
Companies throughout the world generate large amounts of data, which continues to grow at a rapid pace. By 2025, the total number of data created, consumed, and stored in the world is expected to accumulate up to 181 zettabytes.
A significant amount of data is produced as live or real-time streams, also referred to as streaming data. These streams can come from a wide range of sources, including clickstream data from mobile apps and websites, IoT-powered sensors, and server logs. The ability to track and analyze streaming data has become crucial for organizations to lend support to their departmental operations.
However, there are a couple of challenges that make it difficult for organizations to deal with streaming data.
- You have to collect large amounts of data from streaming sources that generate events every minute.
- In its raw form, streaming data lacks structure and schema, which makes it tricky to query with analytic tools.
Today, there’s an increasing need to process, parse, and structure streaming data before any proper analysis can be done on it. For instance, what happens when someone uses a ride-hailing app? The app uses real-time data for location tracking, traffic data, and pricing to provide the most suitable driver. It also estimates how much time it’ll take to reach the destination based on real-time and historical data. The entire process from the user’s end takes a few seconds. But what if the app fails to collect and process any of this data on time? There’s no value to the app if the data processing isn’t done in real time.
Traditionally, batch-oriented approaches are used for data processing. However, these approaches are unable to handle the vast streams of data generated in real time. To address these issues, many organizations are turning to stream processing architectures as an effective solution for processing vast amounts of incoming data and delivering real-time insights for end users.
What is Stream Processing?
Stream processing is a data processing paradigm that continuously collects and processes real-time or near-real-time data. It can collect data streams from multiple sources and rapidly transform or structure this data, which can be used for different purposes. Examples of this type of real-time data include information from social media networks, e-commerce purchases, in-game player activity, and log files of web or mobile users.
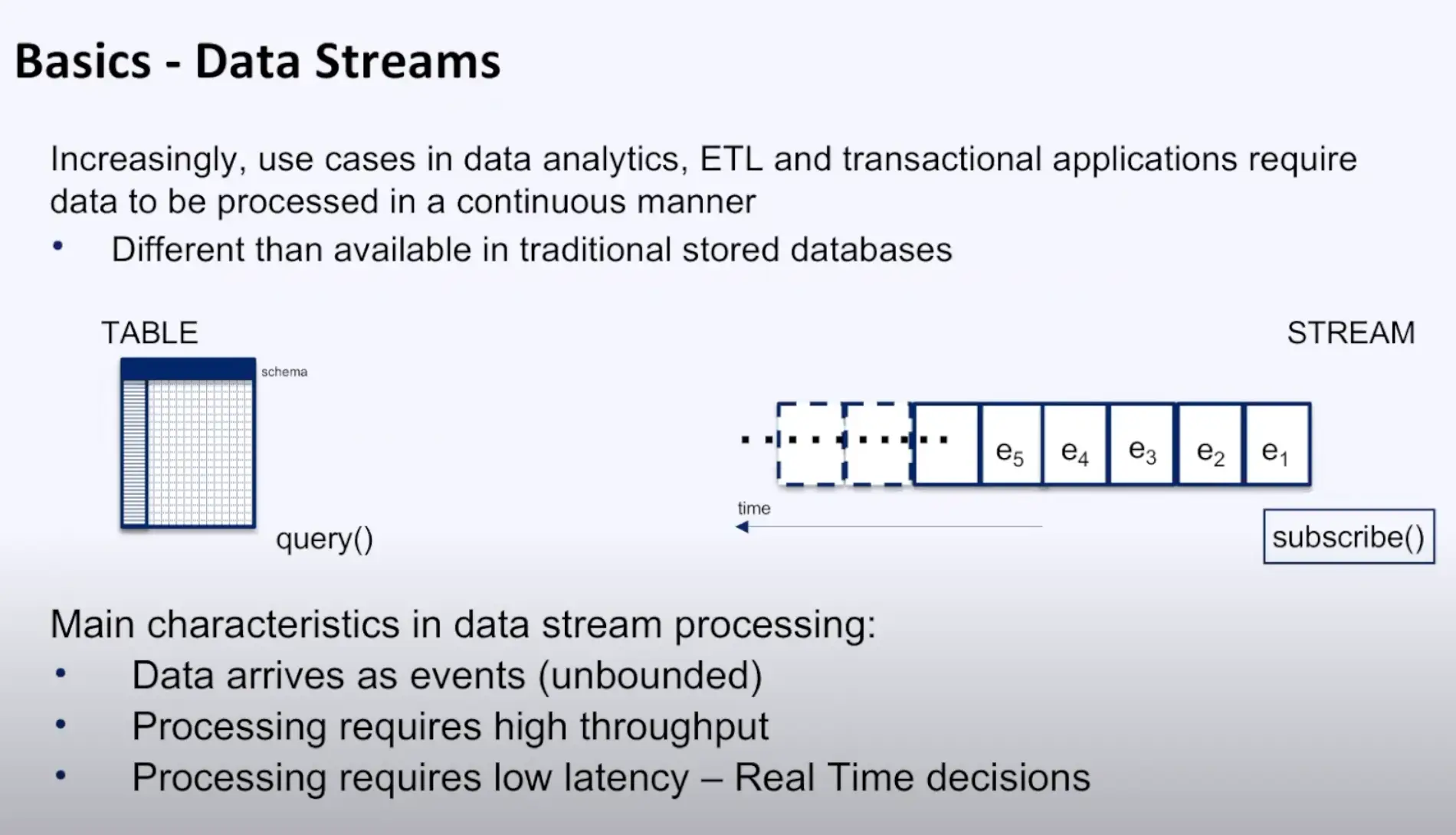
As Alok Pareek mentions in his explanation of stream processing, the main characteristics of data stream processing include:
- Data arrives as an ongoing stream of events
- It requires high-throughput processing
- It requires low-latency processing
Stream processing can be stateless or stateful. The state of the data tells you how previous data affects the processing of current data. In a stateless stream, the processing of current events is independent of the previous ones. Suppose you’re analyzing weblogs, and you need to calculate how many visitors are viewing your page at any moment in time. Since the result of your preceding second doesn’t affect the current second’s outcome, it’s a stateless operation.
With stateful streams, there’s context, as current and preceding events share their state. This context can help past events shape the processing of current events. For instance, a global brand would like to check the number of people buying a specific product every hour. Stateful stream processing can help to process the users who buy the product in real time. This data is then shared in a state, so it can be aggregated after one hour.
Stream Processing vs. Batch Processing
Batch processing is about processing batches containing a large amount of data, which is usually data at rest. Stream processing works with continuous streams of data where there is no start or end point in time for the data. This data is then fed to a streaming analytics tool in real time to generate instant results.
Batch processing requires that the batch data is first loaded into a file system, a database, or any other storage medium before processing can begin. It’s more practical and convenient if there’s no need for real-time analytics. It’s also easier to write code for batch processing. For example, a fitness-based product company goes through its overall revenues generated from multiple stores around the country. If it wants to look at the data at the end of the day, batch processing is good enough to adequately meet its needs.
Stream processing is better when you have to process data in motion and deliver analytics outcomes rapidly. For instance, the fitness company now wants to boost brand interest after airing a commercial. It can use stream processing to feed social media data into an analytics tool for real-time audience insights. This way, it can determine audience response and look into ways to amplify brand messaging in real time.
Is Stream Processing the Same as Complex Event Processing?
Stream processing is sometimes used interchangeably with complex event processing (CEP). Complex event processing is actually a subset of stream processing. It’s a set of techniques and concepts used to process real-time events and extract meaningful information from these event streams on a continuous basis.
CEP is linked to different data sources in an organization, where pre-built triggers are defined for specific events. When these events occur, alerts and automated actions are triggered. For example, in the stock market, when stock price data arrives, the system can match stock data with real-time and historical patterns and automate the decision to buy or sell a stock.
How Does Stream Processing Work?
Modern applications process two types of data: bounded and unbounded. Bounded data refers to a dataset of finite size — one where you can easily count the number of elements in the dataset. It has a known endpoint. For instance, a bookstore wants to know the number of books sold at the end of the day. This data is bounded because a fixed number of books were sold throughout the day and sales operations ended for the day, which means it has a known endpoint.
Unbounded data refers to a dataset that is theoretically infinite in size. No matter how advanced modern information systems are, their hardware has a limited number of resources, especially when it comes to storage capacity and memory. It’s not economical or practical to handle unbounded data with traditional approaches.
Stream processing can use a number of techniques to process unbounded data. It partitions data streams by taking a current fragment so they can become fixed chunks of records that can be analyzed. Based on the use case, this current fragment can be from the last two minutes, the last hour, or even the last 200 events. This fragment is referred to as a window. You can use different techniques to window data and process the windowing outcomes.
Next, data manipulation is applied to data accumulated in a window. This can include the following:
- Basic operations (e.g., filter)
- Aggregate (e.g., sum, min, max)
- Fold/reduce
This way, each window has a result value.
Stream Processing Architecture
A stream processing architecture can include the following components:
- Stream processor: A stream producer (also known as a message broker) uses an API to fetch data from a producer — a data source that emits streams to the stream processor. The processor converts this data into a standard messaging format and streams this output regularly to a consumer.
- Real-time ETL tools: Real-time ETL tools collect data from a stream processor to aggregate, transform, and structure it. These operations ensure that your data can be made ready for analysis.
- Data analytics tool: Data analytics tools help analyze your streaming data after it’s aggregated and structured properly. For instance, if you need to send streaming events to applications without compromising on latency, then you can process and persist your streams into a cluster in Cassandra. You can set up an instance in Apache Kafka to send outputs of streams of changes to your apps for real-time decision making.
- Data storage: You can save your streaming data into a number of storage mediums. This can be a message broker, data warehouse, or data lake. For example, you can store your streaming data on Snowflake, which lets you perform real-time analytics with BI tools and dashboards.
Advantages of Stream Processing
Stream processing isn’t right for every organization. After all, not everyone needs real-time data. But for those who do, stream processing is essential. It makes the entire process of dealing with real-time data much smoother and more efficient. Here are some more benefits you can get from stream processing.
- Easier to deal with continuous streams. With batch processing, you have to stop collecting data at some point and process it. This creates the need for a cycle of accept, aggregate, and process, which can be prohibitively complicated and increase overhead. Stream processing can identify patterns, examine results, and easily show data from several streams at once.
- Can be done with affordable hardware. Batch processing allows data to accumulate and then process it, which might require powerful hardware. Stream processing deals with data as soon as it arrives and doesn’t let it build up, which is why it can be done without the need for costly hardware.
- Deal with large amounts of data. Sometimes, there’s a large amount of data that can’t be stored. In these scenarios, stream processing helps you process data and retain the useful bits.
- Handle the latest data sources. With the rise of IoT, there’s an increase in streaming data, which comes from a wide range of sources. Stream processing’s inherent architecture makes it a natural solution to deal with these sources.
Stream Processing Frameworks
A stream processing framework is a comprehensive processing system that collects streaming data as input via a dataflow pipeline and produces real-time analytics by delivering actionable insights. These frameworks save you from going through the hassle of building a solution to implement stream processing.
Before you get started with a stream processing framework, you need to make sure it can meet your needs. Here’s what you should consider:
- Does the framework support stateful stream processing?
- Does the framework support both batch and stream processing functionalities?
- Does the framework offer support for your developers’ desired programming languages?
- How does the framework fare in terms of scalability?
- How does the framework deal with fault tolerance and crashes?
- How easy is the framework to build upon?
- How quickly can your developers learn to use the framework?
Answering these questions will ensure you end up with a stream processing framework that fulfills all of your needs. You don’t want to pay for new hardware to find it only does half of what you want. The following three frameworks are some of the most popular options available and fulfill each of the criteria above.
Apache Spark
Apache Spark is an analytics engine that’s built to process big data workloads on an enterprise scale. The core Spark API contains Spark Streaming, an extension that supports stream processing data streams at high throughput. It ingests data from a wide range of sources, such as TCP sockets, Kineses, and Kafka.
Spark Streaming collects real-time streams and divides them into batches of data with regular time intervals. A typical interval is between 500 milliseconds to several seconds. Spark Streaming comes with an abstraction known as DStream (Discretized Stream) to represent continuous data streams.
You can use high-level functions like window, join, and reduce to process data with complex algorithms. This data can then be sent to live dashboards, databases, and file systems, where you can use Spark’s graph processing and machine learning algorithms on your streams.
Kafka Streams
Kafka Streams is a Java API that processes and transforms data stored in Kafka topics. You can use it to filter data in a topic and publish it to another. Think of it as a Java-powered toolkit that helps you to modify Kafka messages in real time before they’re sent to external consumers.
A Kafka Stream is made of the following components:
- Source processors: Used for representing a topic in Kafka and can send event data to one or several stream processors.
- Stream processors: Used to perform data transformations, such as mapping, counting, and grouping, on input data streams.
- Sink processors: Used for representing the output streams and are connected to a topic.
- Topology: A graph that the Kafka Streams instance uses to figure out the relationship between sources, processors, and sinks.
Apache Flink
Apache Flink is an open-source distributed framework that offers stream processing for large volumes of data. It provides low latency and high throughput while also supporting horizontal scaling.
DataStream API is the primary API in Flink for stream processing. It helps you write programs in Python, Scala, and Java to perform data transformations on streams. These streams can come from various sources at once, such as files, socket streams, or message queues. The output of these streams is routed through Data Sinks, so you write this data to a target, like distributed files.
Flink doesn’t only offer runtime operators for unbounded data — it also comes with specialized operators to process bounded data by configuring the Table API or DataSet API in Flink. That means you can use Flink for both stream processing and batch analytics.
Streaming SQL
In stream processing, you can’t use normal SQL for writing queries. You can write SQL queries for bounded data that are stored in a database at the moment, but you can’t use these queries for real-time streams. For that, you need a special type of SQL known as Streaming SQL.
Streaming SQL helps you write queries for stored data as well as data that are expected to come in the future. That’s why these queries never stop running and continuously generate results as streams. For instance, if a manufacturing plant is using sensors to record temperature data for its machinery, you can represent this output as a stream. Normal SQL queries will collect stored data from your machinery’s database table, process it, and send it to the target system. Streaming SQL not only ingests stored data but also collects new data from your sensor and continuously produces it as output in real time.
Learn more about streaming SQL in detail here.
Stream Processing Use Cases
The ability of stream processing architectures to analyze real-time data can have a major impact in several areas.
Fraud detection
Stream processing architectures can be pivotal in discovering, alerting, and managing fraudulent activities. They go through time-series data to analyze user behavior and look for suspicious patterns. This data can be ingested through a data ingestion tool (e.g., Striim) and can include the following:
- User identity (e.g., phone number)
- Behavioral patterns (e.g., browsing patterns)
- Location (e.g., shipping address)
- Network and device (e.g., IP information, device model)
This data is then processed and analyzed to find hidden fraud patterns. For example, a retailer can process real-time streams to identify credit card fraud during the point of sale. To do this, it can correlate customers’ interactions with different channels and transactions. In this way, any transaction that’s unusual or inconsistent with a customer’s behavior (e.g., using a shipping address from a different country) can be reviewed instantly.
Hyper-personalization
Accenture found that 91% of buyers are more likely to purchase from brands that offer personalized recommendations. Today, businesses need to improve their customer experience by introducing workflows that automate personalization.
Personalization with batch processing has some limitations. Since it uses historical data, it fails to take advantage of data that provides insights into a user’s real-time interactions that are happening at the very moment. In addition, it fails at hyper-personalization since it’s unable to use these real-time streams with customers’ existing data.
Let’s take a seller that deals in computer hardware. Their target market includes both office workers and gamers. With stream processing, the seller can process real-time data to determine which visitors are office workers who need hardware like printers, and which are gamers who are more likely to be looking for graphic cards that can run the latest games.
Log analysis
Log analysis is one of the processes that engineering teams use to identify bugs by reviewing computer-generated records (also known as logs).
In 2009, PayPal’s network infrastructure faced a technical issue, causing it to go offline for one hour. This downtime led to a loss of transactions worth $7.2 million. In such circumstances, engineering teams don’t have a lot of time; they have to quickly find the root cause of the failure via log analysis. To do this, their methods of collecting, analyzing, and understanding data in real time are key to solving the issue. Stream processing architecture makes it a natural solution. Today, PayPal uses stream processing frameworks and processed 5.34 billion payments in the fourth quarter of 2021.
Stream processing can improve log analysis by collecting raw system logs, classifying their structure, converting them into a consistent and standardized format, and sending them to other systems.
Usually, logs contain basic information like the operation performed, network address, and time. Stream processing can add meaning to this data by identifying log data related to remote/local operations, authentication, and system events. For instance, the original log stores user IP addresses but doesn’t tell their physical location. Stream processing can collect geolocation data to identify their location and add it to your systems.
Sensor data
Sensor-powered devices collect and send large amounts of data quickly, which is valuable to organizations (e.g. for predictive maintenance). They can measure a wide variety of data, such as air quality, electricity, gasses, time of flight, luminance, air pressure, humidity, temperature, and GPS. After this data is collected, it must be transmitted to remote servers where it can be processed. One of the challenges that occurs during this process is the processing of millions of records sent by the device’s sensors every second. You might also need to perform different operations like filtering, aggregating, or discarding irrelevant data.
Stream processing systems can process data from sensors, which includes data integration from different sources, and perform various actions, like normalizing data and aggregating it. To transform this data into meaningful events, it can use a number of techniques, including:
Assessment: Storing all data from sensors isn’t practical since a lot of it isn’t relevant. Stream processing applications can standardize this data after collecting it and perform basic transformations to determine if any further processing is required. Irrelevant data is then discarded, saving processing bandwidth.
Aggregation: Aggregation involves performing a calculation on a set of values to return a single output. For instance, let’s say a handbag company wants to identify fraudulent gift card use by looking over its point-of-sale (POS) machine’s sensor data. It can set a condition that tells it when gift card redemptions cross the $1,000 limit within 15 minutes. It can use stream processing to aggregate metrics continuously by using a sliding time window to look for suspicious patterns. A sliding time window is used to group records from a data stream over a specific period. A sliding window of a length of one minute and a sliding interval of 15 minutes will contain records that arrive in a one-minute window and are evaluated every 15 minutes.
Correlation: With stream processing, you can connect to streams over a specific interval to determine how a series of events occurred. For instance, in our POS example, you can set a rule that condition x is followed by conditions y and z. This rule can include an alert that notifies the management as soon as gift card redemptions in one of the outlets are 300% more than the average of other outlets.
Striim: A Unified Stream Processing and Real-time Data Integration Platform
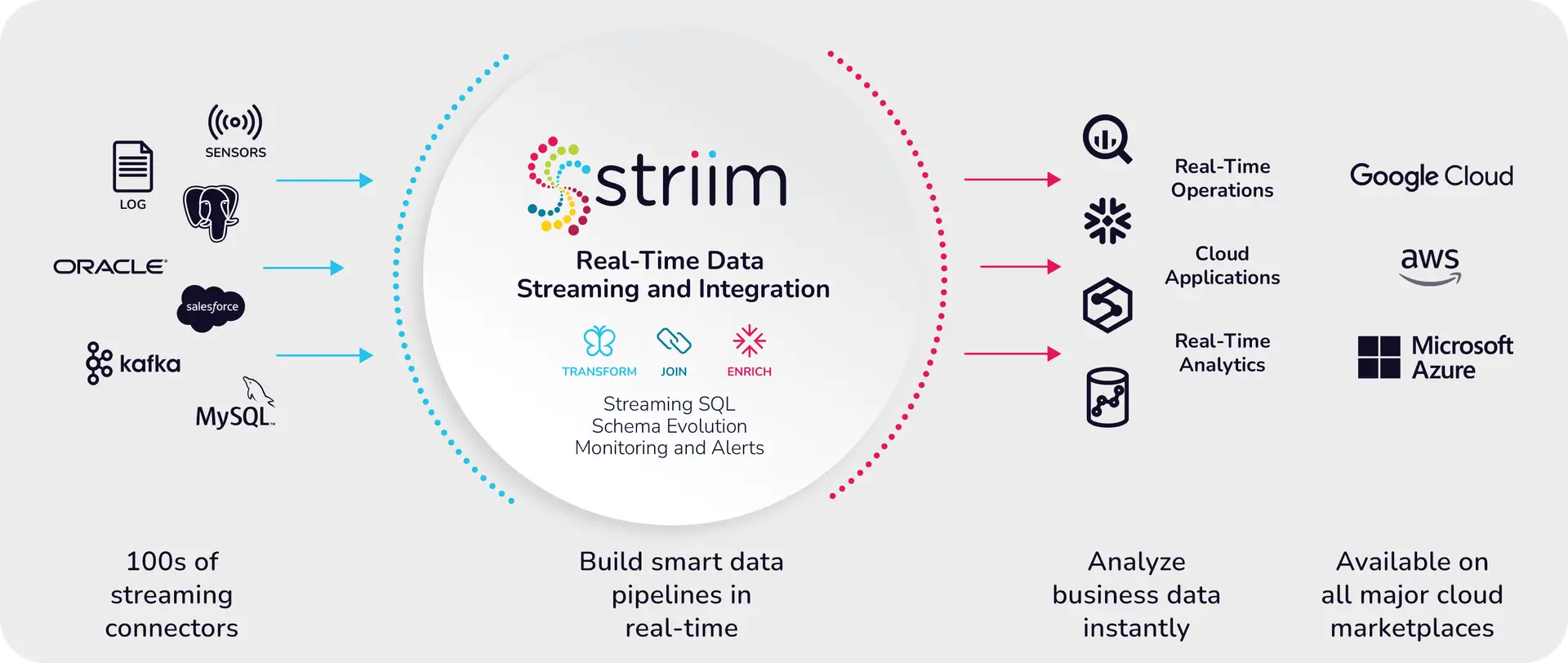
If you’re looking to improve your organization’s processing and management of streaming data, stream processing can be a good solution. However, you need to make sure you have the right tools to effectively implement stream processing. Striim can be your go-to tool for ingesting, processing, and analyzing real-time data streams. As a unified data integration and streaming platform — with over 150 connectors to data sources and targets — Striim brings many capabilities under one roof.
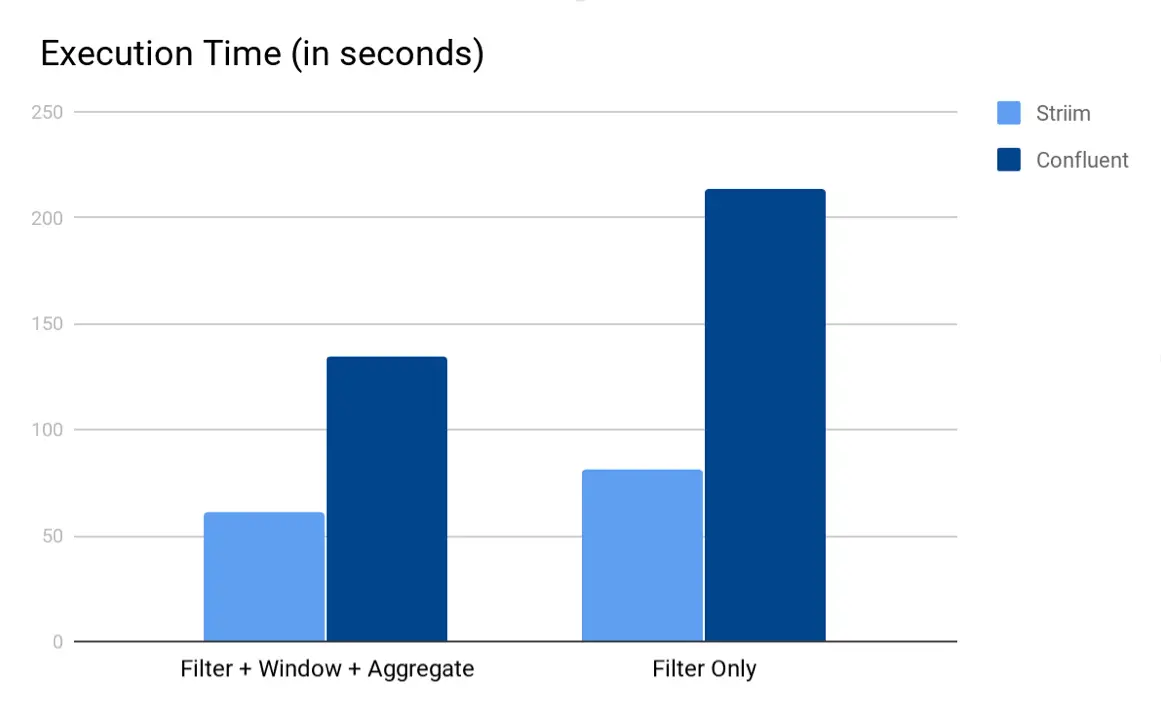
Striim can perform various operations on data streams, such as filtering, masking, aggregation, and transformation. Furthermore, streaming data can be enriched with in-memory, refreshable caches of historical data. WAction Store, a fault-tolerant, distributed results store, maintains an aggregate state. WAction Stores can be continuously queried with Tungsten Query Language (TQL), Striim’s own streaming SQL engine. TQL is 2-3x faster than Kafka’s KSQL and can help you to write queries more efficiently. Streaming data can also be visualized with custom dashboards (e.g., to detect cab-booking hotspots).
Ready to learn more about Striim for real-time data integration and stream processing? Get a product overview, request a personalized demo with one of our product experts, or read our documentation.


