For years, enterprises relied on batch pipelines to move data from operational databases to analytical platforms overnight. That pace was sufficient for past use cases, but it can no longer keep up with real-time business demands. When your fraud detection models or personalized recommendation engines run on data that is six hours old, you’re just documenting the past, not predicting future outcomes.
To bring AI initiatives into production and make data truly useful, enterprises need continuous, reliable replication pipelines. Without them, data risks becoming stale, fragmented, and inconsistent, ultimately undermining the very AI and ML models Databricks was built to accelerate.
In this guide, we’ll explore what it takes to effectively replicate data into Databricks at scale. We’ll cover the modern approaches that are replacing legacy ETL, the challenges you can expect as you scale, and the best practices for ensuring your Databricks environment is fueled by fresh, trusted, and governed data.
Key Takeaways
- Real-time data is a prerequisite for AI: Real-time data replication is crucial for maximizing your Databricks investment. Stale data directly undermines model accuracy and business outcomes.
- Streaming beats batch for freshness: Change Data Capture (CDC)-based streaming replication offers significant advantages over traditional batch ETL for environments that require continuous, low-latency data.
- Enterprise-grade solutions are mandatory at scale: Modern replication platforms must address critical operational challenges like schema drift, security compliance, and hybrid/multi-cloud complexity.
- Optimization and governance matter: When selecting a replication strategy, prioritize Delta Lake optimization, robust pipeline monitoring, and built-in governance capabilities.
- Purpose-built platforms bridge the gap: Solutions like Striim provide the real-time capabilities, mission-critical reliability, and enterprise features needed to power Databricks pipelines securely and efficiently.
What is Data Replication for Databricks?
Data replication in the most basic sense is simply copying data from one system to another. But in the context of the Databricks Lakehouse, replication means something much more specific. It refers to the process of continuously capturing data from diverse operational sources—legacy databases, SaaS applications, messaging queues, and on-premise systems—and delivering it securely into Delta Lake.
Modern replication for Databricks isn’t just about moving bytes; it’s about ensuring data consistency, freshness, and reliability across complex hybrid and multi-cloud environments.
A true enterprise replication strategy accounts for the realities of modern data architectures. It handles automated schema evolution, ensuring that when an upstream operational database changes its schema, your Databricks pipeline adapts gracefully instead of breaking. It also optimizes the data in flight, formatting it perfectly for Delta Lake so it is immediately ready for both batch analytics and streaming AI workloads.
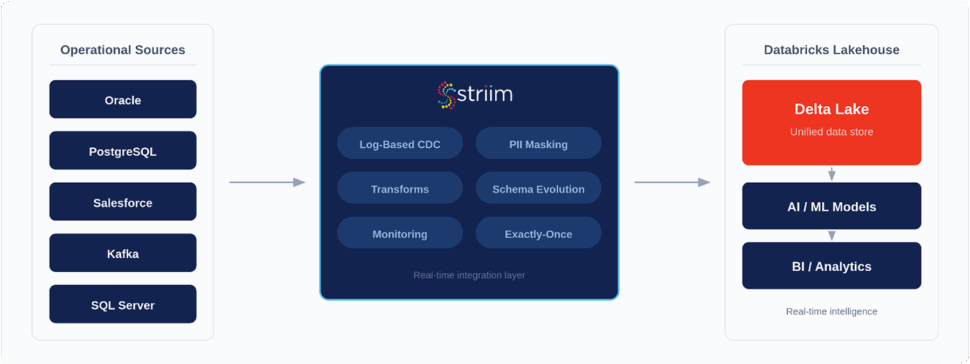
Key Use Cases for Data Replication into Databricks
Data replication should never be viewed simply as a “back-office IT task.” It is the circulatory system of your data strategy. When replication pipelines break or introduce high latency, the stakes are incredibly high: models fail, dashboards mislead, compliance is jeopardized, and revenue is lost.
Understanding your specific use case is the first step in determining the type of replication architecture you need.
Use Case |
Business Impact |
Why Replication Matters |
| AI & Machine Learning | Higher predictive accuracy, automated decision-making. | Models degrade quickly without fresh data. Replication feeds continuous, high-quality context to production AI. |
| Operational Analytics | Faster time-to-insight, improved customer experiences. | Ensures dashboards reflect current reality, allowing teams to act on supply chain or inventory issues instantly. |
| Cloud Modernization | Reduced infrastructure costs, increased agility. | Bridges legacy systems with Databricks, allowing for phased migrations without disrupting business operations. |
| Disaster Recovery | Minimized downtime, regulatory compliance. | Maintains a synchronized, highly available copy of mission-critical data in the cloud. |
Powering AI And Machine Learning Models
AI and ML models are hungry for context, and that context has a strict expiration date. If you’re building a fraud detection algorithm, a personalized recommendation engine, or an agentic AI workflow, relying on stale data is a recipe for failure. Real-time data replication continuously feeds your Databricks environment with the freshest possible data. This ensures your training datasets remain relevant, your models maintain their accuracy, and your inference pipelines deliver reliable, profitable outcomes.
Real-Time Analytics And Operational Intelligence
Teams often rely on Databricks to power dashboards and customer insights that drive immediate action. For example, in retail, inventory optimization requires knowing exactly what is selling right now, not just what sold yesterday. In logistics, supply chain tracking requires real-time location and status updates. Continuous data replication ensures that business intelligence tools sitting on top of Databricks are reflecting operational reality the exact second a user looks at them.
Cloud Migration And Modernization Initiatives
Enterprises rarely move to the cloud in a single week. Modernization is a phased journey, often involving complex hybrid environments where legacy on-premise databases must coexist with Databricks for months or even years. Real-time replication acts as the bridge between these two worlds. It continuously synchronizes data from legacy systems to the cloud, minimizing downtime, reducing migration risk, and giving executives the confidence to modernize at their own pace.
Business Continuity And Disaster Recovery
If a primary operational system goes offline, the business needs a reliable backup. Data replication pipelines allow enterprises to maintain a continuously synchronized, high-fidelity copy of their mission-critical data within Databricks. Should an outage occur, this replicated data ensures business continuity, protects against catastrophic data loss, and helps organizations meet strict regulatory and compliance requirements.
Approaches and Strategies for Databricks Data Replication
Choosing data replication architecture means reviewing your specific business goals, latency requirements, data volume, and the complexity of your source systems. The wrong approach can lead to skyrocketing cloud compute costs or, conversely, data that is too stale to power your AI models.
Here are the primary strategies enterprises use to replicate data into Databricks, and how to determine which is right for your architecture.
Batch Replication vs. Real-Time Streaming
Historically, batch replication was the default integration strategy. It involves extracting and loading data in scheduled intervals—such as every few hours or overnight. Batch processing is relatively simple to set up and remains cost-effective for historical reporting use cases where immediate data freshness isn’t strictly required.
However, batch processing creates inherent latency. Real-time streaming, by contrast, establishes a continuous, always-on flow of data from your source systems directly into Databricks. For modern enterprises utilizing Databricks for machine learning, hyper-personalization, or operational analytics, streaming is no longer optional. It is the only way to ensure models and dashboards reflect the absolute current state of the business.
Change Data Capture (CDC) vs. Full Refresh Replication
How exactly do you extract the data from your source systems? A full refresh involves querying the entire dataset from a source and completely overwriting the target table in Databricks. While sometimes necessary for complete schema overhauls or syncing very small lookup tables, running full refreshes at an enterprise scale is resource-intensive, slow, and expensive.
Change Data Capture (CDC) is the modern standard for high-volume replication. Instead of running heavy queries against the database, log-based CDC reads the database’s transaction logs to identify and capture only the incremental changes (inserts, updates, deletes) as they happen. This drastically reduces the performance impact on source systems and delivers ultra-low latency. For Databricks environments where massive scale and continuous data freshness drive AI outcomes, CDC is the essential underlying technology.
One-Time Migration vs. Continuous Pipelines
It can be helpful to view replication as a lifecycle. A one-time migration is typically the first step. This is a bulk data movement designed to seed Databricks with historical data, often executed during initial cloud adoption or when modernizing legacy infrastructure.
But a migration is just a point-in-time event. To keep AI/ML models accurate and analytics dashboards relevant, that initial migration must seamlessly transition into a continuous replication pipeline. Continuous pipelines keep Databricks permanently synchronized with upstream operational systems over the long term, ensuring the lakehouse stays up to date.
Common Challenges of Replicating Data into Databricks
While continuous data replication has clear benefits, execution at an enterprise scale remains notoriously difficult. Data and technical leaders must be prepared to navigate several key hurdles when building pipelines into Databricks.
Handling Schema Drift And Complex Data Structures
Operational databases are not static. As businesses evolve, application developers constantly add new columns, modify data types, or drop fields to support new features. This phenomenon is known as schema drift.
If your replication infrastructure is rigid, an unexpected schema change in an upstream Oracle or Postgres database could instantly break the pipeline. This leads to missing data in Delta Lake, urgent alerts, and data engineers spending hours manually rebuilding jobs instead of focusing on high-value work. Managing complex, nested data structures and ensuring schema changes flow seamlessly into Databricks without manual intervention is one of the most persistent challenges teams face.
Managing Latency And Ensuring Data Freshness
The core value of Databricks for AI and operational analytics is the ability to act on current context. However, maintaining strict data freshness at scale is challenging.
Batch processing inherently leads to stale data. But even some streaming architectures, if poorly optimized or reliant on query-based extraction, can introduce unacceptable latency.
When a recommendation engine or fraud detection algorithm relies on data that is hours—or even minutes—old, it loses a great deal of value. The business risk of latency is direct and measurable: lost revenue, inaccurate automated decisions, and degraded customer experiences. Overcoming this requires true, low-latency streaming architectures capable of moving data in milliseconds.
Balancing Performance, Cost, And Scalability
Moving huge volumes of data is resource-intensive. If you utilize query-based extraction methods or run frequent full refreshes, you risk putting a heavy load on your production databases, potentially slowing down customer-facing applications.
Suboptimal ingestion into Databricks can also lead to infrastructure sprawl and cost creep. For example, continuously streaming data without properly managing file compaction can lead to the “small file problem” in Delta Lake, which degrades query performance and unnecessarily inflates cloud compute and storage bills. Scaling replication gracefully means balancing throughput with minimal impact on source systems and optimized delivery to the target.
Securing Sensitive Data During Replication
Enterprise pipelines frequently span on-premise systems, SaaS applications, and multiple cloud environments, exposing data in transit and leading to significant risks, if not protected sufficiently.
Organizations must strictly adhere to compliance frameworks like GDPR, HIPAA, and PCI-DSS. This means ensuring that sensitive information—such as Personally Identifiable Information (PII) or Protected Health Information (PHI)—is not exposed during the replication process. Implementing robust encryption in motion, enforcing fine-grained access controls, and maintaining comprehensive audit logs are critical, yet complex, requirements for any enterprise replication strategy.
Best Practices for Reliable, Scalable Databricks Replication
Building replication pipelines that can handle enterprise scale requires moving beyond basic data extraction. It requires a strategic approach to architecture, monitoring, and governance. Based on how leading organizations successfully feed their Databricks environments, here are the core best practices to follow.
Optimize For Delta Lake Performance
Simply dumping raw data into Databricks is not enough; the data must be formatted to utilize Delta Lake’s specific performance features.
To maximize query speed and minimize compute costs, replication pipelines should automatically handle file compaction to avoid the “small file problem.” Furthermore, your integration solution must support graceful schema evolution. When an upstream schema changes, the pipeline should automatically propagate those changes to the Delta tables without breaking the stream or requiring manual intervention. Delivering data that is pre-optimized for Delta Lake ensures that your downstream AI and BI workloads run efficiently and cost-effectively.
Monitor, Alert, And Recover From Failures Quickly
In a real-time environment, silent failures can be catastrophic. If a pipeline goes down and the data engineering team doesn’t know about it until a business user complains about a broken dashboard, trust in the data platform evaporates.
That’s why robust observability is non-negotiable. Your replication architecture must include built-in, real-time dashboards that track throughput, latency, and system health. You need proactive alerting mechanisms that notify teams the instant a pipeline degrades. Furthermore, the system must support automated recovery features—like exactly-once processing (E1P)—to ensure that if a failure does occur, data is not duplicated or lost when the pipeline restarts.
Plan For Hybrid And Multi-Cloud Environments
Few enterprises operate entirely within a single cloud or solely on-premise infrastructure. Your replication strategy must account for a heterogeneous data landscape.
Avoid point-to-point replication tools that only work for specific source-to-target combinations. Instead, adopt a unified integration platform with broad connector coverage. Your solution should seamlessly ingest data from legacy on-premise databases (like Oracle or SQL Server), SaaS applications (like Salesforce), and modern cloud infrastructure (like AWS, Azure, or Google Cloud) with consistent performance and low latency across the board.
Build Pipelines With Governance And Compliance In Mind
As data flows from operational systems into Databricks, maintaining strict governance is critical, especially when that data will eventually feed AI models.
Security and compliance cannot be afterthoughts bolted onto the end of a pipeline; they must be embedded directly into the data stream. Ensure your replication solution provides enterprise-grade encryption for data in motion. Implement fine-grained access controls to restrict who can build or view pipelines. Finally, maintain comprehensive lineage and auditability, so that when auditors ask exactly where a specific piece of data came from and how it arrived in Databricks, you have a definitive, verifiable answer.
How Striim Powers Real-Time Data Replication for Databricks
Overcoming these operational challenges requires more than just a pipleine; it requires robust, purpose-built architecture. As the world’s leading Unified Integration & Intelligence Platform, Striim enables enterprises to continuously feed Databricks with the fresh, secure, and highly optimized data required to drive AI and analytics into production.
Striim is proven at scale, routinely processing over 100 billion events daily with sub-second latency for global enterprises. Instead of wrestling with brittle code and siloed data, organizations use Striim to turn their data liabilities into high-velocity assets. By leveraging Striim for Databricks data replication, enterprises benefit from:
- Real-time CDC and streaming ingestion: Low-impact, log-based CDC continuously captures changes from legacy databases, SaaS applications, and cloud sources, delivering data in milliseconds.
- Optimized for Delta Lake: Striim natively formats data for Delta Lake performance, offering built-in support for automated schema evolution to ensure pipelines never break when upstream sources change.
- Enterprise-grade reliability: Striim guarantees exactly-once processing (E1P) and provides high availability, alongside real-time monitoring and proactive alerting dashboards to eliminate silent failures.
- Uncompromising security and compliance: Built-in governance features, including encryption in motion, fine-grained access control, and our Validata feature, ensure continuous pipeline trust and readiness for HIPAA, PCI, and GDPR audits.
- Hybrid and multi-cloud mastery: With over 100+ out-of-the-box connectors, Striim effortlessly bridges legacy on-premise environments with modern cloud infrastructure, accelerating cloud modernization.
Ready to see how a real-time, governed data layer can accelerate your Databricks initiatives? Book a demo today to see Striim in action, or start a free trial to begin building your pipelines immediately.
FAQs
How do I choose the right data replication tool for Databricks?
Choosing the right tool will depend on your business requirements for latency, scale, and source complexity. If your goal is to power AI, ML, or operational analytics, you should choose a platform that supports log-based Change Data Capture (CDC) and continuous streaming. Avoid tools limited to batch scheduling, as they will inherently introduce data staleness and limit the ROI of your Databricks investment.
What features should I prioritize in a Databricks replication solution?
At an enterprise scale, your top priorities should be reliability and Databricks-specific optimization. Look for solutions that offer exactly-once processing (E1P) to prevent data duplication during outages, and automated schema evolution to gracefully handle changes in source databases. Additionally, prioritize built-in observability and strict security features like encryption in motion to satisfy compliance requirements.
Can data replication pipelines into Databricks support both analytics and AI/ML workloads?
Yes, absolutely. A modern replication pipeline feeds data directly into Delta Lake, creating a unified foundation. Because Delta Lake supports both batch and streaming queries concurrently, the exact same low-latency data stream can power real-time ML inference models while simultaneously updating operational BI dashboards without conflict.
What makes real-time replication different from traditional ETL for Databricks?
Traditional ETL relies on batch processing, where heavy queries extract large chunks of data at scheduled intervals, slowing down source systems and delivering stale data. Real-time replication, specifically through CDC, reads the database transaction logs to capture only incremental changes (inserts, updates, deletes) as they happen. This drastically reduces the load on production databases and delivers fresh data to Databricks in milliseconds.
How does Striim integrate with Databricks for continuous data replication?
Striim natively integrates with Databricks by continuously streaming CDC data directly into Delta tables. It automatically handles file compaction and schema drift on the fly, ensuring the data lands perfectly optimized for Delta Lake’s performance architecture. Furthermore, Striim embeds intelligence directly into the stream, ensuring data is validated, secure, and AI-ready the moment it arrives.
Is Striim for Databricks suitable for hybrid or multi-cloud environments?
Yes. Striim is purpose-built for complex, heterogeneous environments. With over 100+ pre-built connectors, it seamlessly captures data from legacy on-premise systems (like Oracle or mainframe) and streams it into Databricks hosted on AWS, Google Cloud, or Microsoft Azure with consistent, low-latency performance.
How quickly can I set up a replication pipeline into Databricks with Striim?
With Striim’s intuitive, drag-and-drop UI and pre-built connectors, enterprise teams can configure and deploy continuous data pipelines in a matter of minutes or hours, not months. The platform eliminates the need for manual, brittle coding, allowing data engineers to focus on high-value architectural work rather than pipeline maintenance.


