We recently launched Validata, the high-performance data validation platform that verifies consistency between source and target data systems during replication, migrations, analytics operations, and AI workloads.
Now that the solution is available on Google and Microsoft marketplaces, it’s an ideal time to dive deeper into the technical details of the product: why we built it, how it works, and why it’s worth considering for your enterprise data validation, rather than a DIY script or legacy tooling.
Validata Foundations aims to do exactly that. We’ll go under the hood with Validata, take a look at what makes it a leading platform for dataset equivalence today, and expose some of our thought processes behind the engineering choices we made when designing this product.
Let’s get started.
The Problem with DIY Data Validation
Most of your DIY ‘data quality’ or ‘data validation’ scripts or tools are, in reality, guess-and-check dashboards powered by engines that deliver approximately correct answers.
With these complicated scripts, you might get a UI that shows counts, percentages, trends, and even a few sample diffs. You could compare row counts and assume matching numbers mean correct data. Your scripts might hash a subset of columns and assume that unchanged hashes mean unchanged rows. They ignore duplicates, null keys, or append-mode artifacts because they’re inconvenient.
None of this is wrong. It’s just not data validation. Your DIY scripts perform well when the two schemas being compared are homogeneous, data volumes are modest, and when write behaviors are simple. They fail quietly the moment those assumptions collapse.
Why We Built Validata
Validata was built in direct response to the failures of DIY data validation scripts or legacy tools. We built Validata not for data quality scoring or anomaly detection, but to check strict dataset equivalence: the problem of determining whether two independently changing datasets represent the same truth based on clearly defined comparison rules.
We make those comparison rules narrow and unforgiving. With Validata, you don’t judge whether the data makes sense; you only check whether it matches. Validata asks whether two changing datasets are identical under a declared set of rules across different storage engines, data types, replication modes, and timing.
Deterministic by Design
This rigor only works if the system behaves predictably. That’s why we built Validata to be deterministic. What does ‘deterministic’ mean? Each validation run is bound to a specific configuration snapshot. When you create a validation, we lock core attributes such as source and target definitions, table mappings, comparison keys, validation scope, and validation method.
The core attributes do not change for that particular validation run. Every validation run is traceable back to that exact configuration, and historical reports do not change retroactively when the validation is later edited. This isn’t just a workflow choice; it’s what makes the results of a true data validation trustworthy. Therefore, with Validata, validation results can be trusted and audited over time.
Datasets As Objects, Not Pipelines
Determinism alone isn’t enough if results aren’t actionable. That’s why we built Validata to operate on datasets as objects, not as pipelines. With Validata, you only evaluate the state of datasets as they exist at query time, and you can use it in conjunction with your preferred replication tool. Let’s say you run a script that validates the equivalence of two data systems. And let’s say the validation fails. As an engineer, you think:
- Which table is broken?
- Which source-target table pair is out-of-sync?
- What exactly is wrong with the rows in those tables?
How Validata Compares Data
In order to address this, Validata’s object model is deliberate: we’ve structured everything around concrete objects such as tables, table pairs and rows, rather than vague job-level summaries, which we’ve seen in legacy tools and DIY scripts.
This is for three reasons. Firstly, it matches the mental model of failure that you, as an engineer, would use. When a report flags a specific table pair, it maps directly to the fix. There’s no translation layer between the result and the action.
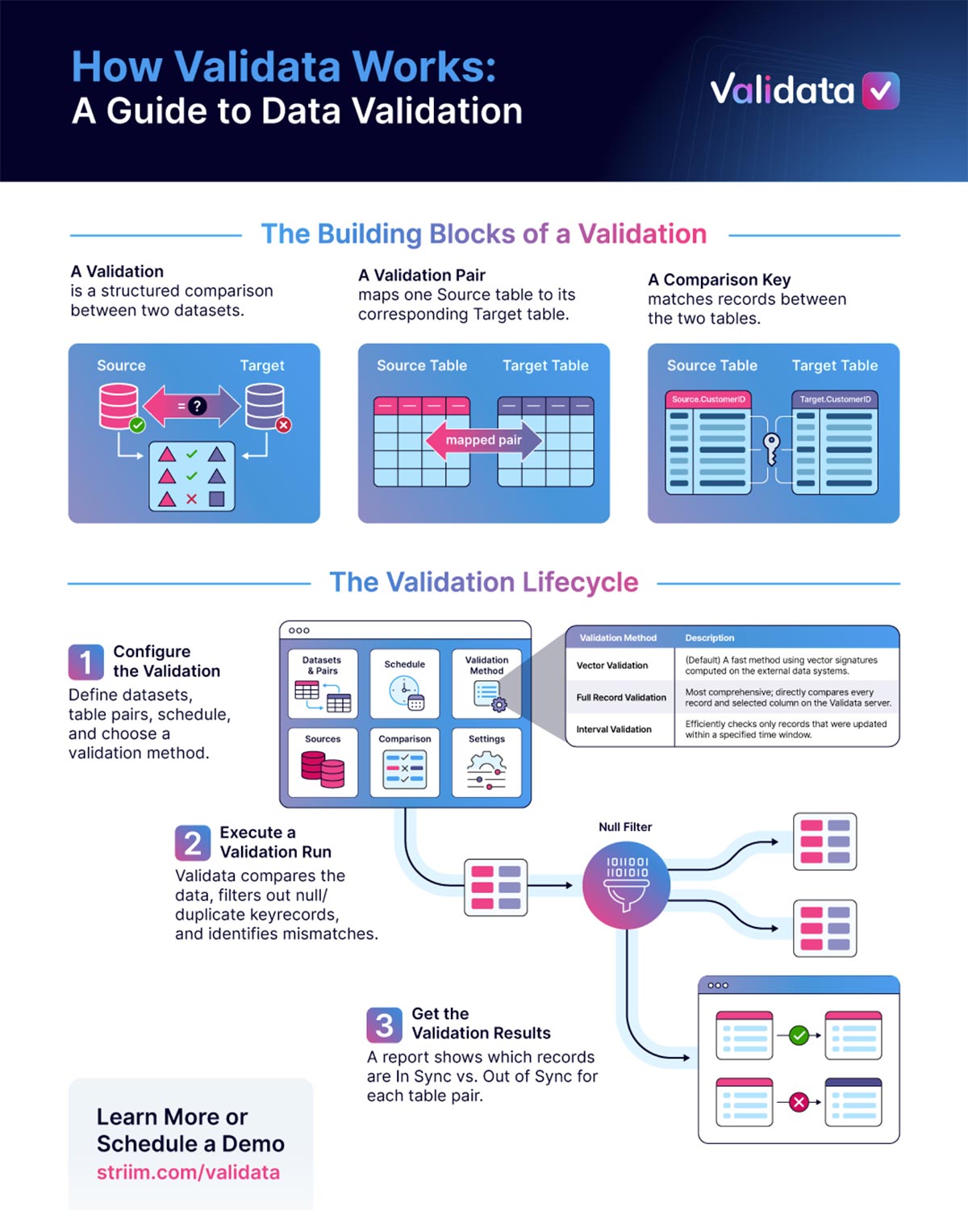
Secondly, that same model allows Validata to scale without losing clarity. As validations grow to hundreds or thousands of datasets, results stay readable. You can see what’s healthy, isolate what’s broken, and track patterns over time per dataset, instead of relying on global metrics that hide real issues.
And lastly, the same principle applies to reconciliation. Because every discrepancy is tied to a specific object, Validata generates SQL fixes that apply only to the affected tables and records. There are no system-wide cleanup scripts or risky assumptions, just precise corrections to the specific problem tables, rows, columns.
This reflects a core boundary: pipelines move data; Validata optimally evaluates truth at rest while the data is in motion.
Exact Row Matching
Every comparison in Validata begins with matching rows precisely across datasets and data systems. We treat this as a mathematical problem.
With Validata, you specify a specific comparison key, which may be a single column or a composite of multiple columns. regardless of whether the underlying data system enforces primary key constraints. Before any comparison occurs, we apply two strict filters.
We exclude rows with null values in any key column because nulls break rules-based and precise matching. Rows with duplicate keys are highlighted on both sides to eliminate any ambiguous matches. Validata refuses to compare records that it cannot pair one-to-one with certainty.
Six Validation Methods
Once the comparable dataset is defined, Validata runs a logical comparison that is identical across any of six different validation methods. Here’s a brief breakdown of the different approaches.
- Vector validation: computes compact signatures within the source and target systems, comparing only those signatures on the Validata server to minimize data movement at massive scale.
- Fast record validation: retrieves comparison keys and record hashes to the Validata server, balancing load while retaining detailed mismatch detection.
- Full record validation: compares all selected data record by record for maximum fidelity.
- Key validation: checks only row presence across source and target, without comparing content.
- Interval validation: applies time-based predicates to validate only data that changed within defined time windows.
- Custom validation: lets you write your own SQL when the built-in methods don’t cover your use case.
Data is ingested, normalized using precise datatype rules, aligned by key, and evaluated record by record. In Validata, we classify each row clearly as in-sync, content mismatch, extra at source, or extra at target. We compare every record or explicitly exclude it, and all metrics reconcile exactly. There is no sampling and no silent loss.
In Validata, what varies between validation methods is execution, not correctness.
Handling Append-Only Replication
Some data topologies for analytical workloads require even more explicit handling. In Validata, we treat the Append-only design pattern as a different universe.
We know that there are data systems such as data warehouses and data lakes, where updates generate new rows instead of updating existing ones. This is because systems use different timestamps, sequence numbers and rules for strings or numbers.
In these scenarios, guessing which row is ‘latest’ could be dangerous. With Validata, you have six built-in validation methods that intentionally exclude duplicates to preserve exact row matching. As a result, the built-in methods cannot validate append-mode targets directly. In the case of append-only scenarios, Validata doesn’t guess what you meant or which records are the latest.
You define the latest state explicitly with SQL that you provide, and Validata compares those results just like any other validation. This explicitness preserves exact correctness.
Built-In Safeguards
Revalidation
In Validata, time is handled explicitly. Validata assumes some mismatches are caused by replication delay, not real errors. After a user-defined interval that’s chosen based on propagation latency expectations , Validata minimally reruns the comparison only on rows that were previously out of sync. This is called revalidation. This separates temporary replication delays from real data problems without hiding either. Revalidation is limited, explicit, precise, and rule-based
Early Halting
To avoid wasted effort, Validata can halt a validation early when mismatch rates exceed defined thresholds after enough data has been processed. Halting isn’t a failure; it’s a successful outcome that signals further processing would add cost without insight. This protects both compute resources and the integrity of the metadata store.
Datatype Normalization
We know that heterogeneous systems introduce datatype mismatches. In a heterogeneous world, you need datatype normalization, so Validata applies clear, documented normalization rules.
In Validata, we align numeric values by scale or precision using defined limits, and compare floating-point values using a capped scientific notation. Strings are either trimmed or compared exactly, depending on how they are stored.
We convert dates, times, and timestamps into standard forms, with timezone handling applied only when it is safe on both sides. Boolean values are mapped into consistent representations.
When safe normalization isn’t possible, we compare literal strings in Validata, instead of guessing. You get predictable results every time with Validata’s built-in datatype normalization.
Historian and Reconciliation
All of this metadata is preserved in the Validata Historian. The Validata Historian stores all validation metadata, including configurations, run reports, metrics, reconciliation scripts, and audit logs.
We have designed it to support encryption, immutability, replayability, and time-series analysis of data consistency across environments. In large deployments, you can use enterprise databases for Historian, to avoid storage limits.
Reconciliation from Exact Comparison
Reconciliation in Validata comes from exact comparison, not guesswork. When enabled, Validata generates explicit SQL statements to insert missing rows, update mismatched rows, or remove extraneous rows on the target. These reconciliation scripts are precise, limited to validated keys, and never run automatically. Validata does not fix data; it tells you exactly what needs to change to restore equivalence between the datasets. We have plans to be topology aware and automate reconciliation.
Why Strictness Matters
All of this makes Validata intentionally strict. It excludes data instead of guessing, and stops runs instead of producing misleading results. It requires you to explicitly handle append-only data, surface duplicate keys rather than hiding them, and preserve historical truth even as configurations evolve.
That friction is deliberate. It’s the cost of correctness in data environments where silent failure is far more dangerous than visible constraints.
Data validation isn’t about reassurance. It’s about proof. In a world with AI applications relying on data across distributed systems, heterogeneous storage engines, and continuously changing data, anything less than exact comparison is just optimism dressed up as ‘data quality’ tooling.
Validata takes the more difficult path on purpose. It defines the rules explicitly, applies them precisely, refuses to guess when reality is ambiguous, and preserves every result as an auditable fact. That makes it stricter than most tools, and far more useful.
We built Validata not for data quality scoring or anomaly detection, but to check strict dataset equivalence: the problem of determining whether two independently changing datasets represent the same truth based on clearly defined comparison rules.
When data actually matters, a data validation system must earn your confidence, not make guesses. Validata exists for the moments when you don’t want a dashboard telling you things look approximately fine. You want to know, with certainty, that they are.
Ready to replace your DIY scripts with auditable, deterministic data validation? See Validata in action, request a demo today or try it for yourself.


