If you’re considering adopting a cloud-based data warehousing and analytics solution the most important consideration is how to populate it with current on-site and cloud data in real time with cloud etl.
As noted in a recent study by IBM and Forrester, 88% of companies want to run near-real-time analytics on stored data. Streaming Cloud ETL enables real-time analytics by loading data from operational systems from private and public clouds to your analytics cloud of choice.

A streaming cloud ETL solution enables you to continuously load data from your in-house or cloud-based mission-critical operational systems to your cloud-based analytical systems in a timely and dependable manner. Reliable and continuous data flow is essential to ensuring that you can trust the data you use to make important operational decisions.
In addition to high-performance and scalability to handle your large data volumes, you need to look for data reliability and pipeline high availability. What should you look for in a streaming cloud ETL solution to be confident that it offers the high degree of reliability and availability your mission-critical applications demand?
For data reliability, the following two common issues with data pipelines should be avoided:
- Data loss. When data volumes increase and the pipelines are backed up, some solutions allow some of the data to be discarded. Also, when the CDC solution has limited data type support, it may not be able to capture the columns that contain that data type. If an outage or process interruption occurs, an incorrect recovery point can also lead to skipping some data.
- Duplicate data. After recovering from a process interruption, the system may create duplicate data. This issue becomes even more prevalent when processing the data with time windows after the CDC step.
How Striim Ensures Reliable and Highly Available Streaming Cloud ETL
Striim ingests, moves, processes, and delivers real-time data across heterogeneous and high-volume data environments. The software platform is built ground-up specifically to ensure reliability for streaming cloud ETL solutions with the following architectural capabilities.
Fault-tolerant architecture
Striim is designed with a built-in clustered environment with a distributed architecture to provide immediate failover. The metadata and clustering service watches for node failure, application failure, and failure of certain other services. If one node goes down, another node within the cluster immediately takes over without the need for users to do this manually or perform complex configurations.
 Exactly Once Processing for zero data loss or duplicates
Exactly Once Processing for zero data loss or duplicates
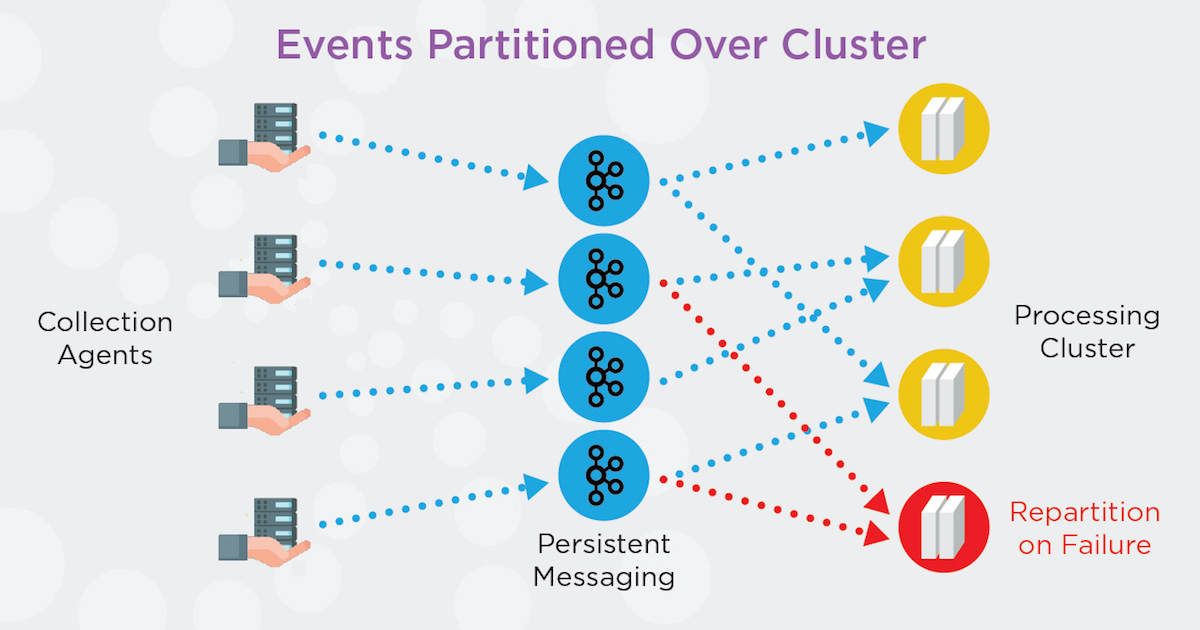
Striim’s advanced checkpointing capabilities ensure that no events are missed or processed twice while taking time window contents into account. It has been tested and certified for cloud solutions to offer real-time streaming to Microsoft Azure, AWS, and/or Google Cloud with event delivery guarantees.
During data ingest, checkpointing keeps track of all events the system processes and how far they got down various data pipelines. If something fails, Striim knows the last known good state and what position it needs to recover from. Advanced checkpointing is designed to eliminate loss in data windows when the system fails.
If you have a defined data window (say 5 minutes) and the system goes down, you cannot typically restart from where you left off because you will have lost the 5 minutes’ worth of data that was in the data window. That means your source and target will no longer be completely synchronized. Striim addresses this issue by coordinating with the data replay feature that many data sources provide to rewind sources to just the right spot if a failure occurs.
In cases where data sources don’t support data replay—for example, data coming from sensors—Striim’s persistent messaging stores and checkpoints data as it is ingested. Persistent messaging allows previously non-replayable sources to replayed from a specific point. It also allows multiple flows from the same data source to maintain their own checkpoints. To offer exactly once processing, Striim checks to make sure input data has actually been written. As a result, the platform can checkpoint, confident in the knowledge that the data made it to the persistent queue.
End-to-end data flow management for simplified solution architecture and recovery
Striim’s streaming cloud ETL solution also delivers streamlined, end-to-end data integration between source and target systems that enhances reliability. The solution ingests data from the source in real time, performs all transformations such as masking, encryption, aggregation, and enrichment in memory as the data goes through the stream and then delivers the data to the target in a single network operation. All of these operations occur in one step without using a disk and deliver the streaming data to the target in sub-seconds. Because Striim does not require additional products, this simplified solution architecture enables a seamless recovery process and minimizes the risk of data loss or inaccurate processing.
In contrast, a data replication service without built-in stream processing requires data transformation to be performed in the target (or source), with an additional product and network hop. This minimum two-hop process introduces unnecessary data latency. It also complicates the solution architecture, exposing the customer to considerable recovery-related risks and requiring a great deal of effort for accurate data reconciliation after an outage.
For use cases where transactional integrity matters, such as migrating to a cloud database or continuously loading transactional data for a cloud-based business system, Striim also maintains ACID properties (atomicity, consistency, isolation, and durability) of database operations to preserve the transactional context.
The best way to choose a reliable streaming cloud ETL solution is to see it in action. Click here to request a customized demo for your specific environment.


