- Introduction
- Types of Data Ingestion
- Benefits of Data Ingestion
- Data Ingestion Challenges
- Data Ingestion Tools
- Finding a Key Differentiator
Introduction
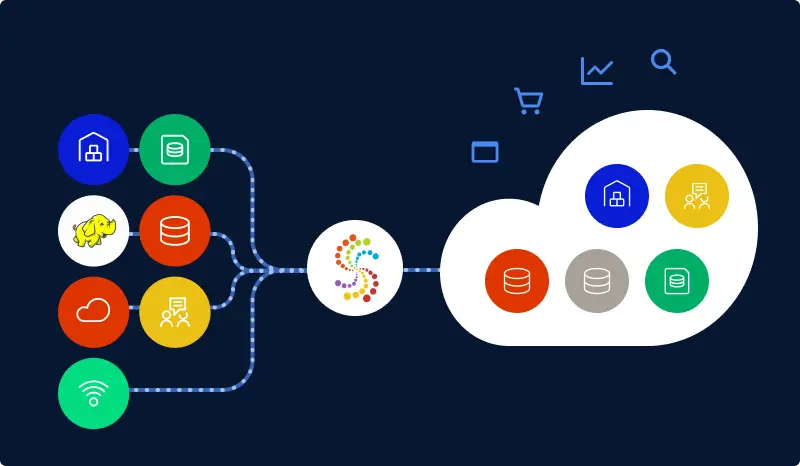
Data ingestion is the process of transporting data from one or more sources to a target site for further processing and analysis. This data can originate from a range of sources, including data lakes, IoT devices, on-premises databases, and SaaS apps, and end up in different target environments, such as cloud data warehouses or data marts.
Data ingestion is a critical technology that helps organizations make sense of an ever-increasing volume and complexity of data. To help businesses get more value out of data ingestion, we’ll dive deeper into this technology. We’ll cover types of data ingestion, how data ingestion is done, the difference between data ingestion and ETL, data ingestion tools, and more.
Types of Data Ingestion
There are three ways to carry out data ingestion, including real time, batches, or a combination of both in a setup known as lambda architecture. Companies can opt for one of these types depending on their business goals, IT infrastructure, and financial limitations.
Real-time data ingestion
Real-time data ingestion is the process of collecting and transferring data from source systems in real time using solutions such as change data capture (CDC). CDC constantly monitors transaction or redo logs and moves changed data without interfering with the database workload. Real-time ingestion is essential for time-sensitive use cases, such as stock market trading or power grid monitoring, when organizations have to rapidly react to new information. Real-time data pipelines are also vital when making rapid operational decisions and identifying and acting on new insights.
Batch-based data ingestion
Batch-based data ingestion is the process of collecting and transferring data in batches according to scheduled intervals. The ingestion layer may collect data based on simple schedules, trigger events, or any other logical ordering. Batch-based ingestion is useful when companies need to collect specific data points on a daily basis or simply don’t need data for real-time decision-making.
Lambda architecture-based data ingestion
Lambda architecture is a data ingestion setup that consists of both real-time and batch methods. The setup consists of batch, serving, and speed layers. The first two layers index data in batches, while the speed layer instantaneously indexes data that has yet to be picked up by slower batch and serving layers. This ongoing hand-off between different layers ensures that data is available for querying with low latency.
Benefits of Data Ingestion
Data ingestion technology offers various benefits, enabling teams to manage data more efficiently and gain a competitive advantage. Some of these benefits include:
- Data is readily available: Data ingestion helps companies gather data stored across various sites and move it to a unified environment for immediate access and analysis.
- Data is less complex: Advanced data ingestion pipelines, combined with ETL solutions, can transform various types of data into predefined formats and then deliver it to a data warehouse.
- Teams save time and money: Data ingestion automates some of the tasks that previously had to be manually carried out by engineers, whose time can now be dedicated to other more pressing tasks.
- Companies make better decisions: Real-time data ingestion allows businesses to quickly notice problems and opportunities and make informed decisions.
- Teams create better apps and software tools: Engineers can use data ingestion technology to ensure that their apps and software tools move data quickly and provide users with a superior experience.
Data Ingestion Challenges
Setting up and maintaining data ingestion pipelines might be simpler than before, but it still involves several challenges:
- The data ecosystem is increasingly diverse: Teams have to deal with an ever-growing number of data types and sources, making it difficult to create a future-proof data ingestion framework.
- Legal requirements are more complex: From GDPR to HIPAA to SOC 2, data teams have to familiarize themselves with various data privacy and protection regulations to ensure they’re acting within the boundaries of the law.
- Cyber-security challenges grow in size and scope: Data teams have to fend off frequent cyber-attacks launched by malicious actors in an attempt to intercept and steal sensitive data.
Data Ingestion Tools
Data ingestion tools are software products that gather and transfer structured, semi-structured, and unstructured data from source to target destinations. These tools automate otherwise laborious and manual ingestion processes. Data is moved along a data ingestion pipeline, which is a series of processing steps that take data from one point to another.
Data ingestion tools come with different features and capabilities. To select the tool that fits your needs, you’ll need to consider several factors and decide accordingly:
- Format: Is data arriving as structured, semi-structured, or unstructured?
- Frequency: Is data to be ingested and processed in real time or in batches?
- Size: What’s the volume of data an ingestion tool has to handle?
- Privacy: Is there any sensitive data that needs to be obfuscated or protected?
And data ingestion tools can be used in different ways. For instance, they can move millions of records into Salesforce every day. Or they can ensure that different apps exchange data on a regular basis. Ingestion tools can also bring marketing data to a business intelligence platform for further analysis.
Data ingestion vs. ETL
Data ingestion tools may appear similar in function to ETL platforms, but there are some differences. For one, data ingestion is primarily concerned with extracting data from the source and loading it into the target site. ETL, however, is a type of data ingestion process that involves not only the extraction and transfer of data but also the transformation of that data before its delivery to target destinations.
ETL platforms, such as Striim, can perform various types of transformation, such as aggregation, cleansing, splitting, and joining. The goal is to ensure that the data is delivered in a format that matches the requirements of the target location.
Finding a Key Differentiator
Data ingestion is a vital tech that helps companies extract and transfer data in an automated way. With data ingestion pipelines established, IT and other business teams can focus on extracting value from data and finding new insights. And automated data ingestion can become a key differentiator in today’s increasingly competitive marketplaces.
Schedule a demo and we’ll give you a personalized walkthrough or try Striim at production-scale for free! Small data volumes or hoping to get hands on quickly? At Striim we also offer a free developer version.


