What is
Data replication involves creating copies of data and storing them on different servers or sites. This results in multiple, identical copies of data being stored in different locations.
makes available on multiple sites, and in doing so, offers various benefits.
First of all, it enables better . If a system at one site goes down because of hardware issues or other problems, users can access stored at other nodes. Furthermore, allows for improved . Since is replicated to multiple sites, IT teams can easily restore deleted or corrupted .
also allows faster access to . Since is stored in various locations, users can retrieve from the closest servers and benefit from reduced latency. Also, there’s a much lower chance that any one server will become overwhelmed with user queries since can be retrieved from multiple servers. also supports improved , by allowing to be continuously replicated from a production database to a used by business intelligence teams.
Replicating to the
Replicating to the offers additional benefits. is kept safely off-site and won’t be damaged if a major disaster, such as a flood or fire, damages on-site infrastructure. is also cheaper than deploying on-site centers. Users won’t have to pay for hardware or maintenance.
Replicating to the is a safer option for smaller businesses that may not be able to afford full-time cybersecurity staff. providers are constantly improving their network and physical security. Furthermore, sites provide users with on-demand scalability and flexibility. can be replicated to servers in different geographical locations, including in the nearby region.
R Challenges
technologies offer many benefits, but IT teams should also keep in mind several challenges.
First of all, keeping at leads to rising and processing costs. In addition, setting up and maintaining a system often requires assigning a dedicated internal team.
Replicating across multiple copies requires deploying new processes and adding more traffic to the network. Finally, managing multiple updates in a distributed environment may cause to be out of sync on occasion. Database administrators need to ensure consistency in processes.
Data Replication Methods
The data replication strategy you choose is crucial as it impacts how and when your data is loaded from source to replica and how long it takes. An application whose database updates frequently wouldn’t want a data replication strategy that could take too long to reproduce the data in the replicas. Similarly, an application with less frequent updates wouldn’t require a data replication strategy that reproduces data in the replicas several times a day.
Log-Based Incremental Replication
Some databases allow you to store transaction logs for a variety of reasons, one of which is for easy recovery in case of a disaster. However, in log-based incremental replication, your replication tool can also look at these logs, identify changes to the data source, and then reproduce the changes in the replica data destination (e.g., database). These changes could be INSERT, UPDATE, or DELETE operations on the source database.
The benefits of this data replication strategy are:
- Because log-based incremental replication only captures row-based changes to the source and updates regularly (say, once every hour), there is low latency when replicating these changes in the destination database.
- There is also reduced load on the source because it streams only changes to the tables.
- Since the source consistently stores changes, we can trust that it doesn’t miss vital business transactions.
- With this data replication strategy, you can scale up without worrying about the additional cost of processing bulkier data queries.
Unfortunately, a log-based incremental replication strategy is not without its challenges:
- It’s only applicable to databases, such as MongoDB, MySQL, and PostgreSQL, that support binary log replication.
- Since each of these databases has its own log formats, it’s difficult to build a generic solution that covers all supported databases.
- In the case where the destination server is down, you have to keep the logs up to date until you restore the server. If not, you lose crucial data.
Despite its challenges, log-based incremental replication is still a valuable data replication strategy because it offers fast, secure, and reliable replication for data storage and analytics.
Key-Based Incremental Replication
As the name implies, key-based replication involves replicating data through the use of a replication key. The replication key is one of the columns in your database table, and it could be an integer, timestamp, float, or ID.
Key-based incremental replication only updates the replica with the changes in the source since the last replication job. During data replication, your replication tool gets the maximum value of your replication key column and stores it. During the next replication, your tool compares this stored maximum value with the maximum value of your replication key column in your source. If the stored maximum value is less than or equal to the source’s maximum value, your replication tool replicates the changes. Finally, the source’s maximum value becomes the stored value.
This process is repeated for every replication job that is key-based, continually using the replication key to spot changes in the source. This data replication strategy offers similar benefits as log-based data replication but comes with its own limitations:
- It doesn’t identify delete operations in the source. When you delete a data entry in your table, you also delete the replication key from the source. So the replication tool is unable to capture changes to that entry.
- There could be duplicate rows if the records have the same replication key values. This occurs because key-based incremental replication also compares values equal to the stored maximum value. So it duplicates the record until it finds another record of greater replication key.
In cases where log-based replication is not feasible or supported, key-based replication would be a close alternative. And knowing these limitations would help you better tackle data discrepancies where they occur.
Full Table Replication
Unlike the incremental data replication strategies that update based on changes to logs and the replication key maximum value, full table replication replicates the entire database. It copies everything: every new, existing, and updated row, from source to destination. It’s not concerned with any change in the source; whether or not some data changes, it replicates it.
The full table data replication strategy is useful in the following ways:
- You’re assured that your replica is a mirror image of the source and no data is missing.
- Full table replication is especially useful when you need to create a replica in another location so that your application’s content loads regardless of where your users are situated.
- Unlike key-based replication, this data replication strategy detects hard deletes to the source.
However, replicating an entire database has notable downsides:
- Because of the high volume of data replicated, full-table replication could take longer, depending on the strength of your network.
- It also requires higher processing power and can cause latency duplicating that amount of data at every replication job.
- The more you use full table replication to replicate to the same database, the more rows you use and the higher the cost to store all that data.
- Low latency and high processing power while replicating data may lead to errors during the replication process.
Although full table replication isn’t an efficient way to replicate data, it’s still a viable option when you need to recover deleted data or there aren’t any logs or suitable replication keys.
Snapshot Replication
Snapshot replication is the most common data replication strategy; it’s also the simplest to use. Snapshot replication involves taking a snapshot of the source and replicating the data at the time of the snapshot in the replicas.
Because it’s only a snapshot of the source, it doesn’t track changes to the source database. This also affects deletes to the source. At the time of the snapshot, the deleted data is no longer in the source. So it captures the source as is, without the deleted record.
For snapshot replication, we need two agents:
- Snapshot Agent: It collects the files containing the database schema and objects, stores them, and records every sync with the distribution database on the Distribution Agent.
- Distribution Agent: It delivers the files to the destination databases.
Snapshot replication is commonly used to sync the source and destination databases for most data replication strategies. However, you may use it on its own, scheduling it according to your custom time.
Just like the full table data replication strategy, snapshot replication may require high processing power if the source has a considerably large dataset. But it is useful if:
- The data you want to replicate is small.
- The source database doesn’t update frequently.
- There are a lot of changes in a short period, such that transactional or merge replication wouldn’t be an efficient option.
- You don’t mind having your replicas being out of sync with your source for a while.
Transactional Replication
In transactional replication, you first duplicate all existing data from the publisher (source) into the subscriber (replica). Subsequently, any changes to the publisher replicate in the subscriber almost immediately and in the same order.
It is important to have a snapshot of the publisher because the subscribers need to have the same data and database schema as the publisher for them to receive consistent updates. Then the Distribution Agent determines the regularity of the scheduled updates to the subscriber.
To perform transactional replication, you need the Distribution Agent, Log Reader Agent, and Snapshot Agent.
- Snapshot Agent: It works the same as the Snapshot Agent for snapshot replication. It generates all relevant snapshot files.
- Log Reader Agent: It observes the publisher’s transaction logs and duplicates the transactions in the distribution database.
- Distribution Agent: It copies the snapshot files and transaction logs from the distribution database to the subscribers.
- Distribution database: It aids the flow of files and transactions from the publisher to the subscribers. It stores the files and transactions until they’re ready to move to the subscribers.
Transactional replication is appropriate to use when:
- Your business can’t afford downtime of more than a few minutes.
- Your database changes frequently.
- You want incremental changes in your subscribers in real time.
- You need up-to-date data to perform analytics.
In transactional replication, subscribers are mostly used for read purposes, and so this data replication strategy is commonly used when servers only need to talk to other servers.
Merge Replication
Merge replication combines (merges) two or more databases into one so that updates to one (primary) database are reflected in the other (secondary) databases. This is one key trait of merge replication that differentiates it from the other data replication strategies. A secondary database may retrieve changes from the primary database, receive updates offline, and then sync with the primary and other secondary databases once back online.
In merge replication, every database, whether it’s primary or secondary, can make changes to your data. This can be useful when one database goes offline and you need the other to operate in production, then get the offline database up to date once it’s back online.
To avoid data conflicts that may arise from allowing modifications from secondary databases, merge replication allows you to configure a set of rules to resolve such conflicts.
Like most data replication strategies, merge replication starts with taking a snapshot of the primary database and then replicating the data in the destination databases. This means that we also begin the merge replication process with the Snapshot Agent.
Merge replication also uses the Merge Agent, which commits or applies the snapshot files in the secondary databases. The Merge Agent then reproduces any incremental updates in the other databases. It also identifies and resolves all data conflicts during the replication job.
You may opt for merge replication if:
- You’re less concerned with how many times a data object changes but more interested in its latest value.
- You need replicas to update and reproduce the updates in the source and other replicas.
- Your replica requires a separate segment of your data.
- You want to avoid data conflicts in your database.
Merge replication remains one of the most complex data replication strategies to set up, but it can be valuable in client-server environments, like mobile apps or applications where you need to incorporate data from multiple sites.
Bidirectional Replication
Bidirectional replication is one of the less common data replication strategies. It is a subset of transactional replication that allows two databases to swap their updates. So both databases permit modifications, like merge replication. However, for a transaction to be successful, both databases have to be active.
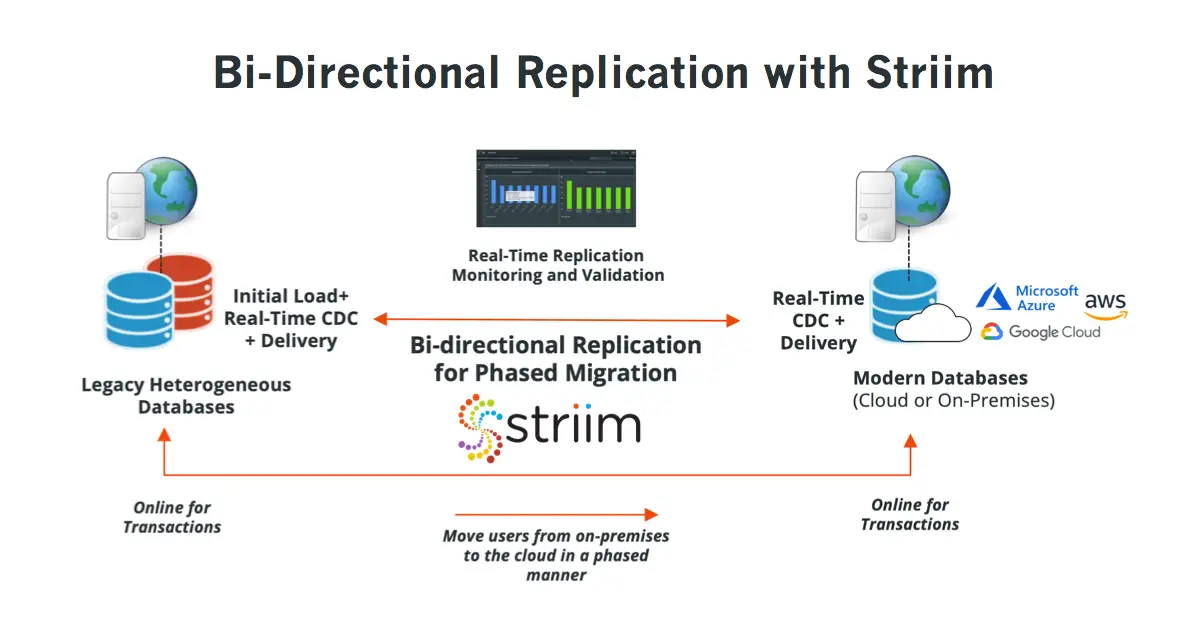
Here, there is no definite source database. Each database may be from the same platform (e.g., Oracle to Oracle) or from separate platforms (e.g., Oracle to MySQL). You may choose which rows or columns each database can modify. You may also decide which database is a higher priority in case of record conflicts, i.e., decide which database updates are reflected first.
Bidirectional replication is a good choice if you want to use your databases to their full capacity and also provide disaster recovery.
Your Data Replication Strategy Shouldn’t Slow You Down: Try Striim
Regardless of your type of application, there’s a data replication strategy that best suits your business needs. Combine any data replication strategies you want. Just ensure that the combination offers a more efficient way to replicate your databases according to your business objectives.
Every data replication strategy has one cost in common: the time it takes. Few businesses today can afford to have their systems slowed down by data management, so the faster your data replicates, the less negative impact it will have on your business.
Replicating your database may be time-consuming, and finding the right data replication tool to help speed up and simplify this process, while keeping your data safe, can be beneficial to your business.

For fast, simple, and reliable data replication, Striim is your best bet. Striim provides real-time data replication by extracting data from databases using log-based change data capture and replicating it to targets in real time. Regardless of where your data is, Striim gets your data safely to where you need it to be and shows you the entire process, from source to destination.
Schedule a demo and we’ll give you a personalized walkthrough or try Striim at production-scale for free! Small data volumes or hoping to get hands on quickly? At Striim we also offer a free developer version.


