










Overview
This is the first in a two-part blog post discussing how to use Striim for streaming database changes to Apache Kafka. Striim offers continuous data ingestion from databases and other sources in real time; transformation and enrichment using Streaming SQL; delivery of data to multiple targets in the cloud or on-premise; and visualization of results. In this part, we will use Striim’s low-impact, real-time change data capture (CDC) feature to stream database changes (inserts, updates, and deletes) from an operational database into Striim.
What is Change Data Capture
Databases maintain change logs that record all changes made to the database contents and metadata. These change logs can be used for database recovery in the event of a crash, and also for replication or integration.
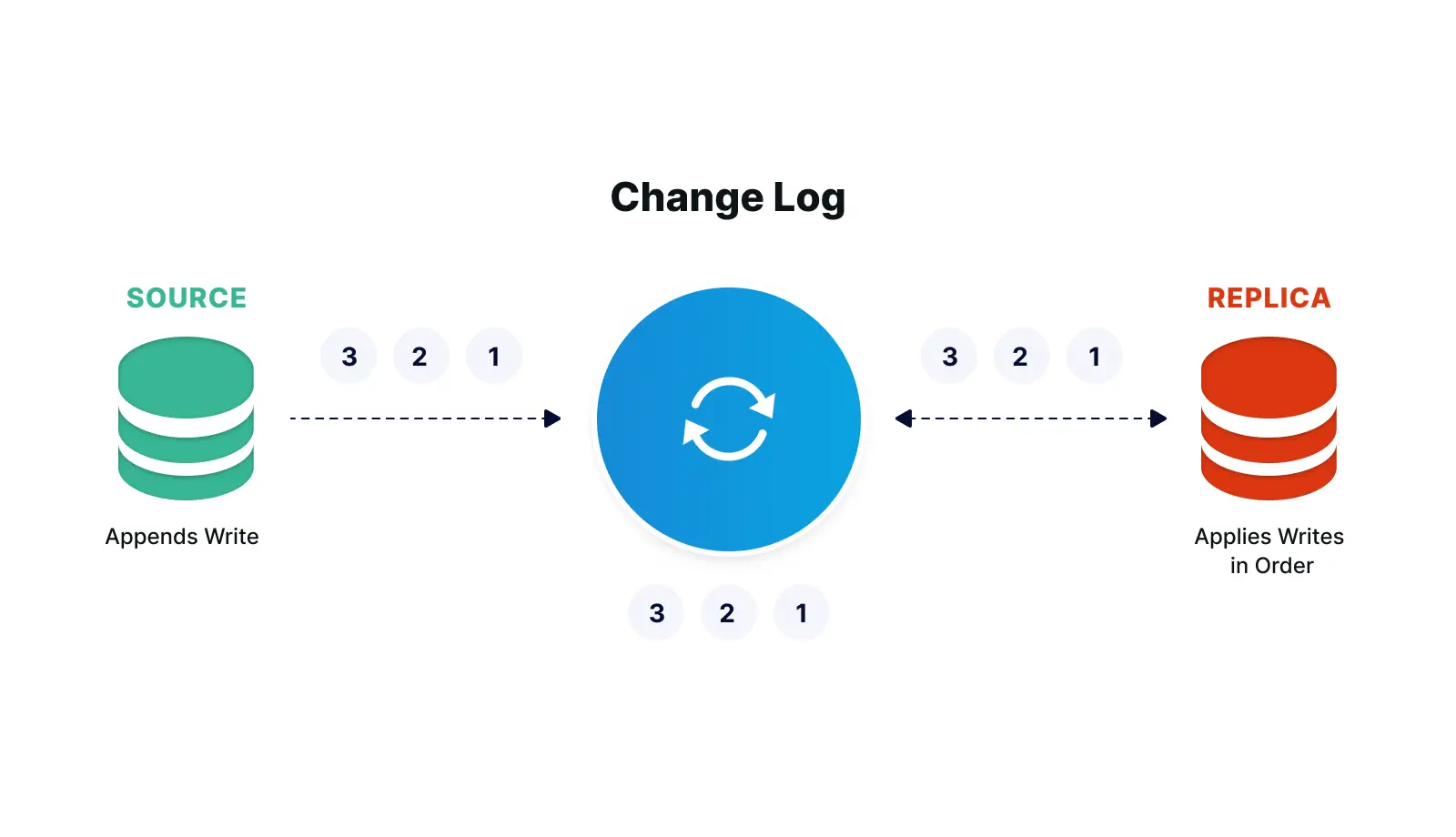
With Striim’s log-based CDC, new database transactions – including inserts, updates, and deletes – are read from source databases’ change logs and turned into a stream of events without impacting the database workload. Striim offers CDC for Oracle, SQL Server, HPE NonStop, MySQL, PostgreSQL, MongoDB, and MariaDB.
Why use Striim’s CDC?
Businesses use Striim’s CDC capabilities to feed real-time data to their big data lakes, cloud databases, and enterprise messaging systems, such as Kafka, for timely operational decision making. They also migrate from on-premises databases to cloud environments without downtime and keep cloud-based analytics environments up-to-date with on-premises databases using CDC.
How to use Striim’s CDC?
Striim’s easy-to-use CDC template wizards automate the creation of applications that leverage change data capture, to stream events as they are created, from various source systems to various targets. Apps created with templates may be modified using Flow Designer or by exporting TQL, editing it, and importing the modified TQL. Striim has templates for many source-target combinations.
In addition, Striim offers pre-built integration applications for bulk loading and CDC from PostgreSQL source databases to target systems including PostgreSQL database, Kafka, and files. You can start these applications in seconds by going to the Applications section of the Striim platform.
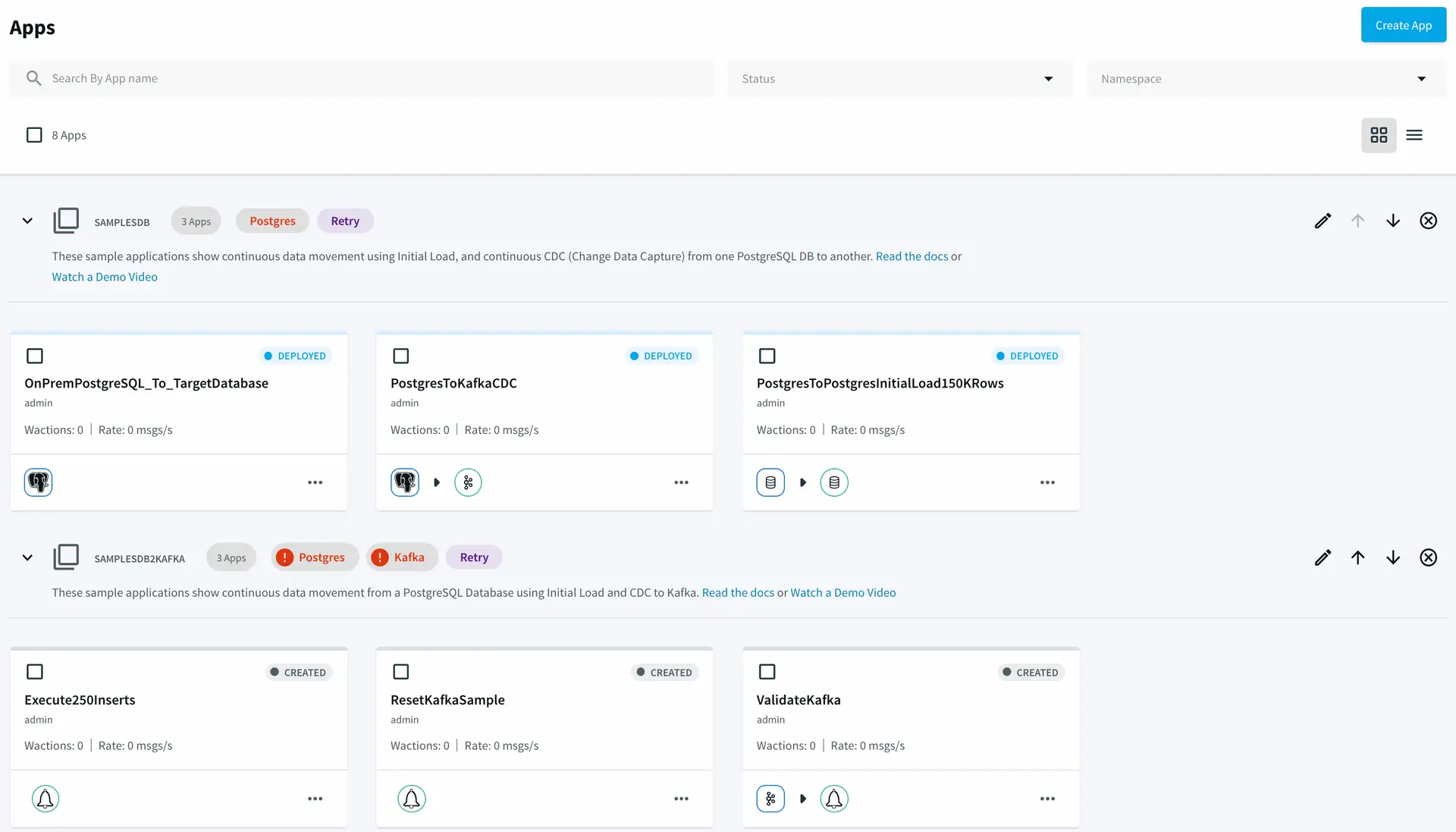
Striim pre-built sample integration applications.
In this post, we will show how to use the PostgreSQL CDC (PostgreSQL Reader) with a Striim Target using the wizards for a custom application instead of using the pre-built application mentioned above. The instructions below assume that you are using the PostgreSQL instance that comes with the Striim platform. If you are using your own PostgreSQL database instance, please review our instructions on how to set up PostgreSQL for CDC.
Step 1: Using the CDC Template
To start building the CDC application, in the Striim web UI, go to the Apps page and select Add App > Start with Template. Enter PostgreSQL in the search field to narrow down the sources and select “PostgreSQL Reader to Striim”.
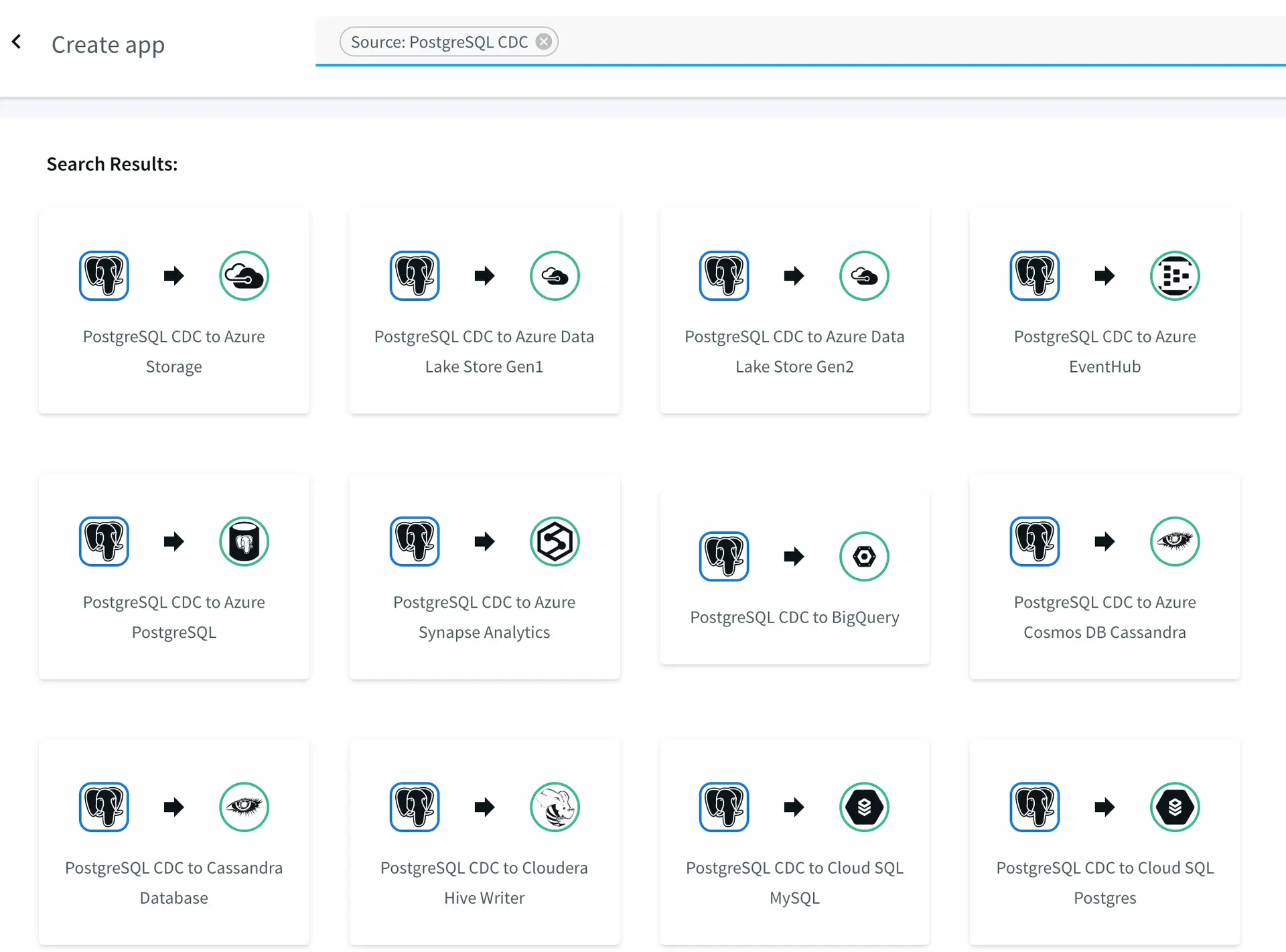
Wizard template selection when creating a new app.
Next enter the name and namespace for your application (the namespace is a way of grouping applications together).
Step 2: Specifying the Data Source Properties
In the SETUP POSTGRESQL READER specify the data source and table properties:
- the connection URL, username, and password.
-
the tables for which you want to read change data.

Configuring the data source in the wizard.
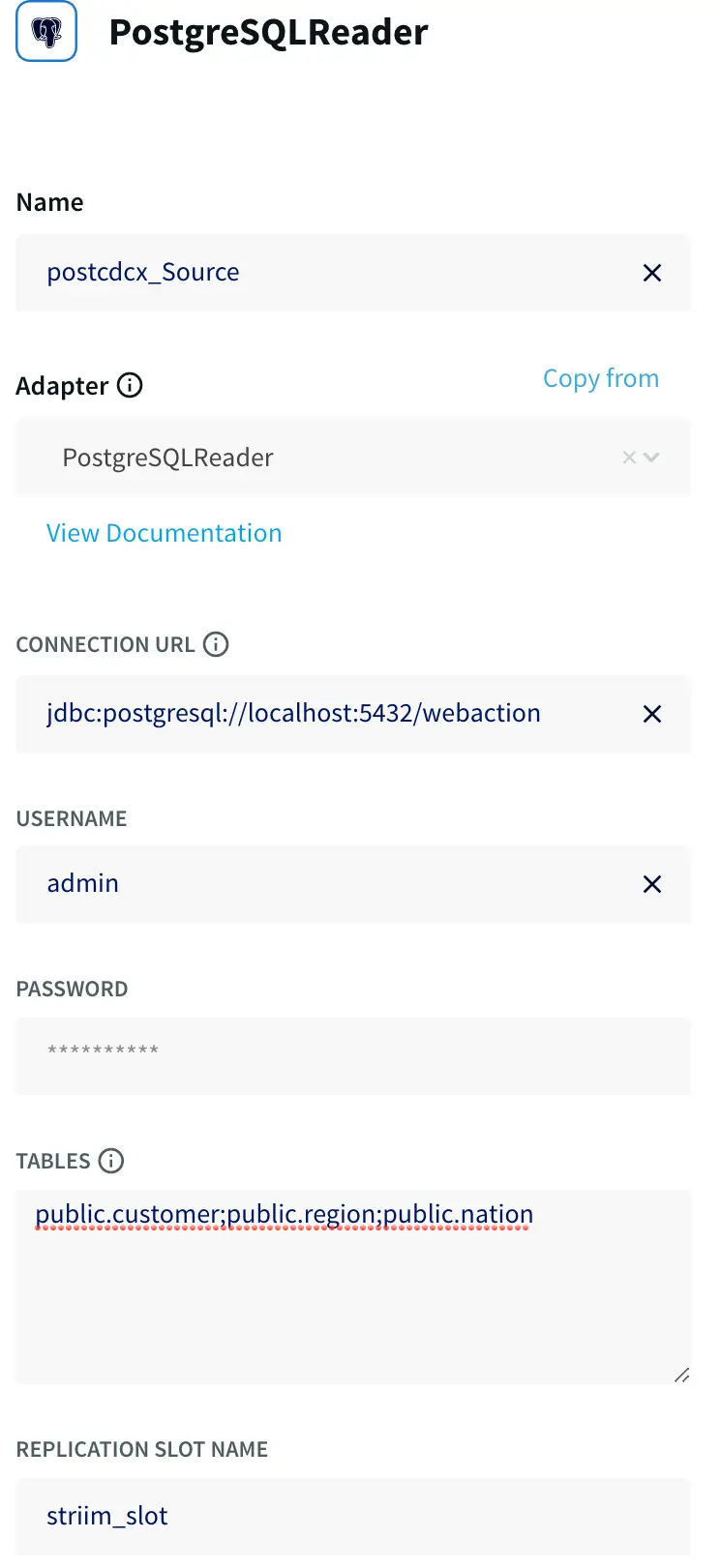
After you complete this step, your application will open in the Flow Designer.
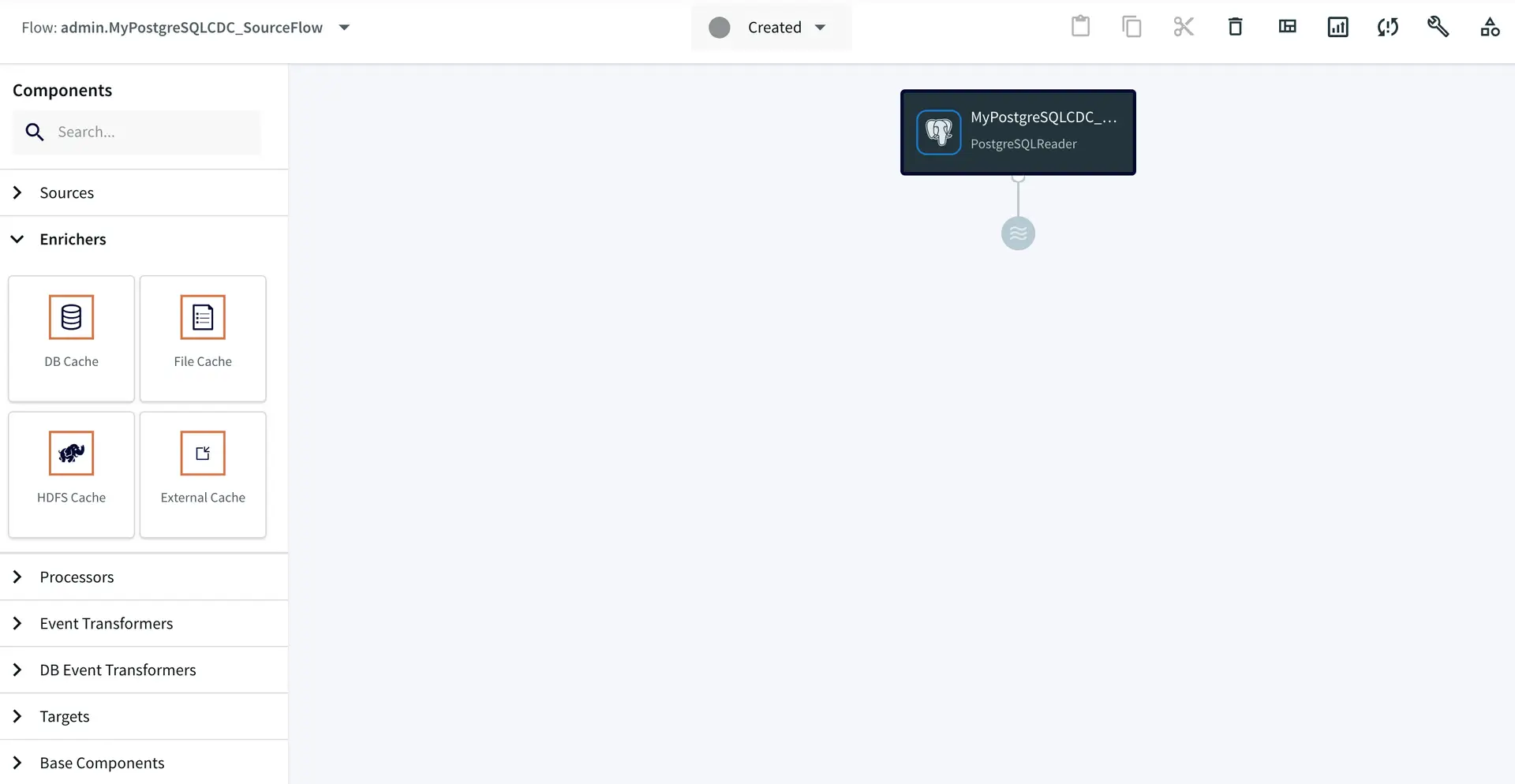
The wizard generates a data flow.
In the flow designer, you can add various processors, enrichers, transformers, and targets as shown below to complete your pipeline, in some cases with zero coding.

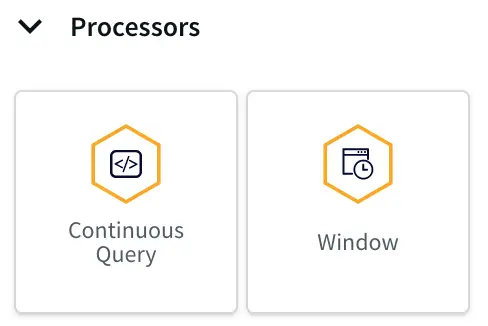
Flow designer enrichers and processors.
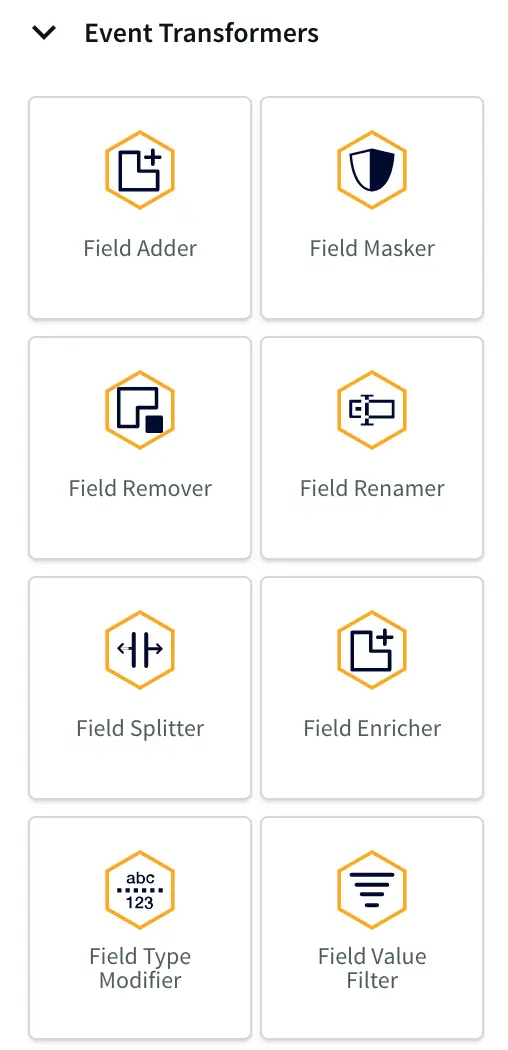

Flow designer event transformers and targets.
In the next blog post, we will discuss how to add a Kafka target to this data pipeline. In the meantime, please feel free to request a demo with one of our lead technologists, tailored to your environment.

Striim
Striim’s unified data integration and streaming platform connects clouds, data and applications.
PostgreSQL
PostgreSQL is an open-source relational database management system.
