warehouses allow businesses to find insights by storing and analyzing huge amounts of . Over the last few years, Snowflake, a -native relational , has gained significant adoption across organizations for real-time .
In this post, we’ll share an overview of real-time with Snowflake, some challenges with real-time in Snowflake, and how Striim addresses these challenges and enables users to optimize their costs.
Continuous Pipelines and Real-Time A With Snowflake: Architecture and Costs
Snowflake’s flexible and scalable architecture allows users to manage their costs by independently controlling three functions: , , and . Consumption of Snowflake resources (e.g. loading into a and executing queries) is billed in the form of credits. is billed at a flat-rate based on TB used/month. and credits can be purchased on demand or up front (capacity).
In 2017, Snowflake introduced the Snowpipe loading service to allow Snowflake users to continuously ingest . This feature, together with Snowflake Streams and Tasks, allows users to create continuous pipelines. As shown below, Snowpipe loads from an external stage (e.g., AmazonS3). When enters the external staging area, an event is generated to request by Snowpipe. Snowpipe then copies files into a queue before loading them into an internal staging table(s). Snowflake Streams continuously record subsequent changes to the ingested (for example, INSERTS or UPDATES), and Tasks automate SQL queries that transform and prepare for analysis.

While Snowpipe is ideal for many uses cases, continuous ingestion of large volumes of can present challenges including:
- Latency: On average, once a file notification is sent, Snowpipe loads incoming after a minute. But when it comes to larger files, loading takes more time. Similarly, if your project requires an excessive amount of resources for performing decompression, description, and transformation on the fresh , with Snowpipe will take longer.
- : The utilization costs of Snowpipe include an overhead for managing files in the internal load queue. With more files queued for loading, this overhead will continue to increase over time. For every 1,000 files queued, you have to pay for 0.06 credits. For example, if your application loads 100,000 files into Snowflake daily, Snowpipe will charge you six credits.
Real-time With Striim and Snowflake: An Overview
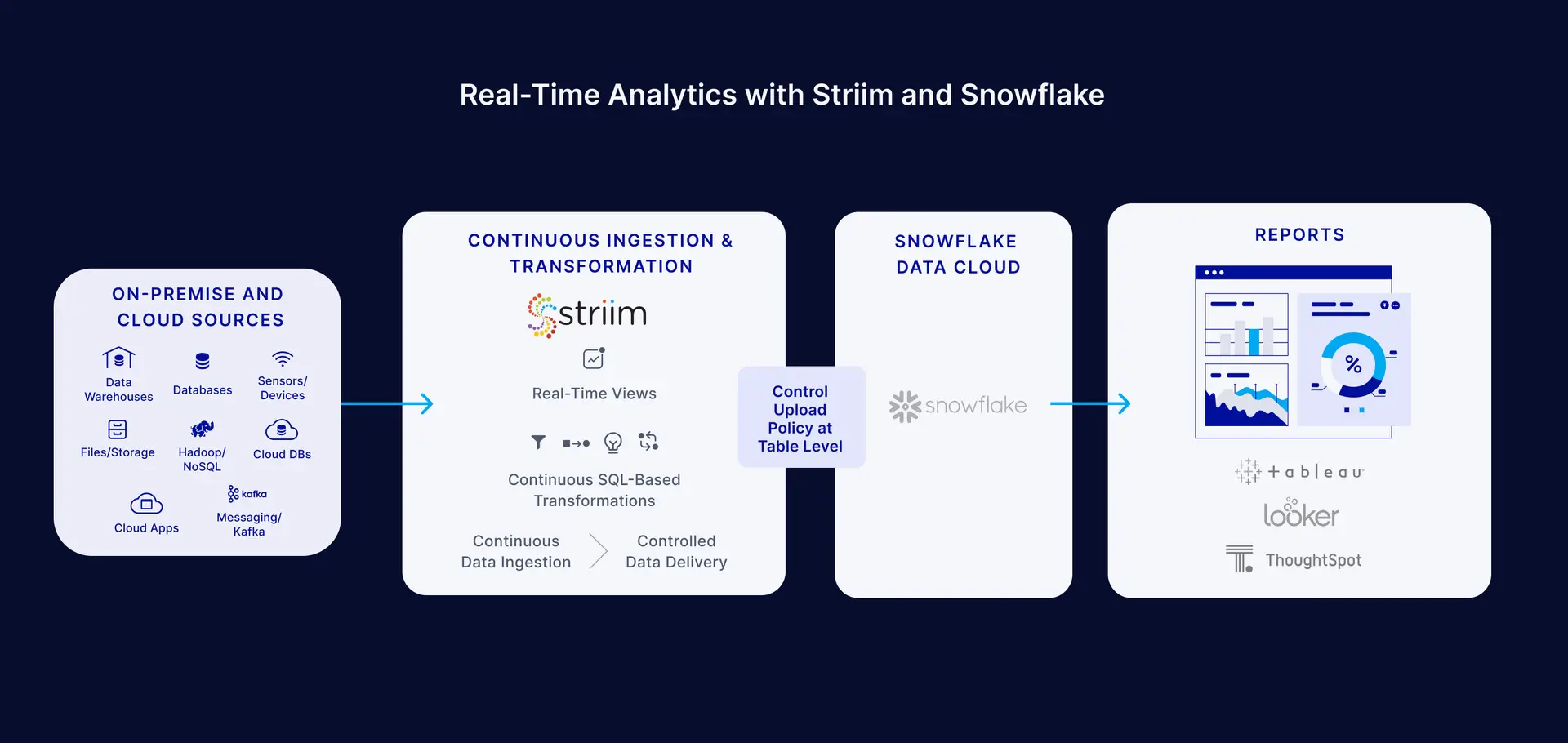
With growing workloads, you can reduce costs incurred during real-time analytics by integrating Striim with Snowflake. Striim is an end-to-end data integration platform that enables enterprises to derive quick insights from high-velocity and high-volume data. Striim combines real-time data integration, streaming analytics and live data visualization, in a single platform.
Some benefits of using Striim for real-time analytics include:
- Support for all types of data, including structured, unstructured, and semi-structured data from on-premise and cloud sources. High-performance change data capture from databases
- In-memory, high-speed streaming SQL queries for in-flight transformation, filtering, enrichment, correlation, aggregation, and analysis. Live dashboards and visualizations
- A customizable Snowflake Writer that gives users granular control over how data is uploaded to Snowflake
Next, we’ll share two examples demonstrating how Striim can support real-time analytics use cases while helping you optimize your Snowflake costs.
Optimize Snowflake Costs With Striim: Examples
Earlier, we discussed the latency and cost considerations for continuous ingestion with Snowpipe. Striim lets you minimize these costs via an “Upload Policy” that allows you to set parameters that control the upload to Snowflake. These parameters allow the Snowflake Writer, which writes to one or more tables in Snowflake, to consolidate the multiple input events of individual tables and perform operations on these groups of events with greater efficiency. You can control the number of events and set interval and file sizes. Unlike other tools that limit you to these settings at the global level, Striim goes one step further by allowing these configurations at the table level.
These events are staged to AWS S3, Azure Storage, or local storage, after which they are written to Snowflake. You can configure the Snowflake Writer in Striim to collect all the incoming events, batch them locally as a temp file, upload them to a stage table, and finally merge them with your final Snowflake table. Here’s what an example workflow would look like:
Oracle Reader → Stream → Snowflake Writer ( Batch→ temp file → Triggers upload to cloud storage → Stage → Merge)
Example 1: Choose how to batch your data to meet your SLAs
The Snowflake Writer’s “Upload Policy” allows you to batch data at varying frequencies based on your company’s data freshness service level agreement (SLA). Data freshness is the latency between data origination and its availability in the warehouse. For example, data freshness can measure the time it takes for data to move from your sales CRM into your Snowflake warehouse. A data freshness SLA is a commitment that guarantees moving data within a specific period.
Let’s take a look at the following diagram to review how Striim manages data freshness SLAs. If you have a large data warehouse, then you often need critical data views (e.g., customer data) and reports. With a 5-minute data freshness SLA, you can ensure that this data loads into your data warehouse five minutes after it’s generated in its data source (e.g., ERP system). However, for other use cases, such as reports, you don’t necessarily need data immediately. Hence, you can settle with a 30-minute data freshness SLA. Depending on how fast you need data, Striim uses fast or medium/low SLA tables to deliver data via its SnowflakeWriter.

While other tools have a sync frequency, Striim has come up with an innovative way of handling data freshness SLAs. For instance, if 50% of your tables can be reported with a one-hour data freshness SLA, 35% with a 30-minute SLA, and 15% with a five-minute SLA, you can split up these tables. This way, you can use Striim to optimize the cost of ingesting your data.
In addition to giving you granular control over the upload process, Striim enables you to perform in-flight, real-time analysis of your data before it’s uploaded to Snowflake. Striim is horizontally scalable, so there are no limitations if you need to analyze large volumes of data in real time. So, even if you choose to batch your data for Snowflake, you can still analyze it in real time in Striim.
Example 2: Reduce costs by triggering uploads based on a given time interval
As mentioned previously, the Snowflake Writer’s “Upload Policy” governs how and when the upload to Snowflake is triggered. Two of the parameters that control the upload are “EventCount”and “Interval”. So, which one of these two parameters yields lower latencies and costs? In most cases using the “Interval” parameter is a better option; here’s an example to show why.
Assume that a system is producing 100k events a minute. Setting an “UploadPolicy = EventCount:10000” would instruct Snowflake Writer to work on 10 upload, merge tasks (100,000/10,000). Assume that each upload, merge takes one minute to complete. So it will take at least 10 minutes to process all 100k events. At the end of the fifth minute, the source would have pumped another 500k events, and Snowflake Writer will be processing another 40 upload, merge tasks (400,000/10,000). In this configuration, you could see the lag increase over time.
If you go with the “Interval” approach, you would get better results. Assume the value of “UploadPolicy = Interval:5m” would instruct the Snowflake Writer to upload, merge tasks every five minutes. It means that every five minutes, Snowflake Writer would receive 500,000 events from the source and process upload, merge in two minutes (assumption). You could see a constant latency of seven minutes (five-minute interval + two-minute upload, merge time) across all the batches.
Cost is another advantage of the “Interval” based approach. In the “EventCount” based approach, you are keeping the Snowflake virtual warehouses always active. For the “EventCount” based approach, Snowflake Writer is active for the entire five minutes as opposed to two minutes for the “Interval” based approach. Therefore, this approach can help you optimize your Snowflake costs.
Go Through Striim Documentation to Improve Your Data-Centric Operations
If you’d like to optimize your other data-related workloads, Striim’s documentation shows some of the things that you can do.
- Go through the Web UI Guide to learn about Striim’s browser-based user interface.
- Go through the Dashboard Guide to build and edit dashboards and visualizations.
- Go through the Programmer’s Guide to create and edit Striim applications.
Want a customized walkthrough of the Striim platform and its real-time integration and analytics capabilities? Request a demo with one of our platform experts, or alternatively, try Striim for free.


