What is Real-Time Stream Processing?
In today’s fast-moving world, companies need to glean insights from data as soon as it’s generated. Perishable, real-time insights help companies improve customer experience, manage risks and SLAs effectively, and improve operational efficiencies in their organizations.
To access real-time data, organizations are turning to stream processing. There are two main data processing paradigms: batch processing and stream processing. How are they different, and what are some use cases for each approach?
Batch processing: data is typically extracted from databases at the end of the day, saved to disk for transformation, and then loaded in batch to a data warehouse.
Batch data integration is useful for data that isn’t extremely time-sensitive. Electric bills are a relevant example. Your electric consumption is collected during a month and then processed and billed at the end of that period.
Stream processing: data is continuously collected and processed and dispersed to downstream systems. Stream processing is (near) real-time processing.
Real-time data processing has many use cases. For example, online brokerage platforms need to present fresh data at all times; even a slight delay could prove disastrous in a fast-moving trade.
Streaming-first data integration, or streaming integration, is all about real-time data movement. Between continuous real-time collection of data, and its delivery to enterprise and cloud destinations, data has to move in a reliable and scalable way. And, while it is moving, data often has to undergo processing to give it real value through transformations and enrichment. There are architectural and technology decisions every step of the way – not just at design time, but also at run time.
So what are the best practices for real-time data movement using stream processing? How do you create reliable and scalable data movement pipelines? Here are 6 best practices for real-time stream processing to enable real-time decision making.
Best Practices for Real Time Stream Processing
1. Take a streaming-first approach to data integration
The first, and most important decision is to take a streaming first approach to integration. This means that at least the initial collection of all data should be continuous and real-time. Batch or microbatch-based data collection can never attain real-time latencies and guarantee that your data is always up-to-date. Technologies like change data capture ( CDC ), and file tailing need to be adopted to ensure your data is always fresh.
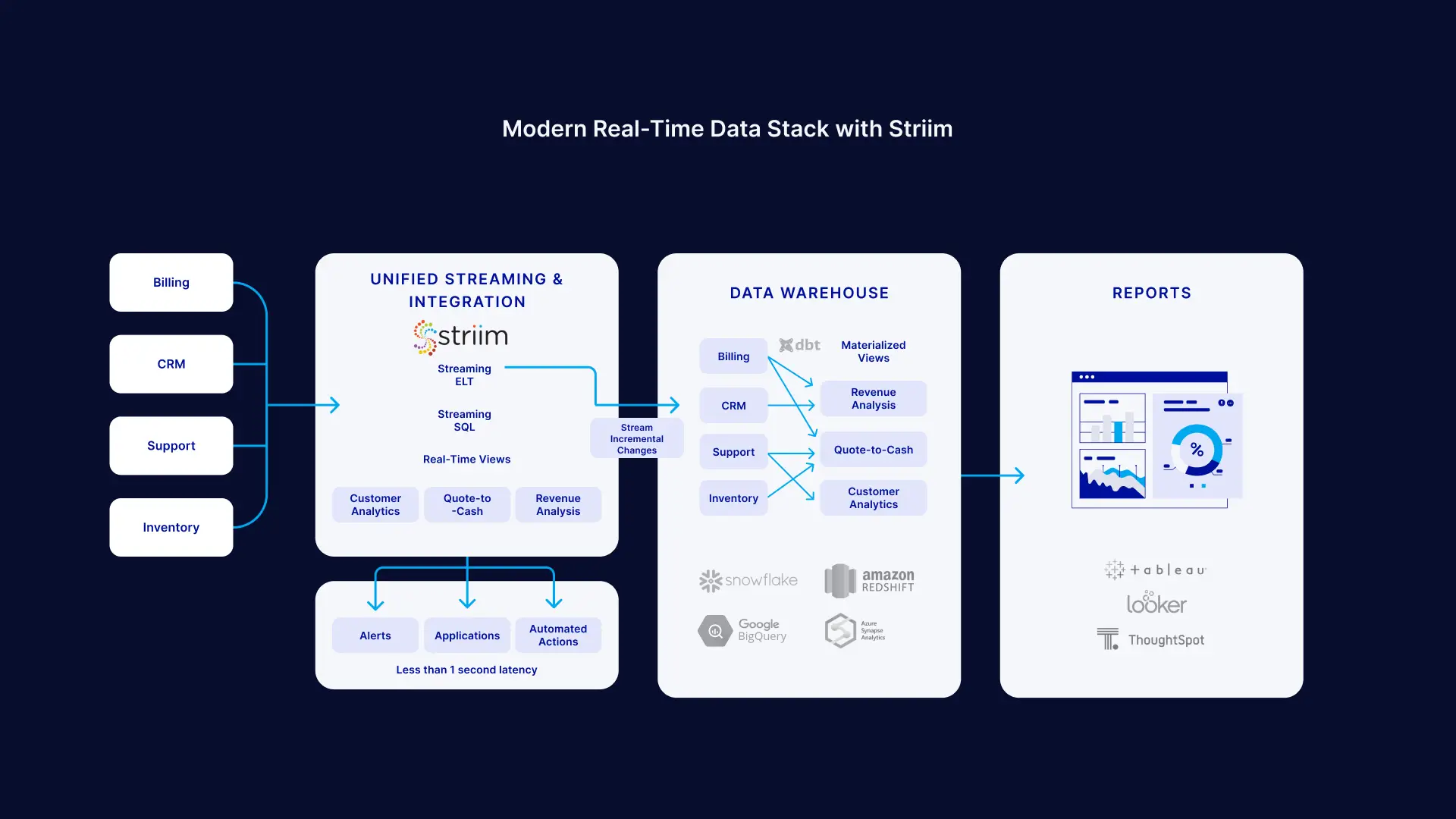
2. Analyze data in real-time with Streaming SQL
Many reporting and analytics use cases can be addressed with reports that refresh every 30 minutes or a longer period of time. However, some business and operational use cases require data to be served to end users in near-real-time. Attempting to do this on a data warehouse (cloud or on-premises) can be prohibitively expensive and cause major performance issues.
Streaming SQL and real-time views allow you to run SQL queries on data that can process millions of events in real-time. With real-time stream processing you can process and analyze data within milliseconds of collecting the data before loading the data to a warehouse for traditional reporting uses.
Machine learning analysis of streaming data supports a range of use cases including predictive analytics and fraud detection. And stream processing allows you to train machine learning models in real-time.
Achieving top performance with Streaming SQL is critical to meet business and operational objectives for real-time analytics. For reference, Striim’s Tungsten Query Language (Streaming SQL processor) is 2-3x faster than Kafka’s KSQL processor:
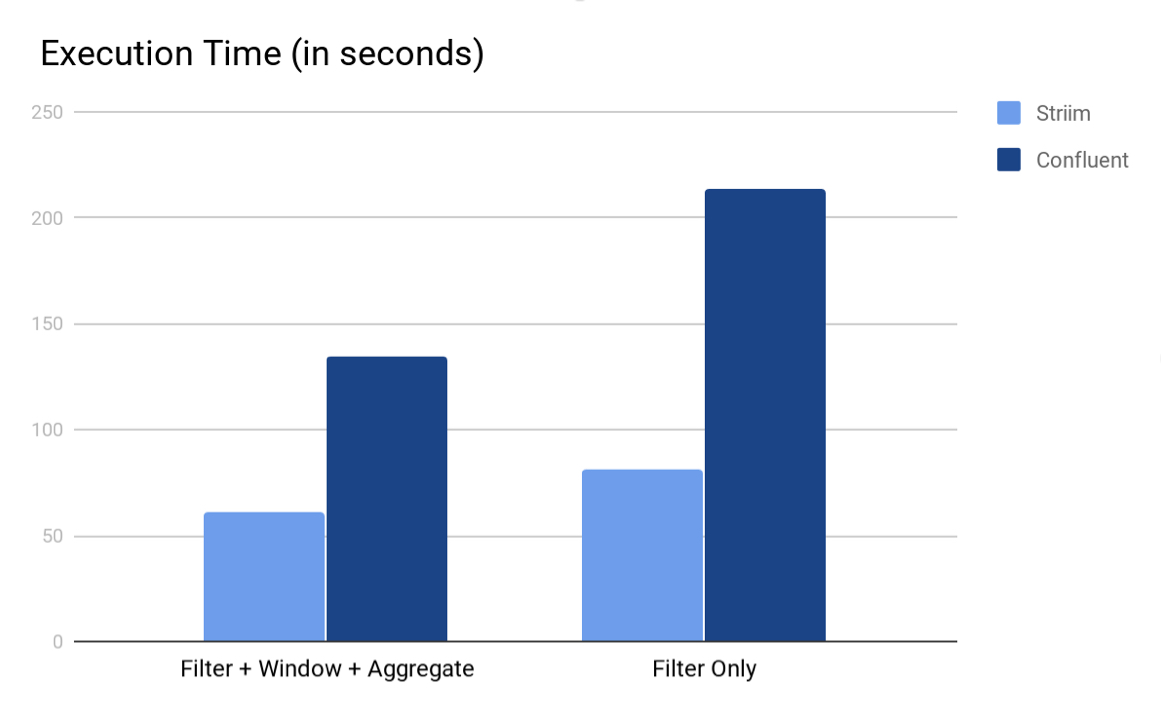
Learn more about Striim’s benchmark here.
3. Move data at scale with low latency by minimizing disk I/O
The whole point of doing real-time data movement and real-time processing is to deal with huge volumes of data with very low latency. If you are writing to disk at each stage of a data flow, then you risk slowing down the whole architecture. This includes the use of intermediate topics on a persistent messaging system such as Kafka. These should be used sparingly, possibly just at the point of ingestion, with all other processing and movement happening in-memory.
4. Optimize data flows by using real-time streaming data for more than one purpose
To optimize data flows, and minimize resource usage, it is important that this data is collected only once, but able to be processed in different ways and delivered to multiple endpoints. Striim customers often utilize a single streaming source for delivery into Kafka, Cloud Data Warehouses, and cloud storage, simultaneously and in real-time.
5. Building streaming data pipelines shouldn’t require custom coding
Building data pipelines and working with streaming data should not require custom coding. Piecing together multiple open source components, and writing processing code requires teams of developers, reduces flexibility, and causes maintenance headaches. The Striim platform enables those that know data, including business analysts, data engineers, and data scientists, to work with the data directly using streaming SQL, speeding development and handling scalability and reliability issues automatically.
6. Data processing should operate continuously
Real-time data movement and stream processing applications need to operate continuously for years. Administrators of these solutions need to understand the status of data pipelines and be alerted immediately for any issues.
Continuous validation of data movement from source to target, coupled with real-time monitoring, can provide peace of mind. This monitoring can incorporate intelligence, looking for anomalies in data formats, volumes, or seasonal characteristics to support reliable mission-critical data flows. In addition, modern data pipelines offer self-healing capabilities including automated schema evolution and corrective workflows, and support for long-running transactions.
Start Building Streaming Data Pipelines Today
The Striim real-time data integration platform directly implements all of these best practices, and more, to ensure real-time data streaming best supports hybrid cloud, real-time applications, and fast data use cases. To learn more about the benefits of real-time data movement using Striim, visit our Striim Platform Overview page, schedule a quick demo with a Striim technologist, or test drive Striim today to get your data where you want it, when you want it.


