If your application goes down, your customers go elsewhere. That’s the harsh reality for enterprise companies operating at a global scale. In distributed architectures, relying on a single database node leads to a single point of failure. You need continuous, reliable copies of your data distributed across servers to ensure high availability, disaster recovery, and low-latency access for users around the world.
MongoDB is a leading NoSQL database because it makes data replication central to its architecture. It handles the basics of keeping multiple copies of your data for durability natively. But for modern enterprises, simply having a backup copy of your operational data is no longer sufficient.
As they scale, enterprises need continuous, decision-ready data streams. They need to feed cloud data warehouses, power real-time analytics, and supply AI agents with fresh context. While MongoDB’s native replication is a strong foundation for operational health, it wasn’t designed to deliver data in motion across your entire enterprise ecosystem.
In this guide, we will explore the core modes of MongoDB data replication, the limitations of relying solely on native tools at the enterprise level, and how Change Data Capture (CDC) turns your operational data into a continuous, real-time asset. (If you’re looking for a broader industry overview across multiple databases, check out our guide to modern database replication).
What is Data Replication in MongoDB?
Data replication is the process of keeping multiple, synchronized copies of your data across different servers or environments. In distributed systems, this is a foundational requirement. If your infrastructure relies on a single database server, a hardware failure or network outage will take your entire application offline. MongoDB, as a leading NoSQL database built for scale and flexibility, makes replication a central pillar of its architecture. Rather than treating replication as an afterthought or a bolt-on feature, MongoDB natively distributes copies of your data across multiple nodes. This ensures that if the primary node goes down, a secondary node is standing by, holding an identical copy of the data, ready to take over. It provides the durability and availability required to keep modern applications running smoothly.
Why Data Replication Matters for Enterprises
While basic replication is helpful for any MongoDB user, the stakes are exponentially higher in enterprise environments. A minute of downtime for a small startup might be an inconvenience; for a global enterprise, it means lost revenue, damaged brand reputation, and potential compliance violations.
For enterprises, replicating MongoDB data is a business-critical operation that drives continuity, intelligence, and customer satisfaction.
Business Continuity and Disaster Recovery
Data center outages, natural disasters, and unexpected server crashes are inevitable. When they happen, enterprises must ensure minimal disruption, making proactive infrastructure planning a top enterprise risk management trend. By replicating MongoDB data across different physical locations or cloud regions, you create a robust disaster recovery strategy. If a primary node fails, automated failover mechanisms promote a secondary node to take its place, ensuring your applications stay online and your data remains intact.
Real-Time Analytics and Faster Decision-Making
Operational data is most valuable the instant it’s created. However, running heavy analytics queries directly on your primary operational database can degrade performance and slow down your application. Replication solves this by moving a continuous copy of your operational data into dedicated analytics systems or cloud data warehouses. This reduces the latency between a transaction occurring and a business leader gaining insights from it, enabling faster, more accurate decision-making and powering true real-time analytics.
Supporting Global Scale and Customer Experience
Modern enterprises serve global user bases that demand instantaneous interactions. If a user in Tokyo has to query a database located in New York, anything other than low latency will degrade their experience. By replicating MongoDB data to regions closer to your users, you enable faster local read operations. This ensures that regardless of where your customers are located, they receive the high-speed, low-latency experience they expect from a top-tier brand.
The Two Primary Modes of MongoDB Replication
When architecting a MongoDB deployment, database administrators and data architects have two core architectural choices for managing scale and redundancy. (While we focus on MongoDB’s native tools here, there are several broader data replication strategies you can deploy across a sprawling enterprise stack).
Replica Sets
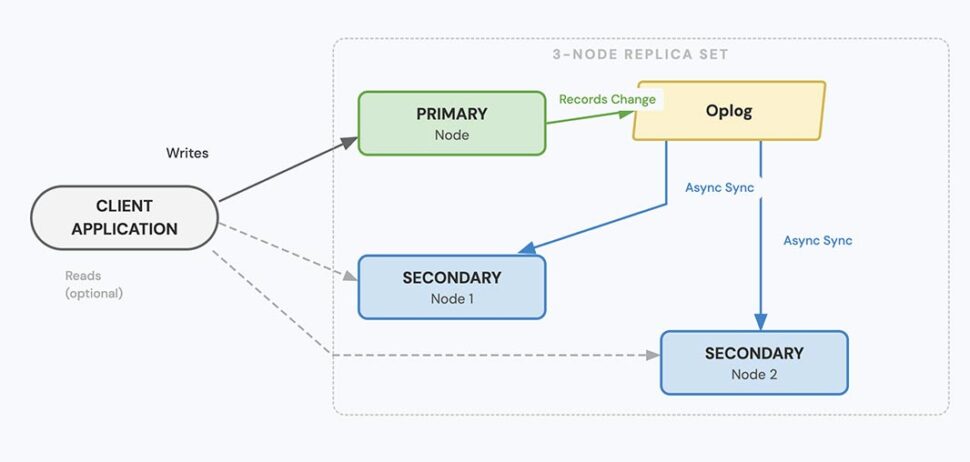
A replica set is the foundation of MongoDB’s replication strategy. It relies on a “leader-follower” model: a group of MongoDB instances that maintain the same data set.
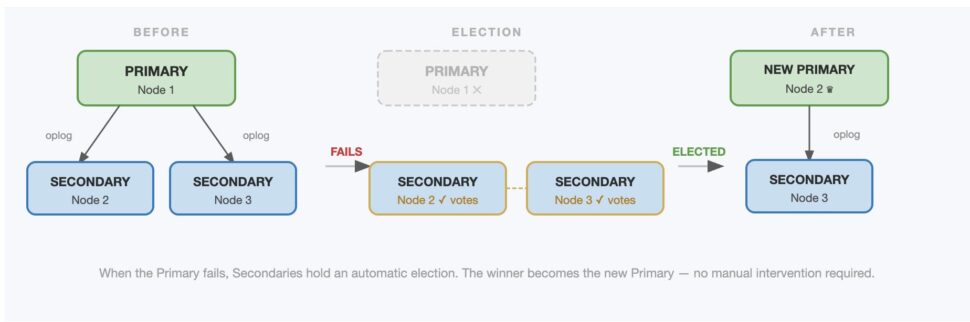
In a standard configuration, one node is designated as the Primary (leader), which receives all write operations from the application. The other nodes act as Secondaries (followers). The secondaries continuously replicate the primary’s oplog (operations log) and apply the changes to their own data sets, ensuring they stay synchronized.
If the primary node crashes or becomes unavailable due to a network partition, the replica set automatically holds an election. The remaining secondary nodes vote to promote one of themselves to become the new primary, resulting in automatic failover without manual intervention.
Sharding
As your application grows, you may reach a point where a single server (or replica set) can no longer handle the sheer volume of read/write throughput or store the massive amount of data required. This is where sharding comes in.
While replica sets are primarily about durability and availability, sharding is about scaling writes and storage capacity. Sharding distributes your data horizontally across multiple independent machines.
However, sharding and replication are not mutually exclusive—in fact, they work together. In a production MongoDB sharded cluster, each individual shard is deployed as its own replica set. This guarantees that not only is your data distributed for high performance, but each distributed chunk of data is also highly available and protected against server failure.
Replica Sets vs. Sharding: Key Differences
To clarify when to rely on each architectural component, here is a quick breakdown of their core differences:
Feature |
Replica Sets |
Sharding |
| Primary Purpose | High availability, data durability, and disaster recovery. | Horizontal scaling for massive data volume and high write throughput. |
| Scaling Type | Scales reads (by directing read operations to secondary nodes). | Scales writes and storage (by distributing data across multiple servers). |
| Complexity | Moderate. Easier to set up and manage. | High. Requires config servers, query routers (mongos), and careful shard key selection. |
| Complexity | Cannot scale write operations beyond the capacity of the single primary node. | Complex to maintain, and choosing the wrong shard key can lead to uneven data distribution (hotspots). |
Challenges with Native MongoDB Replication
While replica sets and sharding are powerful tools for keeping your database online, they were designed specifically for operational durability. But as your data strategy matures, keeping the database alive becomes the baseline, not the end destination.
Today’s businesses need more than just identical copies of a database sitting on a secondary server. When evaluating data replication software, enterprises must look for tools capable of pushing data into analytics platforms, personalized marketing engines, compliance systems, and AI models.
When organizations try to use native MongoDB replication to power these broader enterprise initiatives, they quickly run into roadblocks.
Replication Lag and Performance Bottlenecks
Under heavy write loads or network strain, secondary nodes can struggle to apply oplog changes as fast as the primary node generates them. This creates replication lag. If your global applications are directing read traffic to these secondary nodes, users may experience stale data. In an enterprise context—like a financial trading app or a live inventory system—even a few seconds of latency can quietly break enterprise AI at scale and lead to costly customer experience errors.
Cross-Region and Multi-Cloud Limitations
Modern enterprises rarely operate in a single, homogenous environment. You might have MongoDB running on-premises while your analytics team relies on Snowflake in AWS, or you might be migrating from MongoDB Atlas to Google Cloud. Native MongoDB replication is designed to work within the MongoDB ecosystem. It struggles to support the complex, hybrid, or multi-cloud replication pipelines that enterprises rely on to prevent vendor lock-in and optimize infrastructure costs.
Complexity in Scaling and Managing Clusters
Managing a globally distributed replica set or a massive sharded cluster introduces significant operational headaches. Database administrators (DBAs) must constantly monitor oplog sizing, balance shards to avoid data “hotspots,” and oversee election protocols during failovers. As your data footprint grows, the operational overhead of managing these native replication mechanics becomes a drain on engineering resources.
Gaps in Analytics, Transformation, and Observability
Perhaps the most significant limitation: native replication is not streaming analytics. Replicating data to a secondary MongoDB node simply gives you another MongoDB node.
Native replication does not allow you to filter out Personally Identifiable Information (PII) before the data lands in a new region for compliance. It doesn’t transform JSON documents into a relational format for your data warehouse. And it doesn’t offer the enterprise-grade observability required to track data lineage or monitor pipeline health. To truly activate your data, you need capabilities that go far beyond what native MongoDB replication provides.
Real-Time Change Data Capture (CDC) for MongoDB
To bridge the gap between operational durability and enterprise-wide data activation, modern organizations are turning to streaming solutions.
At a high level, log-based Change Data Capture (CDC) is a data integration methodology that identifies and captures changes made to a database in real time. For MongoDB, CDC tools listen directly to the operations log (oplog): the very same log MongoDB uses for its native replica sets. As soon as a document is inserted, updated, or deleted in your primary database, CDC captures that exact event.
This shift in methodology changes the entire paradigm of data replication. Instead of just maintaining a static backup on a secondary server, CDC turns your operational database into a live data producer. It empowers organizations to route streams of change events into analytical platforms, cloud data warehouses, or message brokers like Kafka the instant they happen.
By adopting CDC, stakeholders no longer view data replication as a mandatory IT checkbox for disaster recovery. Instead, it becomes a unified foundation for customer experience, product innovation, and measurable revenue impact.
Real-Time CDC vs. Batch-Based Replication
Historically, moving data out of an operational database for analytics or replication meant relying on batch processing (traditional ETL). A script would run periodically—perhaps every few hours or overnight—taking a snapshot of the database and moving it to a warehouse.
Batch replication is fundamentally flawed for modern enterprises. Periodic data dumps introduce hours of latency, meaning your analytics and AI models are always looking at the past.
Furthermore, running heavy batch queries against your operational database can severely degrade performance, sometimes requiring “maintenance windows” or risking application downtime.
CDC eliminates these risks. Because it reads directly from the oplog rather than querying the database engine itself, CDC has virtually zero impact on your primary database’s performance. It is continuous, low-latency, and highly efficient. Here is how the two approaches compare:
Feature |
Batch-Based Replication (ETL) |
Real-Time CDC |
| Data Freshness (Latency) | High (Hours to days). Data reflects a historical snapshot. | Low (Sub-second). Data reflects the current operational state immediately. |
| Performance Impact | High. Large, resource-intensive queries can degrade primary database performance. | Minimal. Reads seamlessly from the oplog, preventing strain on production systems. |
| Operation Type | Periodic bulk dumps or scheduled snapshots. | Continuous, event-driven streaming of document-level changes (inserts, updates, deletes). |
| Ideal Use Cases | End-of-month reporting, historical trend analysis. | Real-time analytics, continuous AI context, live personalization, and zero-downtime migrations. |
Use Cases for MongoDB Data Replication with CDC
For today’s data-driven enterprises, robust data replication is far more than a “nice to have”. By pairing MongoDB with an enterprise-grade CDC streaming platform like Striim, organizations unlock powerful use cases that natively replicate systems simply cannot support.
Zero-Downtime Cloud Migration
Moving large MongoDB workloads from on-premises servers to the cloud—or migrating between different cloud providers—often requires taking applications offline. For a global enterprise, even planned downtime is costly.
Real-time CDC replication eliminates this hurdle. Striim continuously streams oplog changes during the migration process, seamlessly syncing the source and target databases. This means your applications stay live and operational while the migration happens in the background. Once the target is fully synchronized, you simply execute a cutover with zero downtime and zero data loss.
Real-Time Analytics and AI Pipelines
To make accurate decisions or feed context to generative AI applications, businesses need data that is milliseconds old, not days old.
With CDC, you can replicate MongoDB data and feed it into downstream systems like Snowflake, Google BigQuery, Databricks, or Kafka in real time. But the true value lies in what happens in transit. Striim doesn’t just move the data; it transforms and enriches it in-flight. You can flatten complex JSON documents, join data streams, or generate vector embeddings on the fly, ensuring your data is instantly analytics- and AI-ready the moment it lands. Enterprises gain actionable insights seconds after events occur.
Global Applications with Low-Latency Data Access
Customer experience is intrinsically linked to speed. When users interact with a global application, they expect instantaneous responses regardless of their geographic location.
Native MongoDB replication can struggle with cross-region lag, especially over unreliable network connections. Striim helps solve this by optimizing real-time replication pipelines across distributed regions and hybrid clouds. By actively streaming fresh data to localized read-replicas or regional data centers with sub-second latency, you ensure a frictionless, high-speed experience for your end users globally.
Regulatory Compliance and Disaster Recovery
Strict data sovereignty laws, such as GDPR in Europe or state-specific regulations in the US, mandate exactly where and how customer data is stored.
Striim enables intelligent replication into compliant environments. Utilizing features like in-stream masking and filtering, you can ensure Personally Identifiable Information (PII) is obfuscated or removed before it ever crosses regional borders. Additionally, if disaster strikes, Striim’s continuous CDC replication ensures your standby systems possess the exact, up-to-the-second state of your primary database. Failover happens with minimal disruption, high auditability, and zero lost data.
Extend MongoDB Replication with Striim
MongoDB’s native replication is incredibly powerful for foundational operational health. It ensures your database stays online and your transactions are safe. But as enterprise data architectures evolve, keeping the database alive is only half the battle.
To truly activate your data—powering real-time analytics, executing zero-downtime migrations, maintaining global compliance, and feeding next-generation AI agents—real-time CDC is the proven path forward.
Striim is the world’s leading Unified Integration & Intelligence Platform, designed to pick up where native replication leaves off. With Striim, enterprises gain:
- Log-based CDC: Seamless, zero-impact capture of inserts, updates, and deletes directly from MongoDB’s oplog.
- Diverse Targets: Replicate your MongoDB data anywhere via our dedicated MongoDB connector—including Snowflake, BigQuery, Databricks, Kafka, and a wide array of other databases.
- In-Flight Transformation: Filter, join, mask, and convert complex JSON formats on the fly before they reach your target destination.
- Cross-Cloud Architecture: Build resilient, multi-directional replication pipelines that span hybrid and multi-cloud environments.
- Enterprise-Grade Observability: Maintain total control with exactly-once processing (E1P), latency metrics, automated recovery, and real-time monitoring dashboards.
Stop settling for static backups and start building a real-time data foundation. Book a demo today to see how Striim can modernize your MongoDB replication, or get started for free to test your first pipeline.
FAQs
What are the key challenges enterprises face with MongoDB replication at scale?
As data volumes grow, natively scaling MongoDB clusters becomes operationally complex. Enterprises often run into replication lag under heavy write loads, which causes stale data for downstream applications. Additionally, native tools struggle with cross-cloud replication and lack the built-in transformation capabilities needed to feed modern cloud data warehouses effectively.
How does Change Data Capture (CDC) improve MongoDB replication compared to native tools?
Native replication is primarily designed for high availability and disaster recovery strictly within the database ecosystem. Log-based CDC, on the other hand, reads directly from the MongoDB oplog to capture document-level changes in real time. This allows enterprises to stream data to diverse, external targets—like Snowflake or Kafka—without impacting the primary database’s performance.
What’s the best way to replicate MongoDB data into a cloud data warehouse or lakehouse?
The most efficient approach is using a real-time streaming platform equipped with log-based CDC. Instead of relying on periodic batch ETL jobs that introduce hours of latency, CDC continuously streams changes as they happen. Tools like Striim also allow you to flatten complex JSON documents in-flight, ensuring the data is relational and query-ready the moment it lands in platforms like BigQuery or Databricks.
How can organizations ensure low-latency replication across multiple regions or cloud providers?
While native MongoDB replica sets can span regions, they can suffer from network strain and lag in complex hybrid environments. By leveraging a unified integration platform, enterprises can optimize real-time replication pipelines across distributed architectures. This approach actively pushes fresh data to regional read-replicas or secondary clouds with sub-second latency, ensuring global users experience instantaneous performance.
What features should enterprises look for in a MongoDB data replication solution?
When evaluating replication software, prioritize log-based CDC to minimize source database impact and guarantee low latency. The solution must offer in-flight data transformation (like filtering, masking, and JSON flattening) to prepare data for analytics instantly. Finally, demand enterprise-grade observability—including exactly-once processing (E1P) guarantees and real-time latency monitoring—to ensure data integrity at scale.
How does Striim’s approach to MongoDB replication differ from other third-party tools?
Striim combines continuous CDC with a powerful, in-memory streaming SQL engine, meaning data isn’t just moved, it’s intelligently transformed in-flight. Recent industry studies show that 61% of leaders cite a lack of integration between systems as a major blocker to AI adoption. Striim solves this by enabling complex joins, PII masking, and vector embedding generation before the data reaches its target, providing an enterprise-ready architecture that scales horizontally to process billions of events daily.
Can Striim support compliance and security requirements when replicating MongoDB data?
Absolutely. Striim supports teams to meet compliance regulations like GDPR or HIPAA by applying in-stream data masking and filtering. This means sensitive Personally Identifiable Information (PII) can be obfuscated or entirely removed from the data pipeline before it is stored in a secondary region or cloud. Furthermore, Striim’s comprehensive auditability and secure connections ensure your data movement remains fully governed.


