In Part 3 of this blog series, we discussed how the Striim platform facilitates moving Kafka data to a wide variety of enterprise targets, including Hadoop and Cloud environments. In this post, we focus on in-stream Kafka data processing and preparation, whether streaming data to Kafka, or from Kafka to enterprise targets.
Kafka Data Processing and Preparation
When delivering data to Kafka, or writing Kafka data to a downstream target like HDFS, it is essential to consider the structure and content of the data you are writing. Based on your use case, you may not require all of the data, only that which matches certain criteria. You may also need to transform the data through string manipulation or data conversion, or only send aggregates to prevent data overload.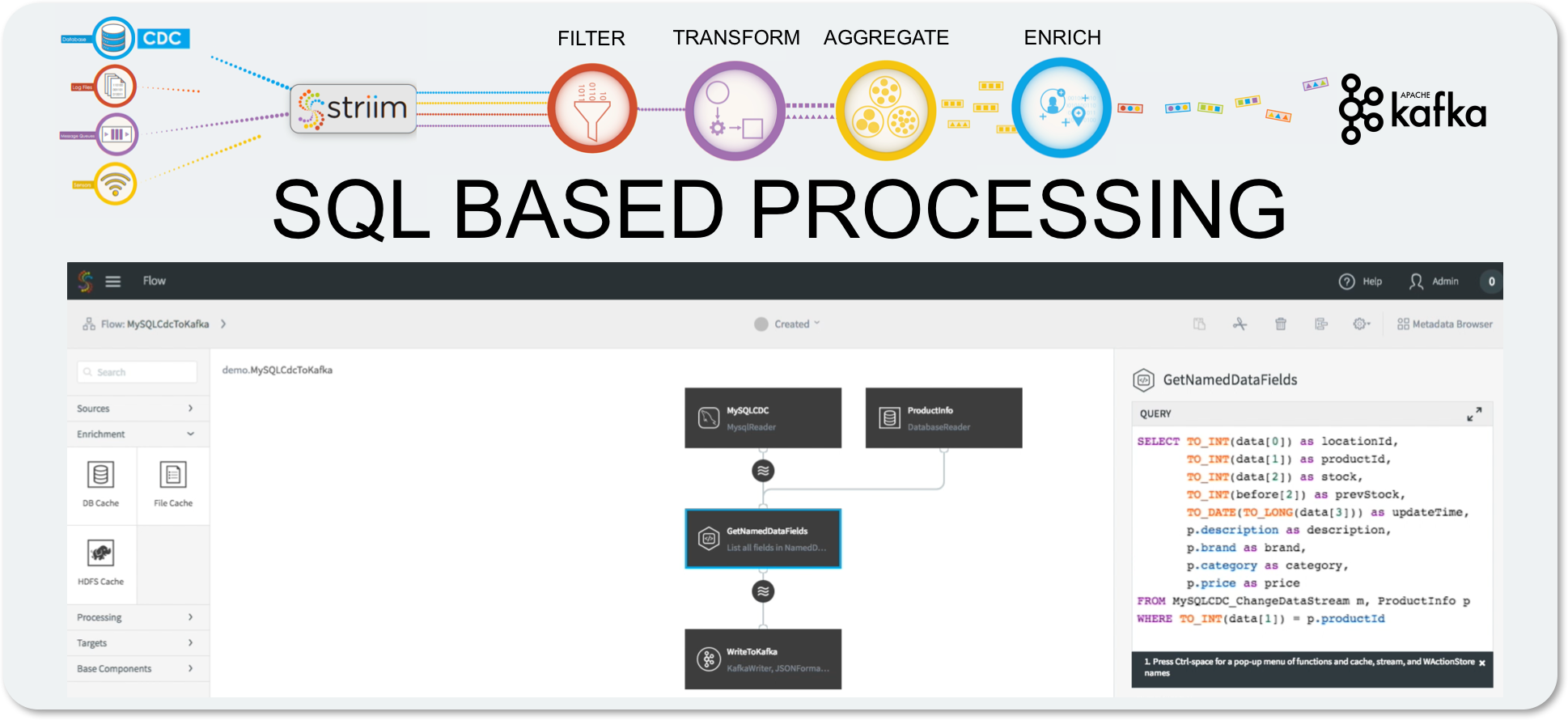
Most importantly, you may need to add additional context to the Kafka data. A lot of raw data may need to be joined with additional data to make it useful.
Imagine using CDC to stream changes from a normalized database. If you have designed the database correctly, most of the data fields will be in the form of IDs. This is very efficient for the database, but not very useful for downstream queries or analytics. IoT data can present a similar situation, with device data consisting of a device ID and a few values, without any meaning or context. In both cases, you may want to enrich the raw data with reference data, correlated by the IDs, to produce a denormalized record with sufficient information.
The key tenets of stream processing and data preparation – filtering, transformation, aggregation and enrichment – are essential to any data architecture, and should be easy to apply to your Kafka data without any need for developers or complex APIs.
The Striim Platform simplifies this by using a uniform approach utilizing in-memory continuous queries, with all of the stream processing expressed in a SQL-like language. Anyone with any data background understands SQL, so the constructs are incredibly familiar. Transformations are simple and can utilize both built-in and Java functions, CASE statements and other mechanisms. Filtering is just a WHERE clause.
Aggregations can utilize flexible windows that turn unbounded infinite data streams into continuously changing bounded sets of data. The queries can reference these windows and output data continuously as the windows change. This means a one-minute moving average is just an average function over a one-minute sliding window.
Enrichment requires external data, which is introduced into the Striim Platform through the use of distributed caches (otherwise known as a Data Grid). Caches can be loaded with large amounts of reference data, which is stored in-memory across the cluster. Queries can reference caches in a FROM clause the same way as they reference streams or windows, so joining against a cache is simply a JOIN in a query.
Multiple stream sources, windows and caches can be used and combined together in a single query, and queries can be chained together in directed graphs, known as data flows. All of this can be built through the UI or our scripting language, and can be easily deployed and scaled across a Striim cluster, without having to write any code.
For more information on Striim’s latest enhancements relating to Kafka, please read this week’s press release, “New Striim Release Further Bolsters SQL-based Streaming and Database Connectivity for Kafka.” Or download the Striim platform for Kafka and try it for yourself.
Continue reading this series with Part 5: “Making the Most of Apache Kafka,” – Streaming Analytics for Kafka.


