Reliable access to data is vital for companies to thrive in this digital age. But businesses struggle with various risk factors- like hardware failures, cyberattacks, and geographical distances-that could block access to data or corrupt valuable data assets. Left without access to data, teams may struggle to carry out day-to-day tasks and deliver on important projects.
One way to safeguard your data from those risks is using data replication solutions. This technology is indispensable for teams that want to replicate and protect their mission-critical data and use it as a source of competitive advantage.
To help businesses explore data replication, we’ll dive into this technology and explore what features you should look for in data replication software.
What is Data Replication
is the process of copying from an on-premise or cloud and storing it on another or site. The result is a multitude of exact copies residing in multiple locations.
These replicas support teams in their and efforts. If is compromised at one site (for example by a system failure or a cyberattack), teams can pull from other servers and resume their work.
also allows users to access stored on servers close to their offices, reducing network latency. For , users in Asia may experience a delay when accessing stored in North America-based servers. But the latency will decrease if a replica of this is kept on a that’s closer to Asia.
also plays an important role in and business intelligence efforts, in which is replicated from operational databases to warehouses.
How Data Replication Works
Data replication is the process of copying data from an on-premise or cloud server and storing it on another server or site. The result is a multitude of exact data copies residing in multiple locations.
These data replicas support teams in their disaster recovery and business continuity efforts. If data is compromised at one site (for example by a system failure or a cyberattack), teams can pull replicated data from other servers and resume their work.
Replication also allows users to access data stored on servers close to their offices, reducing network latency. For instance users in Asia may experience a delay when accessing data stored in North America-based servers. But the latency will decrease if a replica of this data is kept on a node that’s closer to Asia.
Data replication also plays an important role in analytics and business intelligence efforts, in which data is replicated from operational databases to data warehouses.
Types and Methods of Data Replication
Depending on their needs, companies can choose among several types of data replication:
- Transactional replication: Users receive a full copy of their data sets, and updates are continuously replicated as data in the source changes.
- Snapshot replication: A snapshot of the database is sent to replicated sites at a specific moment.
- Merge replication: Data from multiple databases is replicated into a single database.
In tactical terms, there are several methods for replicating data, including:
- Full-table replication: Every piece of new, updated, and existing data is copied from the source to the destination site. This method copies all data every time and requires a lot of processing power, which puts networks under heavy stress.
- Key-based incremental replication: Only data changed since the previous update will be replicated. This approach uses less processing power but can’t replicate hard-deleted data.
- Log-based incremental replication: Data is replicated based on information in database log files. This is an efficient method but works only with database sources that support log-based replication (such as Microsoft SQL Server, Oracle , and PostgreSQL).
What to Look for in Data Replication Software
Data replication software: key features
Data replication software should ideally contain the following features:
A large number of connectors: A replication tool should allow you to replicate data from various sources and SaaS tools to data warehouses and other targets.
Log-based capture: An ideal replication software product should capture streams of data using log-based change data capture.
Data transformation: Data replication solutions should also allow users to clean, enrich, and transform replicated data.
Built-in monitoring: Dashboards and monitoring enable you to see the state of your data flows in real-time and easily identify any bottlenecks. For mission-critical systems that have data delivery Service Level Agreements (SLAs), it’s also important to have visibility into end-to-end lag
Custom alerts: Data replication software should offer alerts that can be configured for a variety of metrics, keeping you up to date on the status and performance of your data flows.
Ease of use: A drag-and-drop interface is an ideal solution for users to quickly set up replication processes.
Data replication software vs. writing code internally
Of course, users can set up the replication process by writing code internally. But managing yet another in-house app is a major commitment of energy, staff, and money. The app also may require the team to handle error logging, refactoring code, alerting, etc. It comes as no surprise that many teams are opting for third-party data replication software.
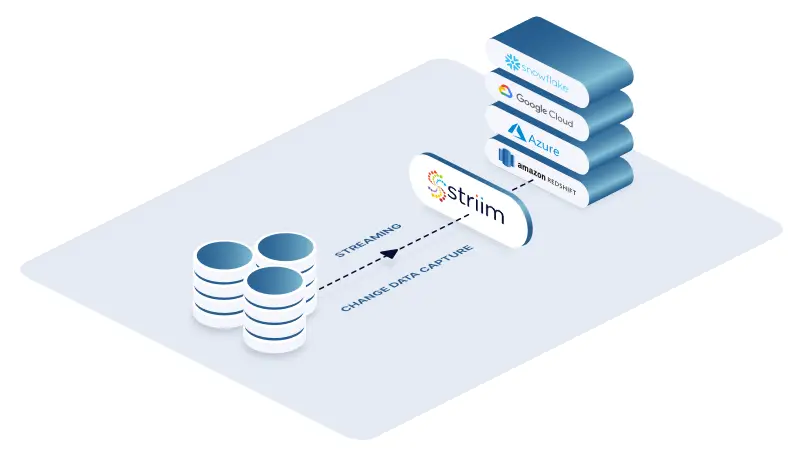
Use Striim to replicate data in real time
There are also real-time database replication solutions such as Striim. Striim is a unified streaming and real-time data integration platform that connects over 150 sources and targets. Striim provides real-time data replication by extracting data from databases using log-based change data capture and replicating it to targets in real time.

Striim‘s data integration and replication capabilities support various use cases. This platform can, for instance, enable financial organizations to near instantaneously replicate transactions and new balances data to customer accounts. Inspyrus, a San Francisco-based fintech startup, uses Striim to replicate invoicing data from its private cloud operational databases to other cloud targets such as Snowflake for real-time analytics.
Striim can also be used to replicate obfuscated sensitive data to Google Cloud while original data is safely kept in an on-premises environment. Furthermore, Striim supports mission-critical use cases with data delivery and latency SLAs. Striim customer Macy’s uses Striim to streamline retail operations and provide a unified customer experience. Even at Black Friday traffic levels, Striim is able to deliver data from Macy’s on-premises data center to Google Cloud with less than 200ms latency.
Have More Time to Analyze Data
Reliable access to data is of vital importance for today’s companies. But that access can often be blocked or limited, which is why data replication solutions are increasingly important. They enable teams to replicate and protect valuable data assets, and support disaster recovery efforts. And with data secured, teams can have more time and energy to analyze data and find insights that will provide a competitive edge.
Ready to see how Striim can help you simplify data integration and replication? Request a demo with one of our data replication experts, or try Striim for free.


