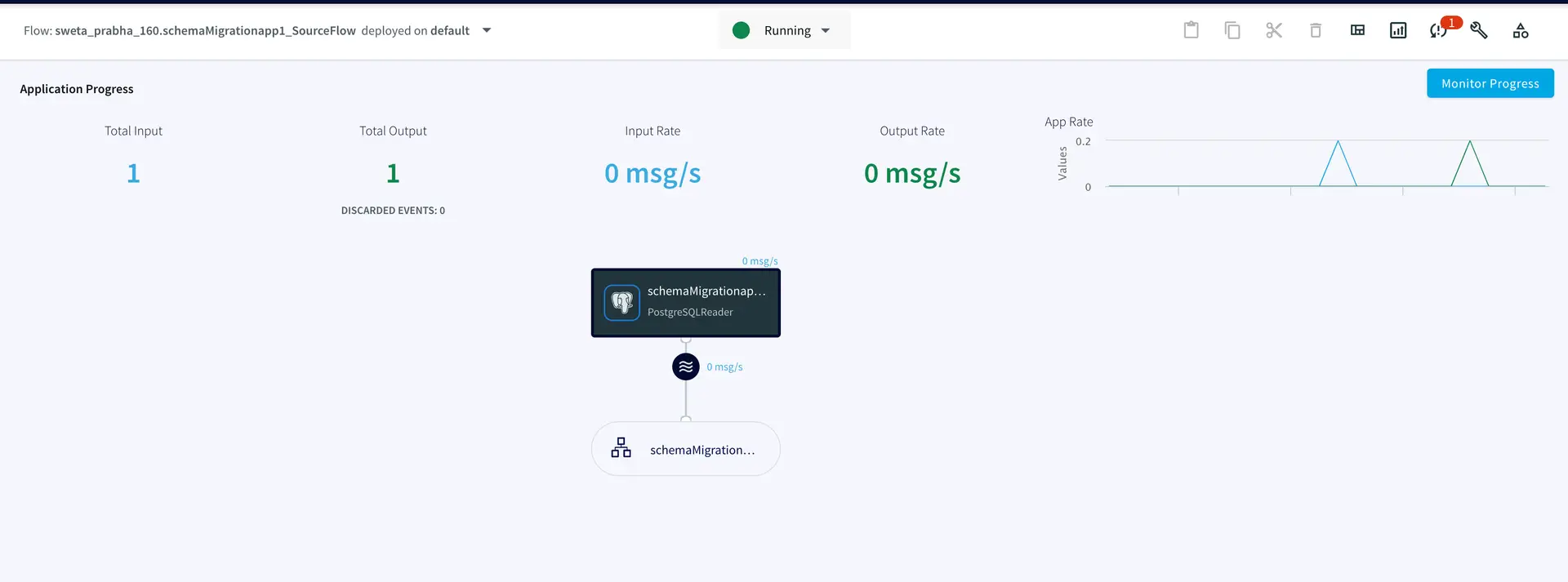
Running the Streaming App before Failover
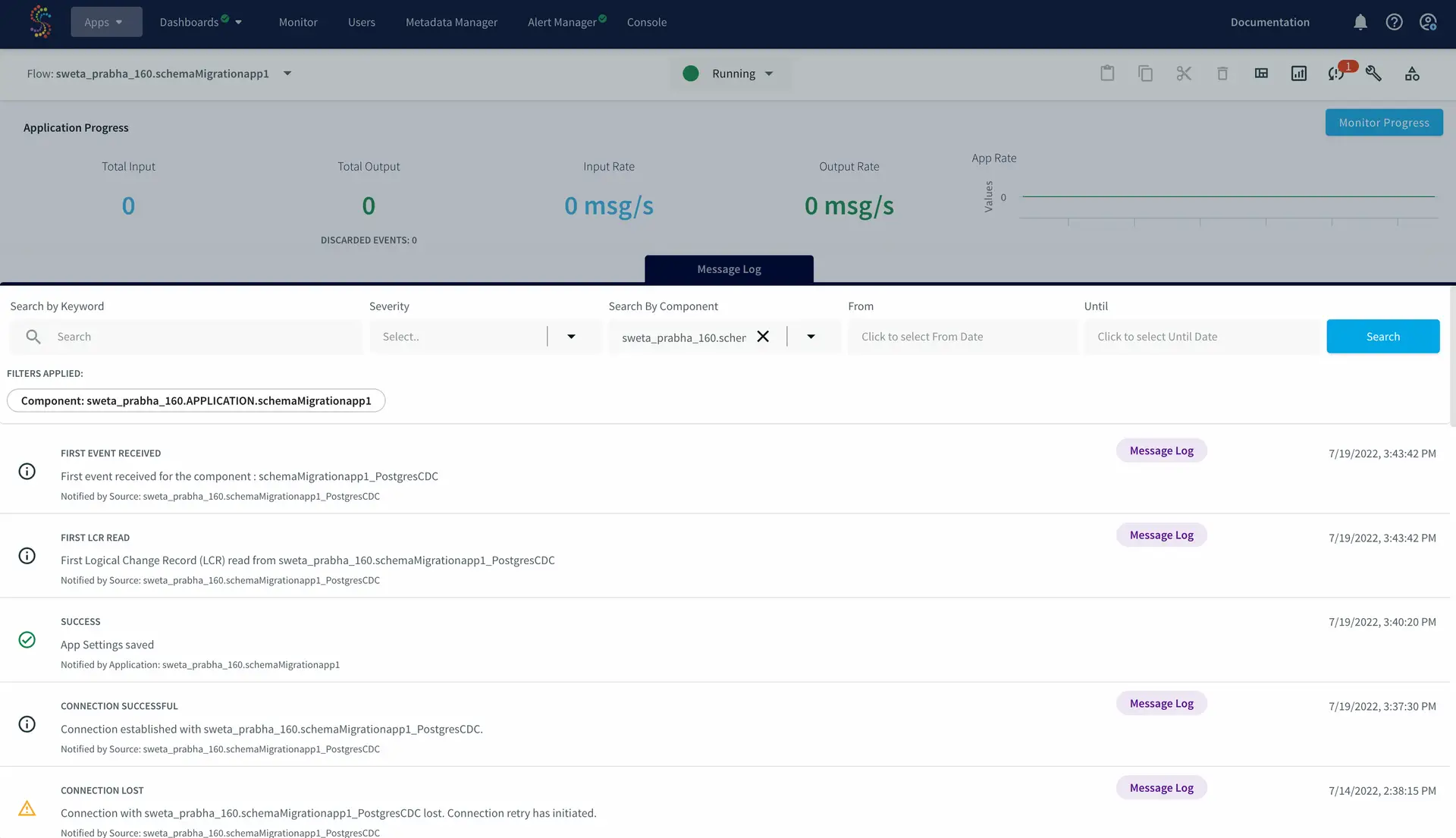
The postgres CDC to Snowflake streaming application is deployed and run. When one row is inserted to the source table, it is replicated into the target table.
Running the Streaming App after Failover
When a failover occurs, the app stops and the last checkpoint is recorded. When recovery is enabled, DatabaseWriter uses the table specified by the Checkpoint Table property to store information used to ensure that there are no missing or duplicate events after recovery.
The failover occurred after the first row was replicated to target table:
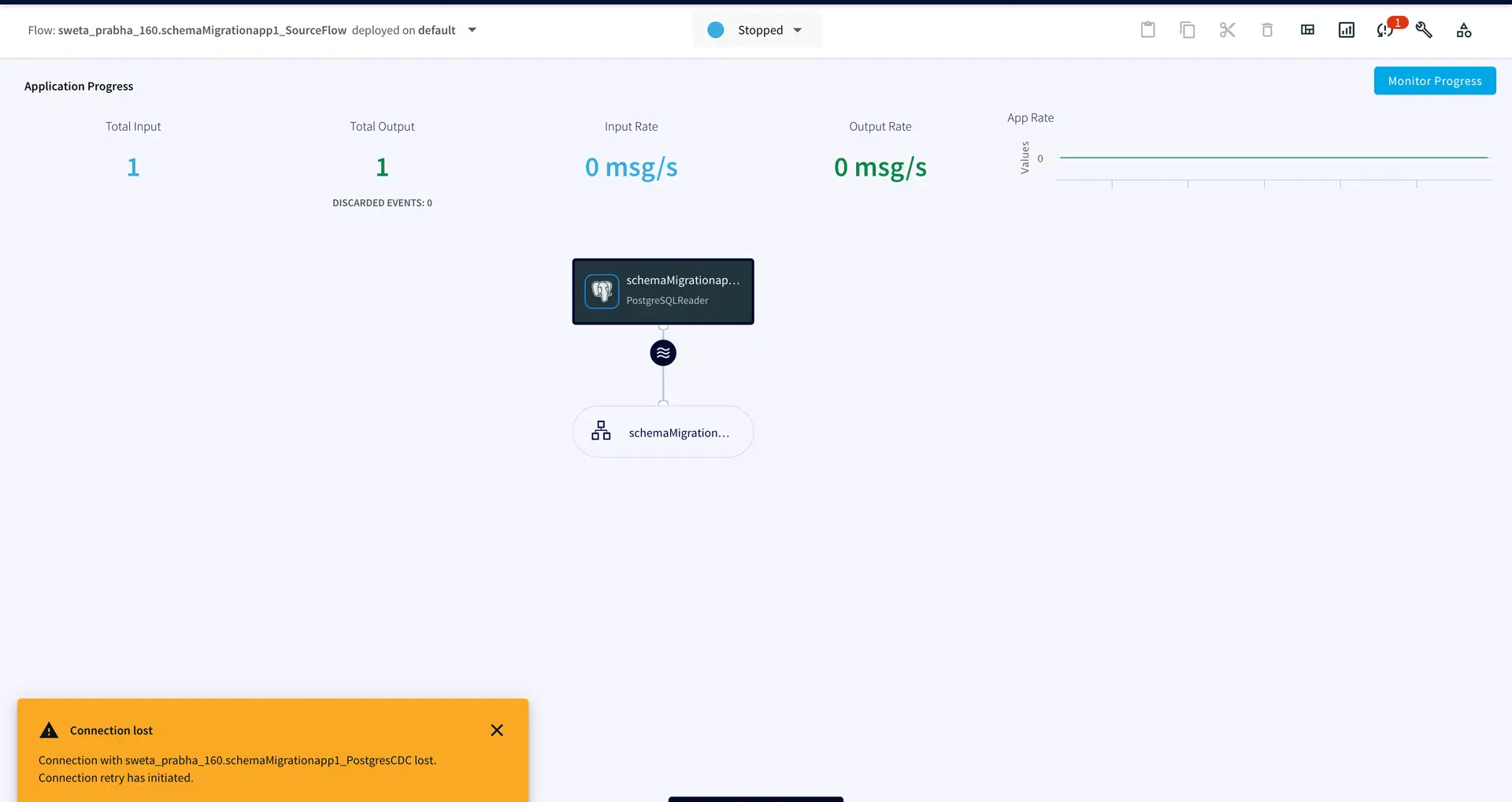
When the app is restarted, it takes some time to start from where the application left off:
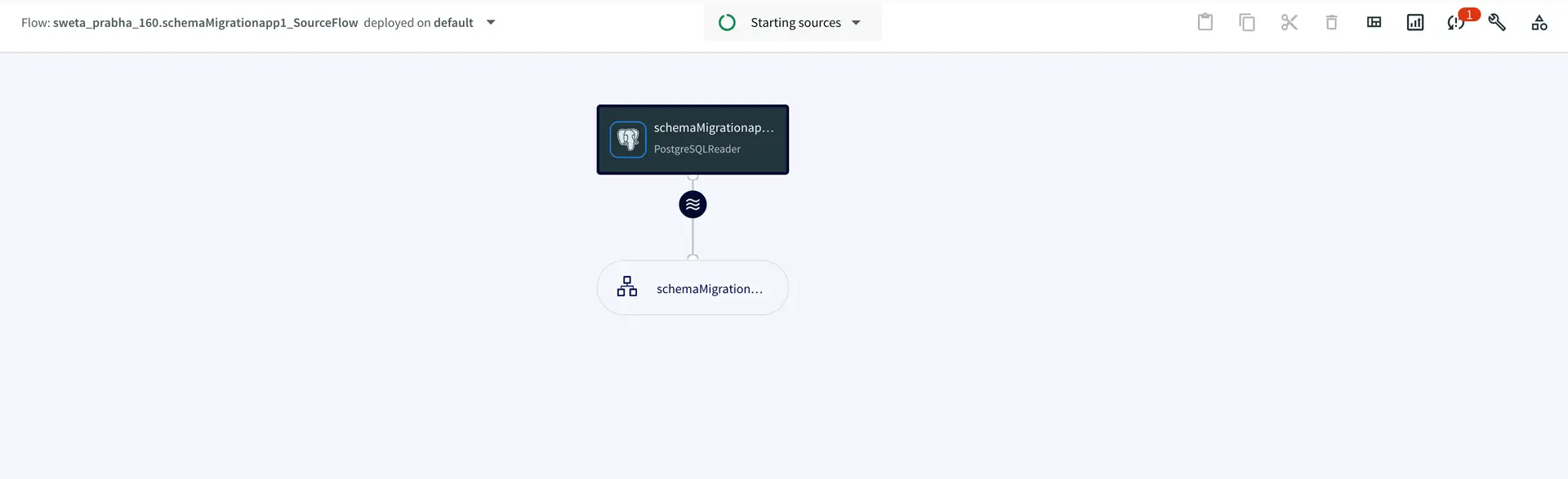
During failover, two more rows were added to the source table which was picked up by the striim app and once the server was up, two more rows were replicated to the target table.
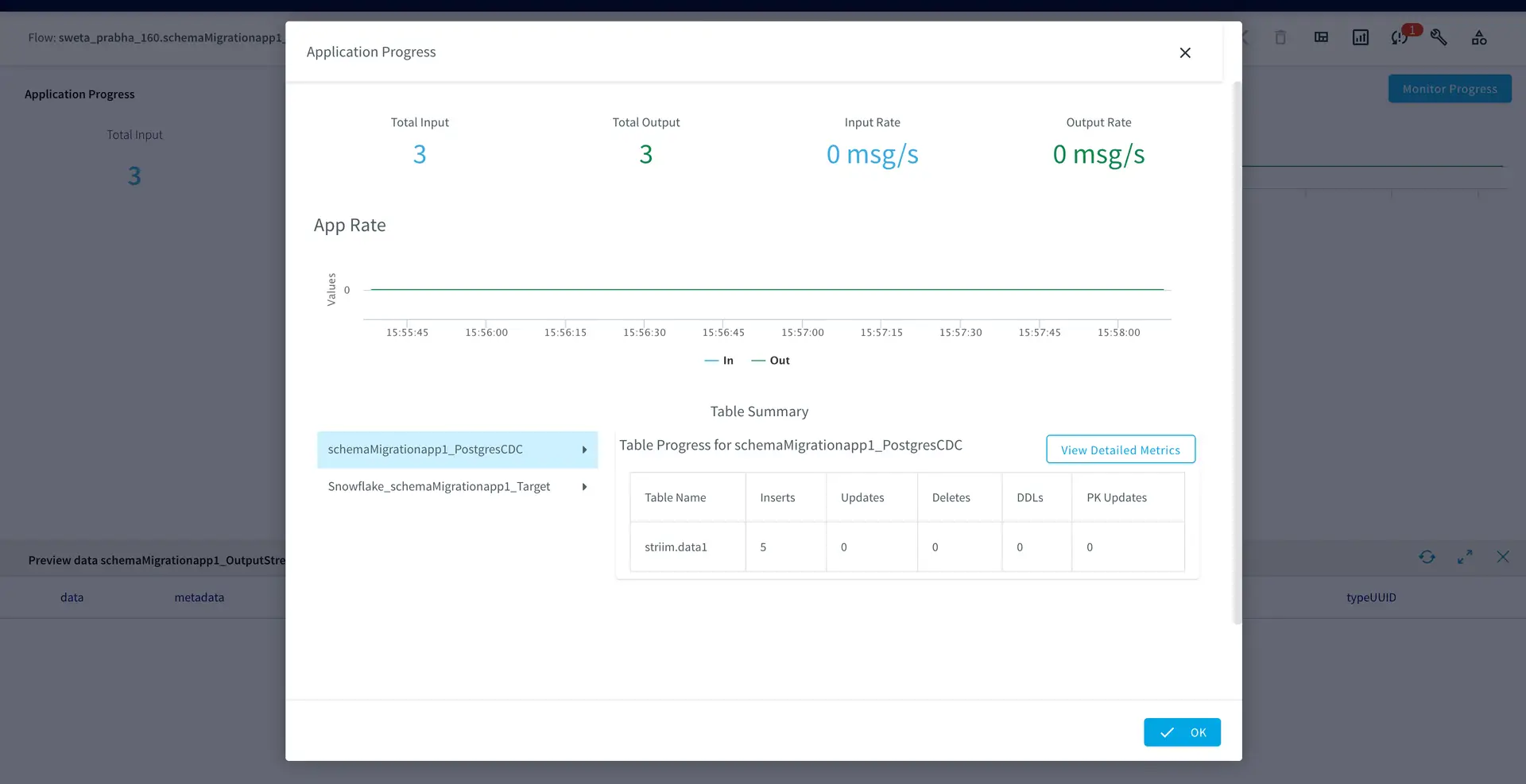
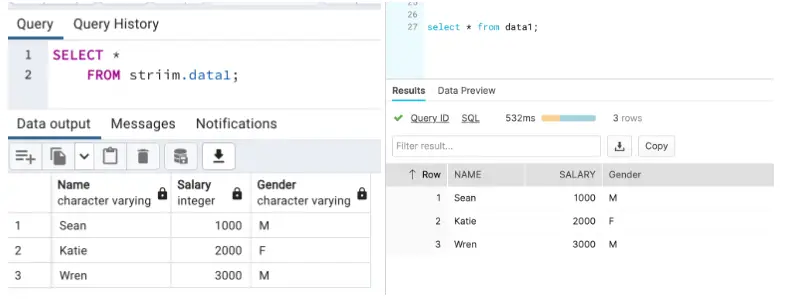
The following snapshots show the source (Postgres) and target (Snowflake) tables and we can see there is no repetition on the target table even though the app started after a failover.
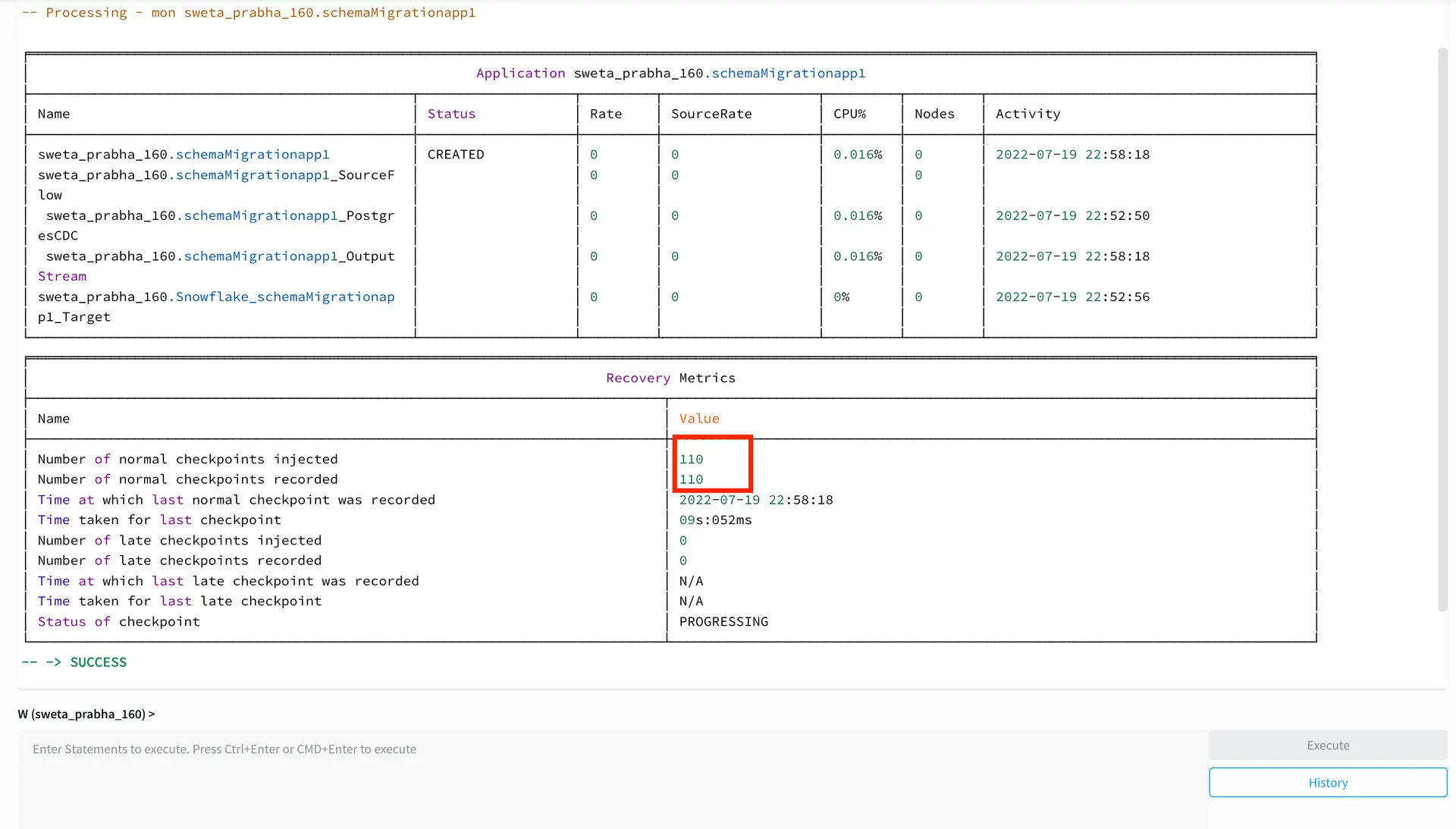
You can also monitor the checkpoint with console commands. To see detailed recovery status, enter MON . in the console (see Using the MON command). If the status includes “late” checkpoints, we recommend you Contact Striim support, as this may indicate a bug or other problem (though it will not interfere with recovery).
To see the checkpoint history, enter SHOW . CHECKPOINT HISTORY in the console.

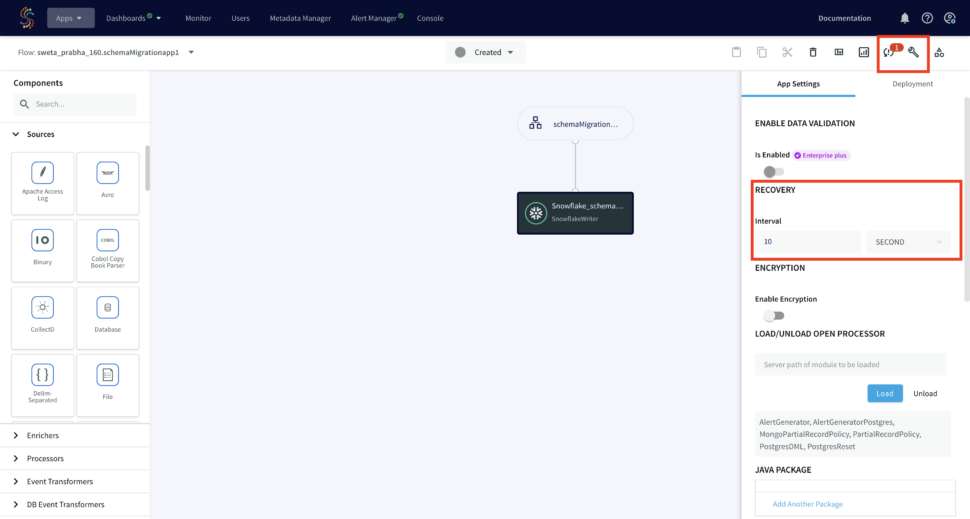
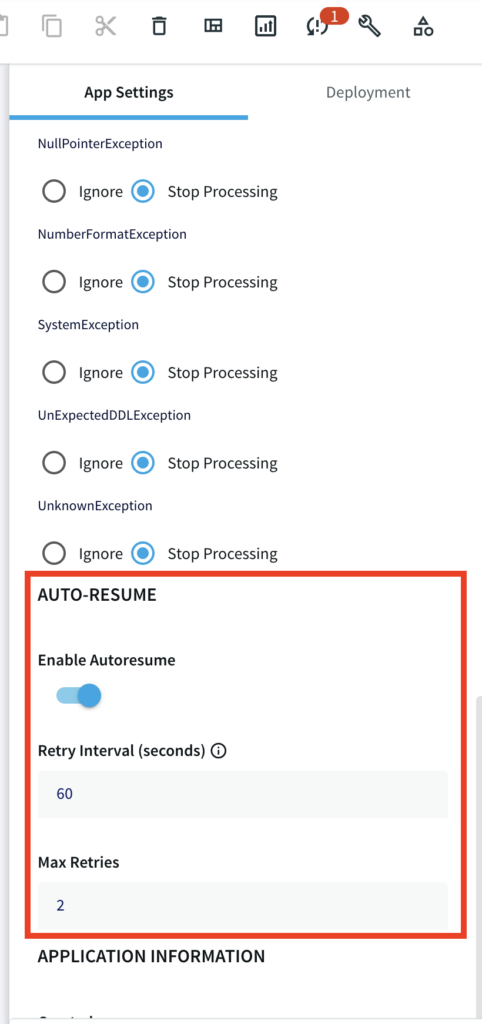
Automatically Restarting an Application after a Crash
If known transient conditions such as network outages cause an application to crash, you may configure it to restart automatically after a set period of time. You can enable auto resume feature with desired retry interval and maximum retries under App Setting in the flow design as follows:

Striim
Striim’s unified data integration and streaming platform connects clouds, data and applications.
PostgreSQL
PostgreSQL is an open-source relational database management system.

Snowflake
Snowflake is a cloud-native relational data warehouse that offers flexible and scalable architecture for storage, compute and cloud services.