In Part 4 of this blog series, we shared how the Striim platform facilitates data processing and preparation, both as it streams in to Kafka, and as it streams out of Kafka to enterprise targets. In this 5th and final post in the “Making the Most of Apache Kafka” series, we will focus on enabling streaming analytics for Kafka data, and wrap it up with a discussion of some of Striim’s enterprise-grade features: scalability, reliability (including exactly once processing), and built-in security.
Streaming Analytics for Kafka
To perform analytics on streaming Kafka data, you probably don’t want to deliver the data to Hadoop or a database before analyzing it, because you will lose the real-time nature of Kafka. You need to do the analytics in-memory, as the data is flowing through, and be able to surface the results of the analytics through visualizations in a dashboard.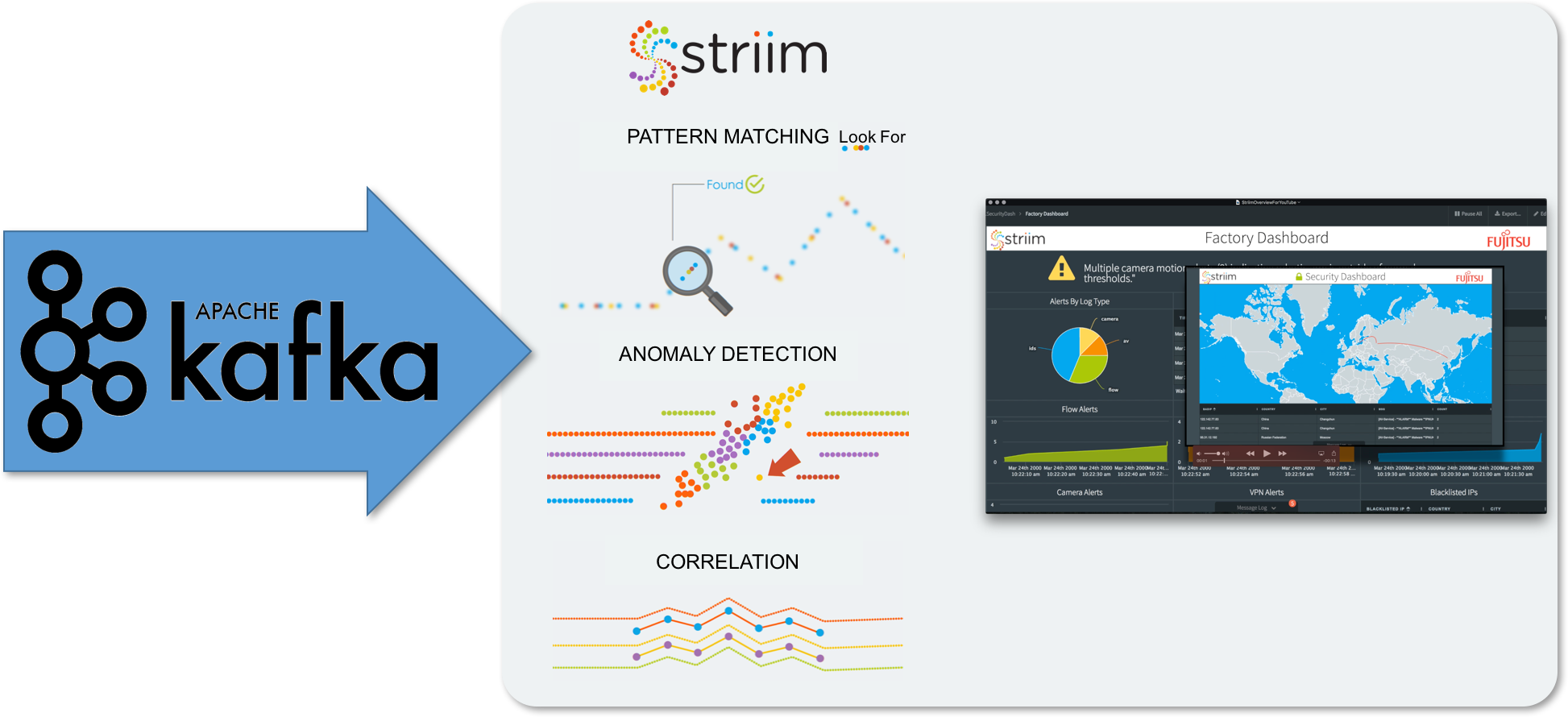
Kafka analytics can involve correlation of data across data streams, looking for patterns or anomalies, making predictions, understanding behavior, or simply visualizing data in a way that makes it interactive and interrogable.
The Striim platform enables you to perform Kafka analytics in-memory, in the same way as you do processing – through SQL-based continuous queries. These queries can join data streams together to perform correlation, and look for patterns (or specific sequences of events over time) across one or more data streams utilizing an extensive pattern-matching syntax.
Continuous statistical functions and conditional logic enable anomaly detection, while built-in regression algorithms enable predictions into the future based on current events.
Of course, analytics can also be rooted in understanding large datasets. Striim customers have integrated machine learning into data flows to perform real-time inference and scoring based on existing models. This utilizes Striim in two ways.
Firstly, as mentioned previously, you can prepare and deliver data from Kafka (and other sources) into storage in your desired format. This enables the real-time population of raw data used to generate machine learning models.
Secondly, once a model has been constructed and exported, you can easily call the model from our SQL, passing real-time data into it, to infer outcomes continuously. The end result is a model that can be frequently updated from current data, and a real-time data flow that can matches new data to the model, spots anomalies or unusual behavior, and enables proactive responses.
The final piece of analytics is visualizing and interacting with data. The Striim Platform UI includes a complete Dashboard builder that an enables custom, use-case-specific dashboards to be rapidly created to effectively highlight real-time data and the results of analytics. With a rich set of visualizations, and simple query-based integration with analytics results, dashboards can be configured to continually update and enable drill-down and in-page filtering.
Putting It All Together
Building a platform that makes the most of Kafka by enabling true stream processing and analytics is not easy. There are multiple major pieces of in-memory technology that have to be integrated seamlessly and tuned in order to be enterprise-grade. This means you have to consider the scalability, reliability and security of the complete end-to-end architecture, not just a single piece.
Joining streaming data with data cached in an in-memory data grid, for example, requires careful architectural consideration to ensure all pieces run in the same memory space, and joins can be performed without expensive and time-consuming remote calls. Continually processing and analyzing hundreds of thousands, or millions, of events per second across a cluster in a reliable fashion is not a simple task, and can take many years of development time.
The Striim Platform has been architected from the ground up to scale, and Striim clusters are inherently reliable with failover, recovery and exactly-once processing guaranteed end-to-end, not just in one slice of the architecture.
Security is also treated holistically, with a single role-based security model protecting everything from individual data streams to complete end-user dashboards.
If you want to make the most of Kafka, you shouldn’t have to architect and build a massive infrastructure, nor should you need an army of developers to craft your required processing and analytics. The Striim Platform enables Data Scientists, Business Analysts and other IT and data professionals to get the most value out of Kafka without having to learn, and code to, APIs.
For more information on Striim’s latest enhancements relating to Kafka, please read this week’s press release, “New Striim Release Further Bolsters SQL-based Streaming and Database Connectivity for Kafka.” Or download the Striim platform for Kafka and try it for yourself.


