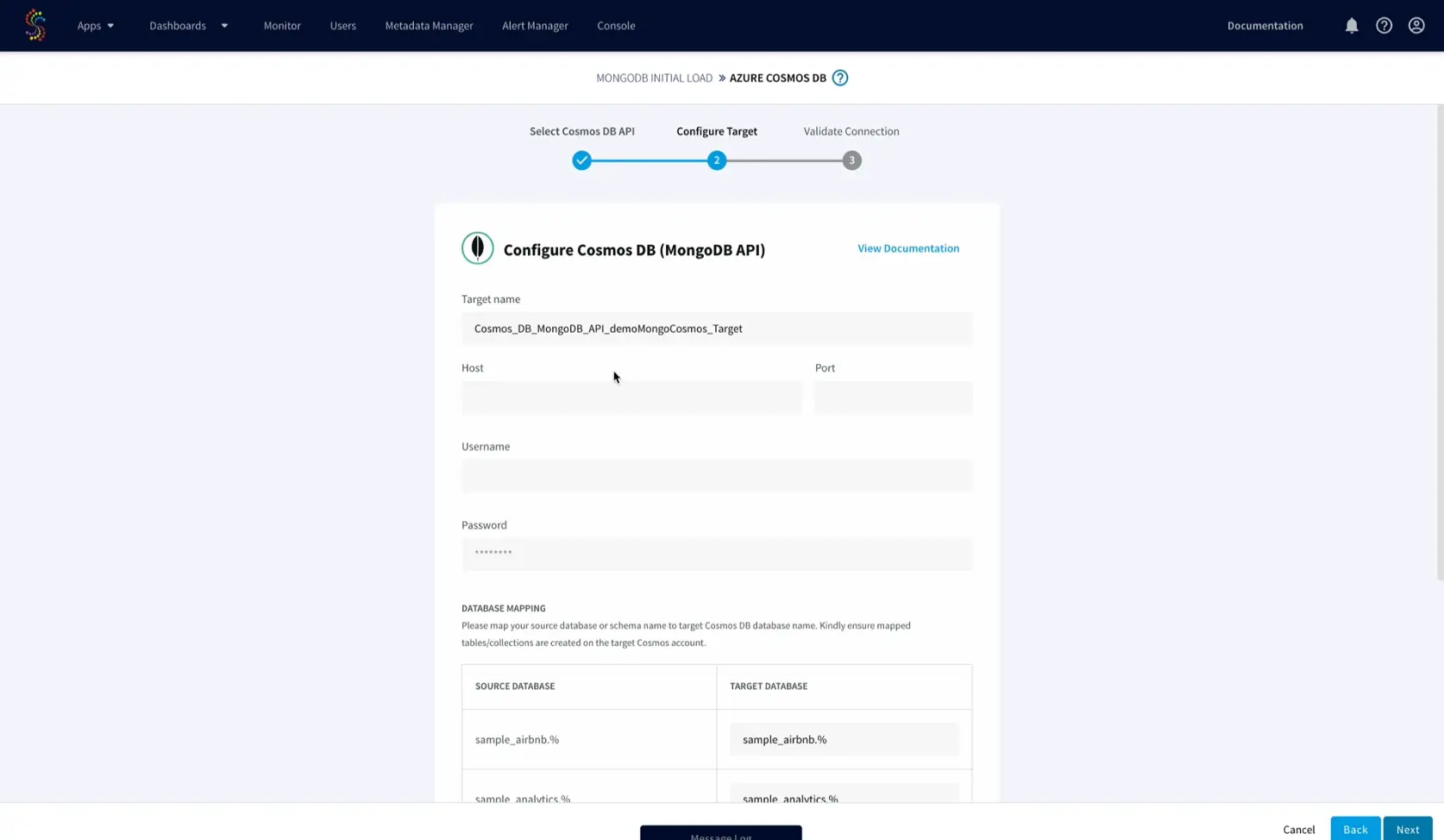
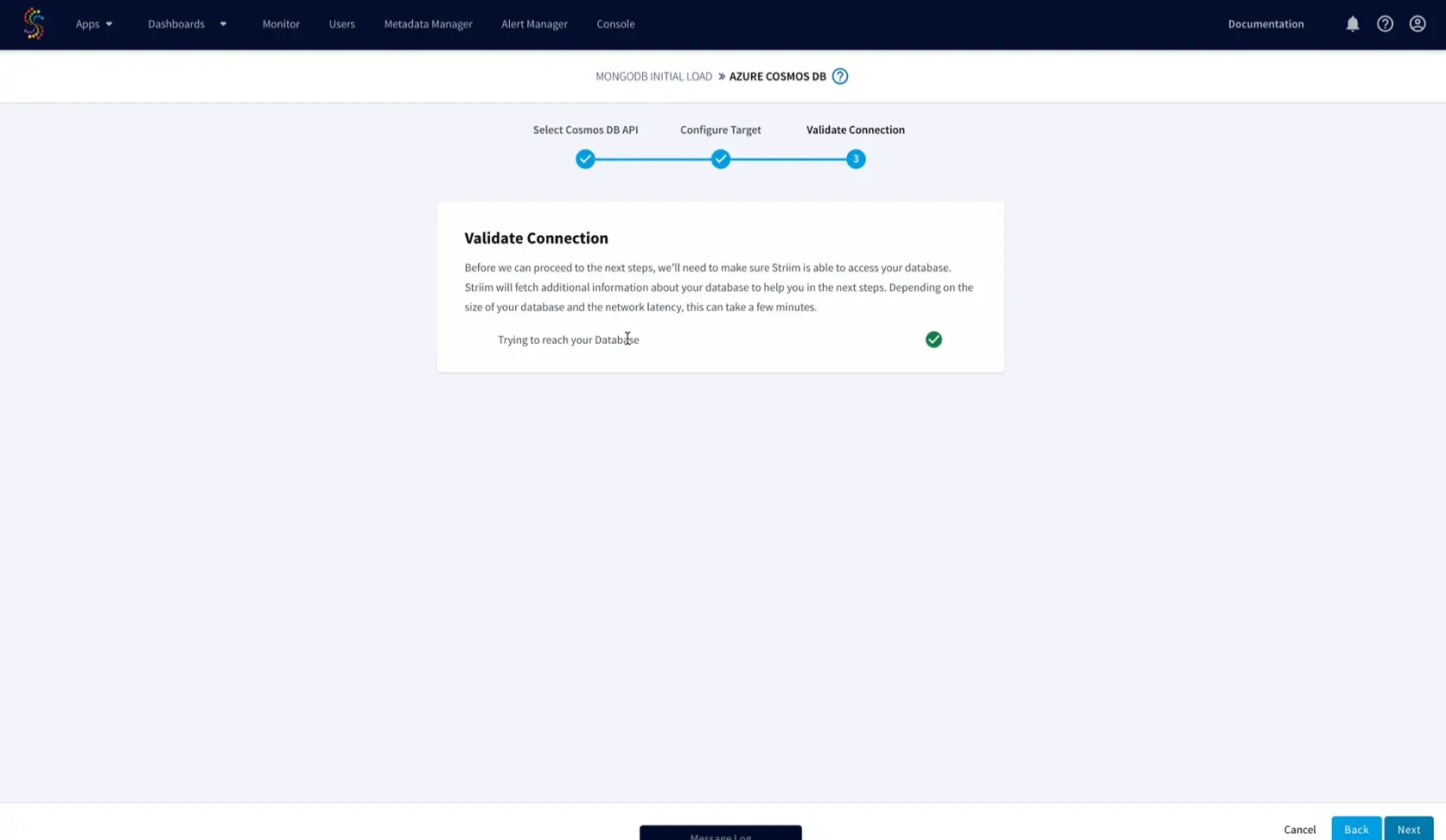
That’s it! Striim will handle the rest from validating the connection string and properties required for the data pipeline to automatically moving the data validating the data on the target. After completing the wizard, you’ll arrive at the Flow Designer page, and start seeing data replicated in real time.
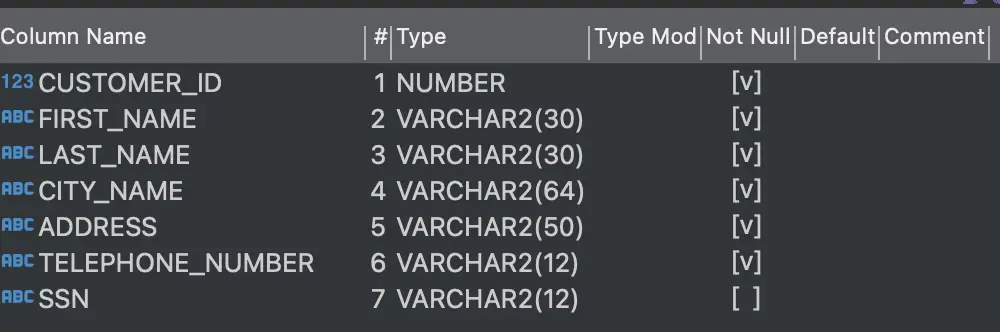
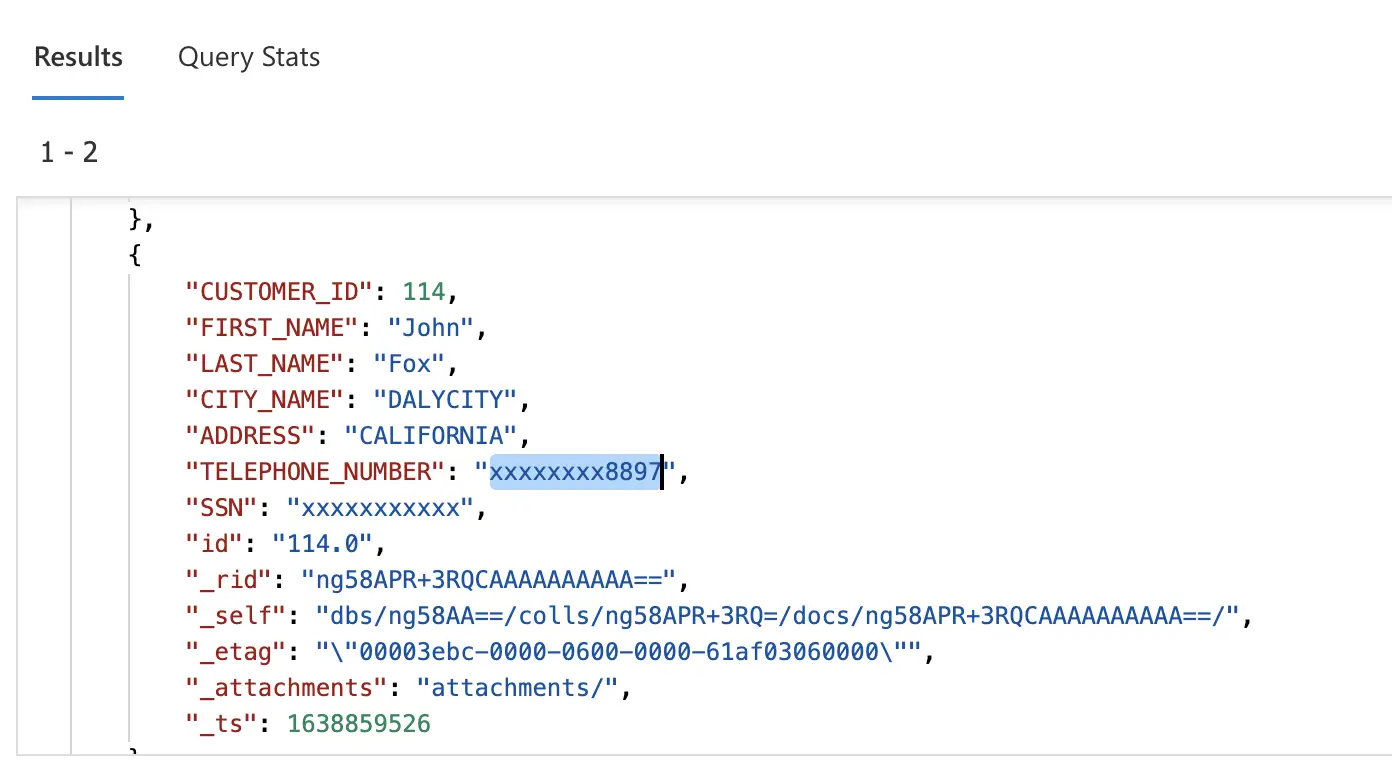
Let’s take another example, say we have an on-premises Oracle database with the customer table shown below. While migrating this Oracle database to Azure Cosmos DB we may want to mask or hide the customer Telephone number and SSN columns.
In two simple steps, we can achieve this in flight with Striim.
Step 1 – Create App: Within the Striim UI create an application with a source Oracle Reader. In the left-hand menu bar under the Event Transformers tab, drag and drop the To DB Event Transformer. Then, drag and drop the Field Masker onto the pipeline and specify the fields to be masked. Insert type conversion of WA event type to Typed event and create Field Mask component and select the fields to be masked. In our case we want the Telephone number field to be partially masked and SSN to be fully masked. Lastly, drag and drop a Cosmos DB Target to write to Cosmos DB.
Step 2 – Run App: Deploy and run the app. Check the target Azure Cosmos DB Data Explorer you should see the customer phone number and SSN are masked.
Instead of using these out of the box transformations within the UI, you can also write SQL statements using a Continuous Query (CQ), or Java code using an Open Processor (OP) component. The OP can also be used to merge multiple source documents into a single Azure Cosmos DB document. For our example, you can use the attached SQL statement in a CQ instead of the two transformation components.
SELECT CUSTOMER_ID AS CUSTOMER_ID, FIRST_NAME AS FIRST_NAME, LAST_NAME AS LAST_NAME, CITY_NAME AS CITY_NAME, ADDRESS AS ADDRESS, maskCreditCardNumber(TELEPHONE_NUMBER, “ANONYMIZE_PARTIALLY”) AS TELEPHONE_NUMBER, maskCreditCardNumber(SSN, “ANONYMIZE_COMPLETELY”) AS SSN FROM converted_events2 i;

Benefits
- Purpose-built service with specific configuration parameters to control scale, performance and cost
- Driving continuous cloud service consumption through ongoing data flow (vs. scheduled batch load).
- In-flight transformations – including denormalization, filtering, aggregation, enrichment – to store only the data you need, in the right format
- Allowing low-latency data to be available in Azure for more valuable workloads.
- Mitigating risks in Azure adoption by enabling a phased transition, where customers can use their existing and new Azure systems in parallel. Striim can move real-time data from customers’ existing data warehouses such as Teradata and Exadata, and on-prem or cloud-based OLTP systems, such as Oracle, SQLServer, PostgreSQL, MySQL, and HPE Nonstop using low-impact change data capture (CDC).
Interested in learning more about Striim’s native integration with Azure Cosmos DB? Please visit our listing on the Azure Marketplace.


