How to replace batch ETL by event-driven distributed stream processing
Benefits
- Operational Analytics – Use non-intrusive CDC to Kafka to create persistent streams that can be accessed by multiple consumers and automatically reflect upstream schema changes
- Empower Your Teams – Give teams across your organization a real-time view of your Oracle database transactions.
- Get Analytics-Ready Data – Get your data ready for analytics before it lands in the cloud. Process and analyze in-flight data with scalable streaming SQL.
Overview
All businesses rely on data. Historically, this data resided in monolithic databases, and batch ETL processes were used to move that data to warehouses and other data stores for reporting and analytics purposes. As businesses modernize, looking to the cloud for analytics, and striving for real-time data insights, they often find that these databases are difficult to completely replace, yet the data and transactions happening within them are essential for analytics. With over 80% of businesses noting that the volume & velocity of their data is rapidly increasing, scalable cloud adoption and change data capture from databases like Oracle, SQLServer, MySQL and others is more critical than ever before. Oracle change data capture is specifically one area where companies are seeing an influx of modern data integration use cases.
To resolve this, more and more companies are moving to event-driven architectures, because of the dynamic distributed scalability which makes sharing large volumes of data across systems possible.
In this post we will look at an example which replaces batch ETL by event-driven distributed stream processing: Oracle change data capture events are extracted as they are created; enriched with in-memory, SQL-based denormalization; then delivered to the Mongodb to provide scalable, real-time, low-cost analytics, without affecting the source database. We will also look at using the enriched events, optionally backed by Kafka, to incrementally add other event-driven applications or services.
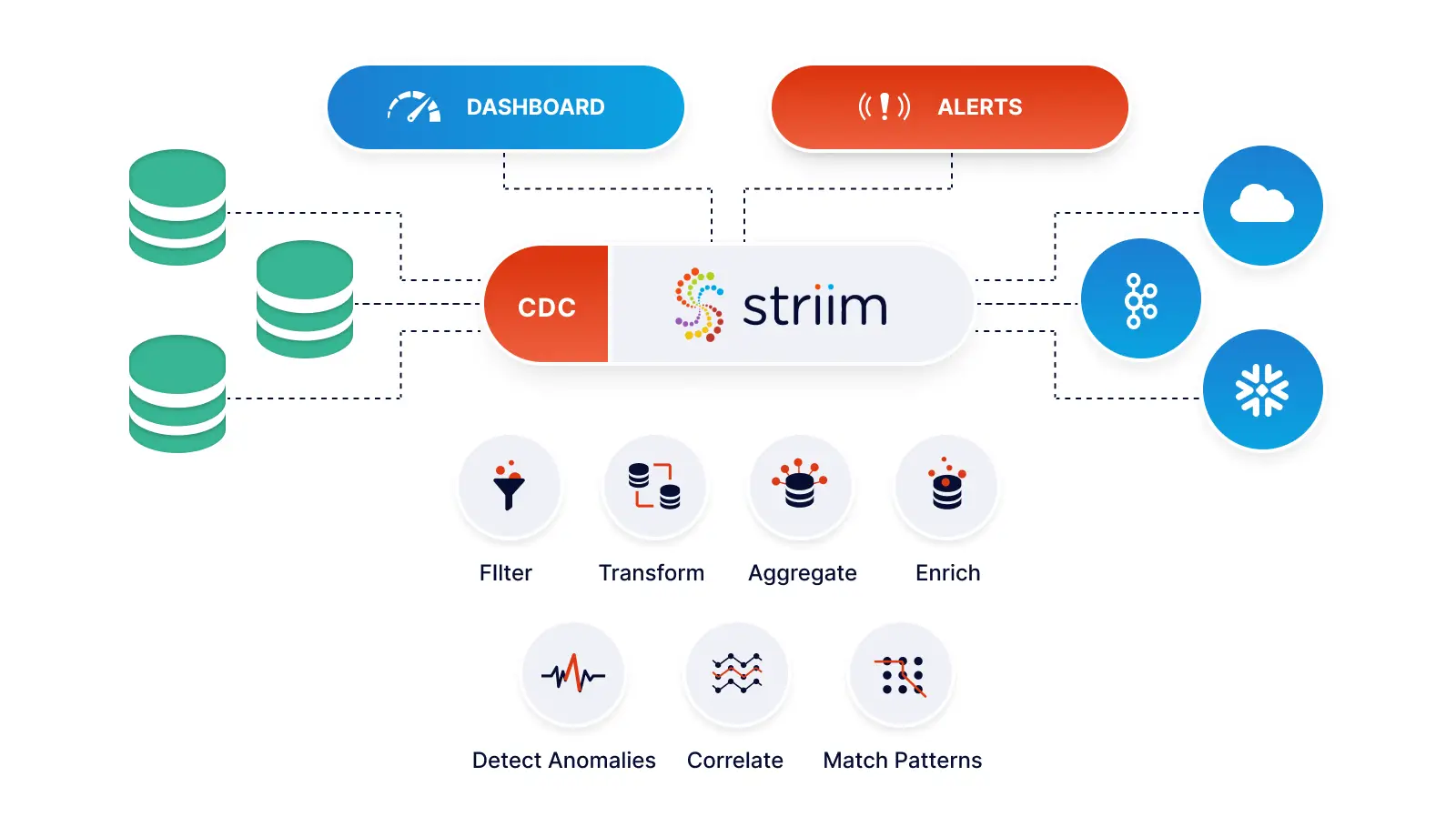
Continuous Data Collection, Processing, Delivery, and Analytics with the Striim Platform
Event-Driven Architecture Patterns
Most business data is produced as a sequence of events, or an event stream: for example, web or mobile app interactions, devices, sensors, bank transactions, all continuously generate events. Even the current state of a database is the outcome of a sequence of events.
Treating state as the result of a sequence of events forms the core of several event-driven patterns.
Event Sourcing is an architectural pattern in which the state of the application is determined by a sequence of events. As an example, imagine that each “event” is an incremental update to an entry in a database. In this case, the state of a particular entry is simply the accumulation of events pertaining to that entry. In the example below the stream contains the queue of all deposit and withdrawal events, and the database table persists the current account balances.
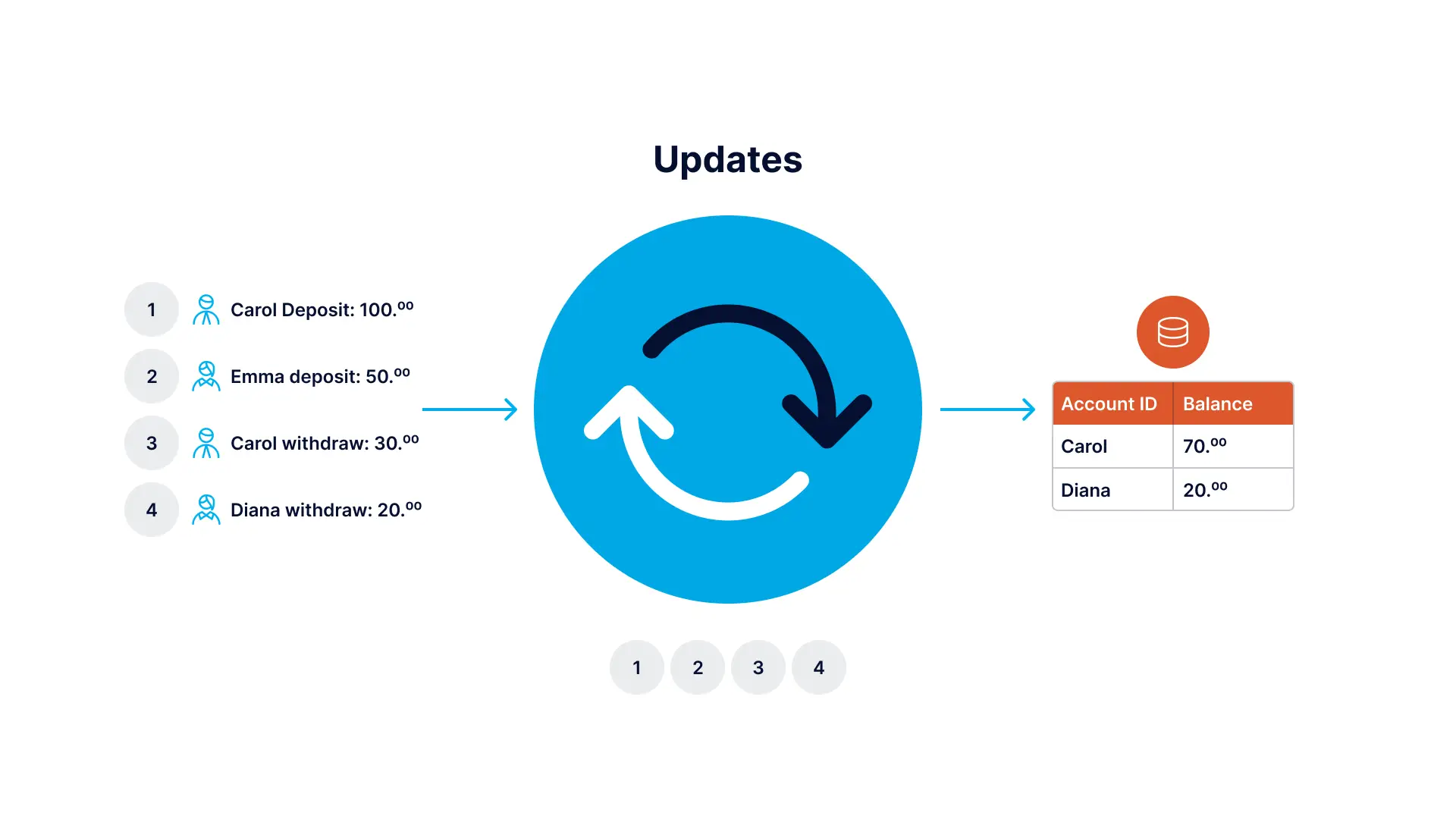
Imagine Each Event as a Change to an Entry in a Database
The events in the stream can be used to reconstruct the current account balances in the database, but not the other way around. Databases can be replicated with a technology called Change Data Capture (CDC), which collects the changes being applied to a source database, as soon as they occur by monitoring its change log, turns them into a stream of events, then applies those changes to a target database. Source code version control is another well known example of this, where the current state of a file is some base version, plus the accumulation of all changes that have been made to it.
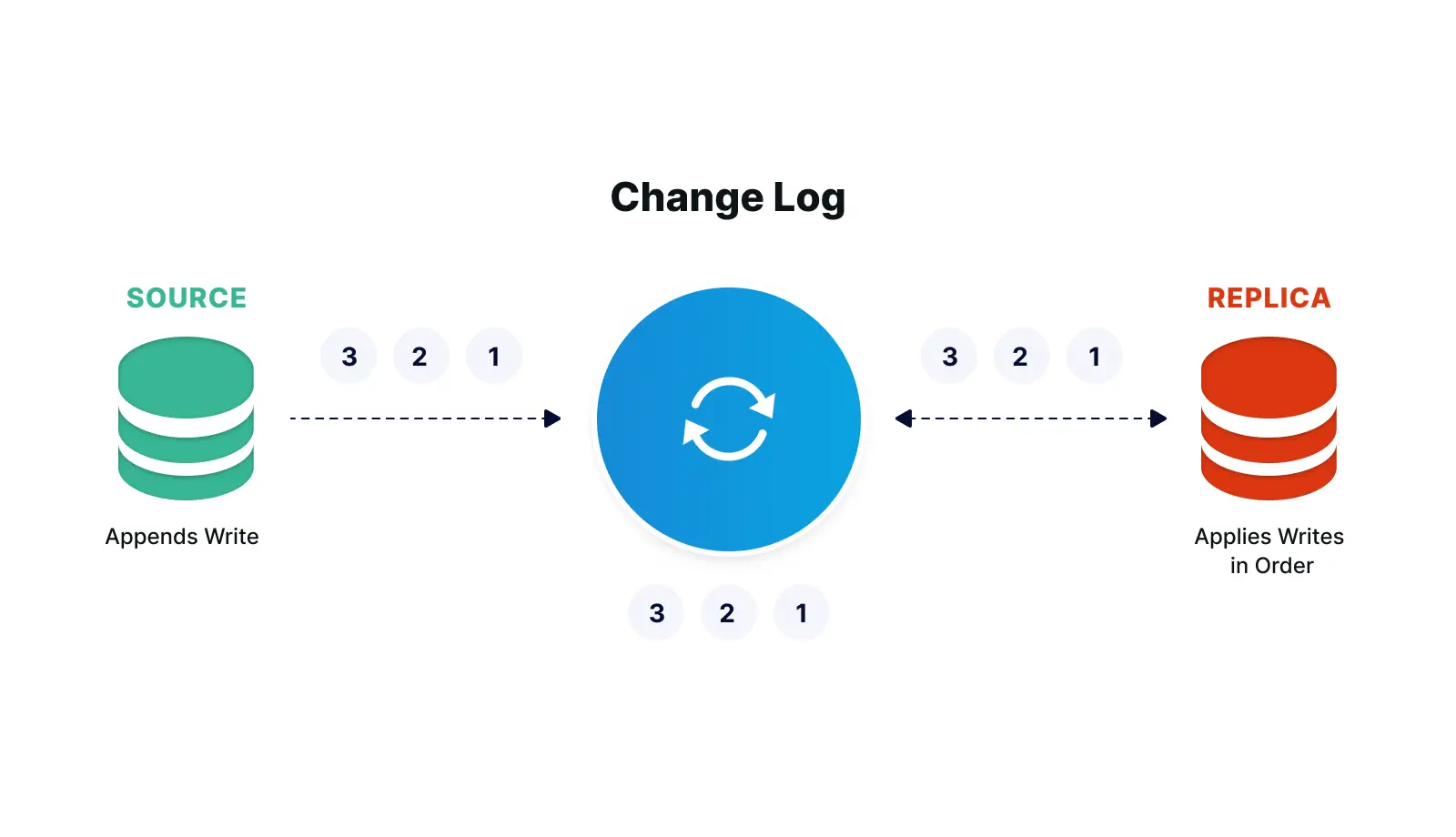
The Change Log can be used to Replicate a Database
What if you need to have the same set of data for different databases, for different types of use? With a stream, the same message can be processed by different consumers for different purposes. As shown below, the stream can act as a distribution point, where, following the polygot persistence pattern, events can be delivered to a variety of data stores, each using the most suited technology for a particular use case or materialized view.
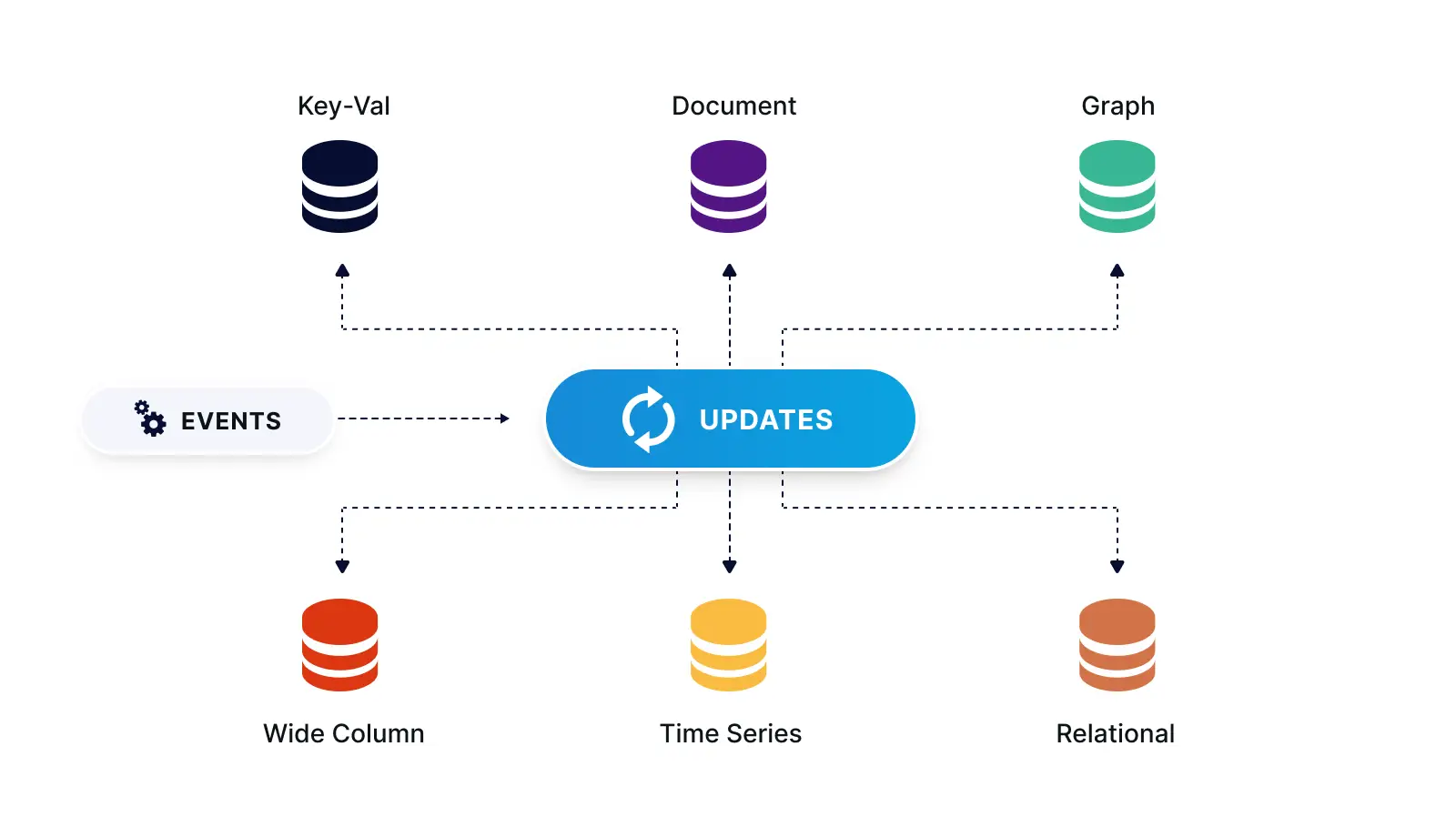
Streaming Events Delivered to a Variety of Data Stores
Event-Driven Streaming ETL Use Case Example
Below is a diagram of the Event-Driven Streaming ETL use case example:
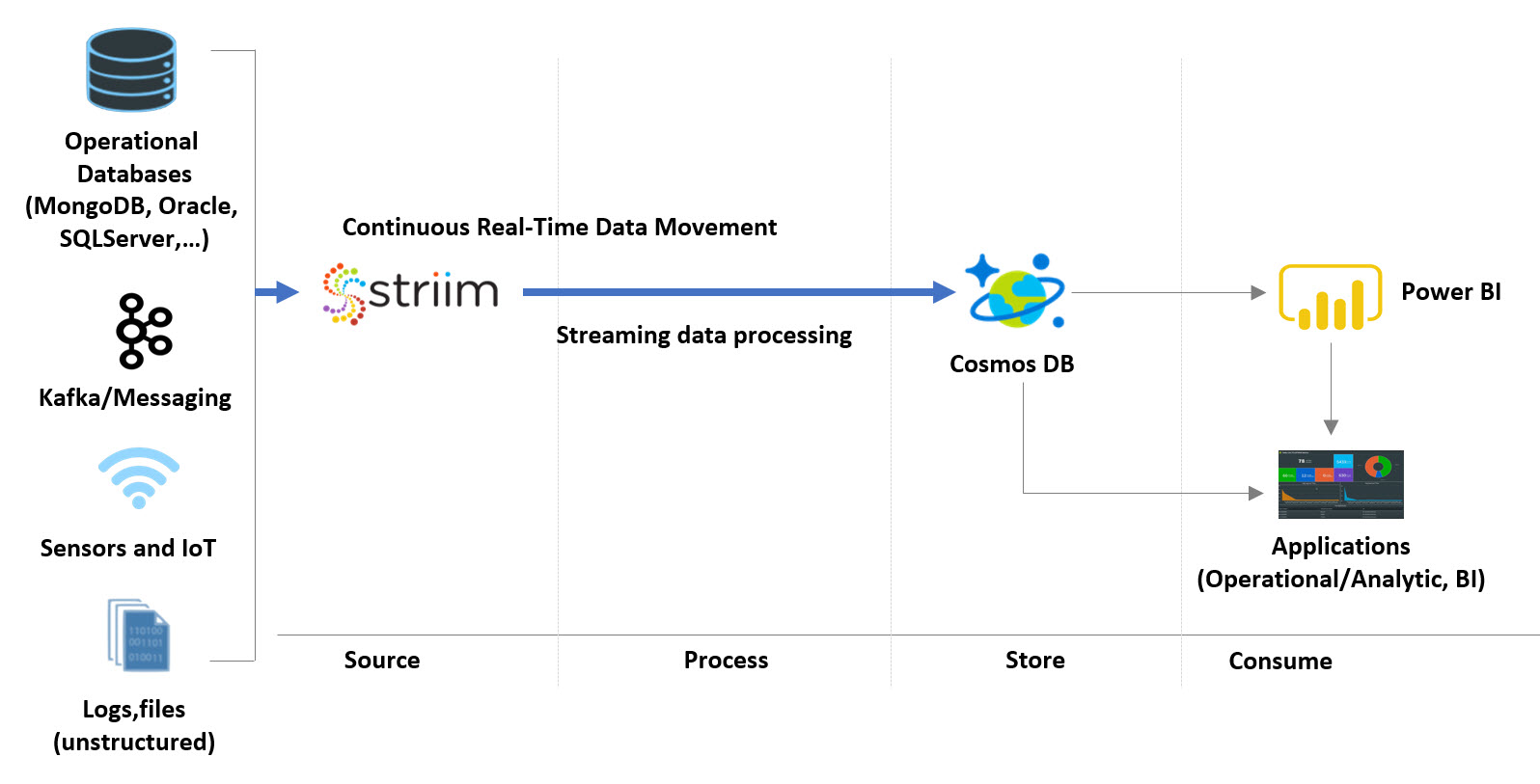
Event-Driven Streaming ETL Use Case Diagram
- Striim’s low-impact, real-time Oracle change data capture (CDC) feature is used to stream database changes (inserts, updates and deletes) from an Operational Oracle database into Striim
- CDC Events are enriched and denormalized with Streaming SQL and Cached data, in order to make relevant data available together
- Enriched, denormalized events are streamed to CosmosDB for real-time analytics
- Enriched streaming events can be monitored in real time with the Striim Web UI, and are available for further Streaming SQL analysis, wizard-based dashboards, and other applications in the cloud. You can use Striim by signing up for free Striim Developer or Striim Cloud trial.
Striim can simultaneously ingest data from other sources like Kafka and log files so all data is streamed with equal consistency. Please follow the instructions below to learn how to build a Oracle CDC to NoSQL MongoDB real-time streaming application:
Step1: Generate Schemas in your Oracle Database
You can find the csv data file in our github repository. Use the following schema to create two empty tables in your source database:
The HOSPITAL_DATA table, containing details about each hospital would be used as a cache to enrich our real-time data stream.
Schema:
Insert the data from this csv file to the above table.
The HOSPITAL_COMPLICATIONS_DATA contains details of complications in various hospitals. Ideally the data is streamed in real-time but for our tutorial, we will import csv data for CDC.
Schema:
Step 2: Replacing Batch Extract with Real Time Streaming of CDC Order Events
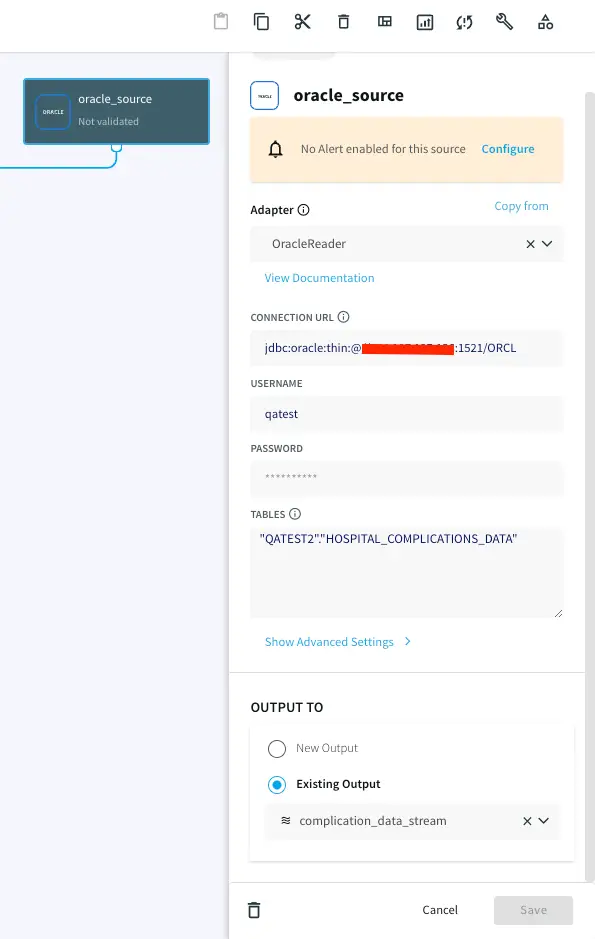
Striim’s easy-to-use CDC wizards automate the creation of applications that leverage change data capture, to stream events as they are created, from various source systems to various targets. In this example, shown below, we use Striim’s OracleReader (Oracle Change Data Capture) to read the hospital incident data in real-time and stream these insert, update, delete operations, as soon as the transactions commit, into Striim, without impacting the performance of the source database. Configure your source database by entering the hostname, username, password and table names.
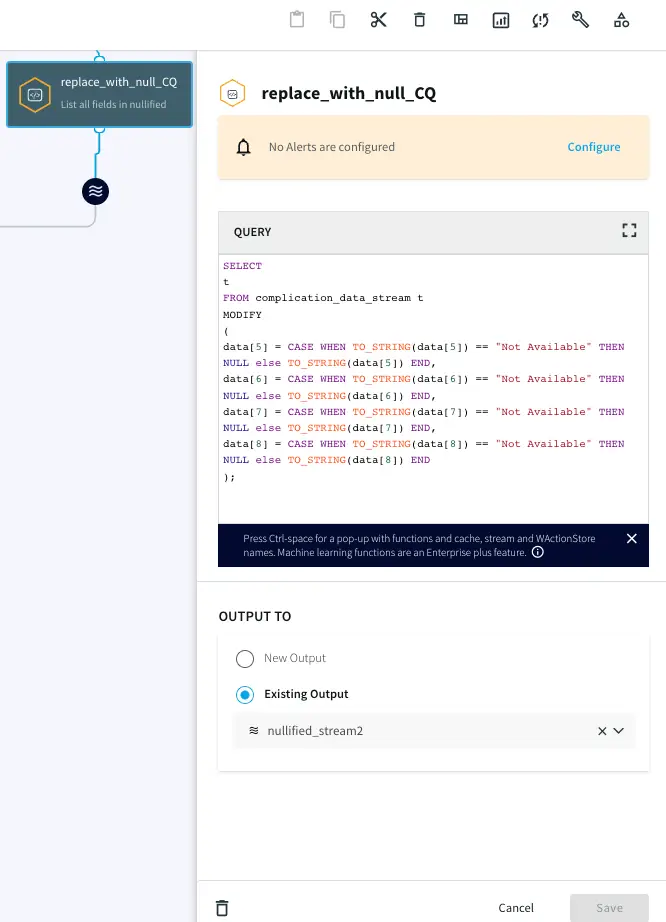
Step 3: NULL Value handling
The data contains “Not Available” strings in some of the rows. Striim can manipulate the data in real-time to convert it into Null values using a Continuous Query component. Use the following query to change “Not Available” strings to Null:
Step 4: Using Continuous Query for Data Processing
The hospital_complications_data has a column COMPARED_TO_NATIONAL that indicates how the particular complication compares to national average. We will process this data to generate a column called ‘SCORE_COMPARISON’ that is in the scale of GOOD, BAD, OUTLIER or NULL and is easier to read. If “Number of Cases too small”, then the SCORE_COMPARISON is “Outlier” and if “worse than national average”, then the SCORE_COMPARISON is BAD otherwise GOOD.
Step 5: Utilizing Caches For Enrichment
Relational Databases typically have a normalized schema which makes storage efficient, but causes joins for queries, and does not scale well horizontally. NoSQL databases typically have a denormalized schema which scales across a cluster because data that is read together is stored together.
With a normalized schema, a lot of the data fields will be in the form of IDs. This is very efficient for the database, but not very useful for downstream queries or analytics without any meaning or context. In this example we want to enrich the raw Orders data with reference data from the SalesRep table, correlated by the Order Sales_Rep_ID, to produce a denormalized record including the Sales Rep Name and Email information in order to make analysis easier by making this data available together.
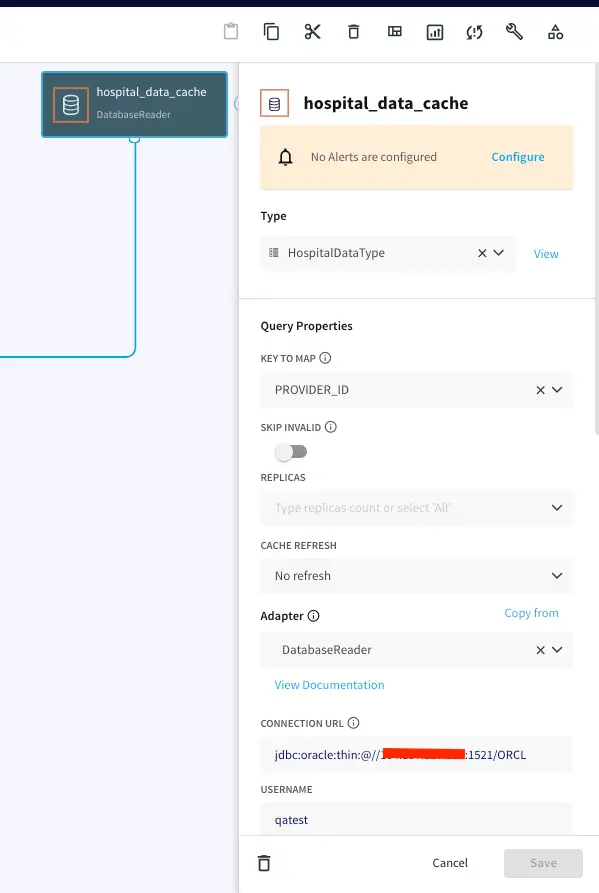
Since the Striim platform is a high-speed, low latency, SQL-based stream processing platform, reference data also needs to be loaded into memory so that it can be joined with the streaming data without slowing things down. This is achieved through the use of the Cache component. Within the Striim platform, caches are backed by a distributed in-memory data grid that can contain millions of reference items distributed around a Striim cluster. Caches can be loaded from database queries, Hadoop, or files, and maintain data in-memory so that joining with them can be very fast. In this example, shown below, the cache is loaded with a query on the SalesRep table using the Striim DatabaseReader.
First we will define a cache type from the console. Run the following query from your console.
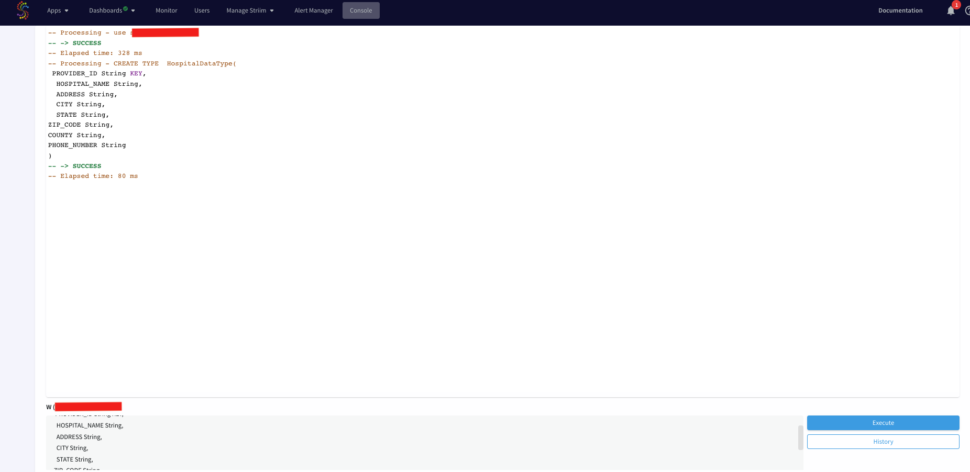
Now, drag a DB Cache component from the list of Striim Components on the left and enter your database details. The table will be queried to join with the streaming data.
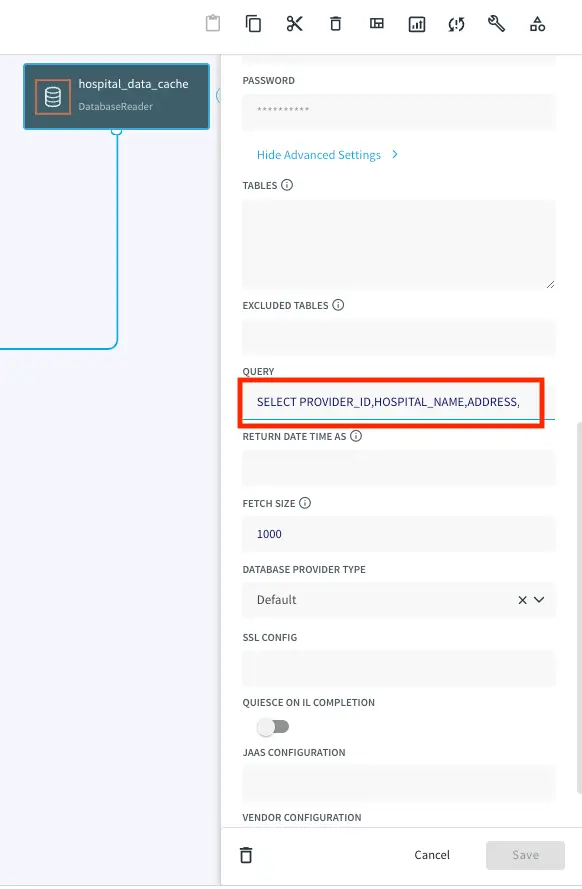
Query:
Step 6: Joining Streaming and Cache Data For Real Time Transforming and Enrichment With SQL
We can process and enrich data-in-motion using continuous queries written in Striim’s SQL-based stream processing language. Using a SQL-based language is intuitive for data processing tasks, and most common SQL constructs can be utilized in a streaming environment. The main differences between using SQL for stream processing, and its more traditional use as a database query language, are that all processing is in-memory, and data is processed continuously, such that every event on an input data stream to a query can result in an output.
This is the query we will use to process and enrich the incoming data stream:
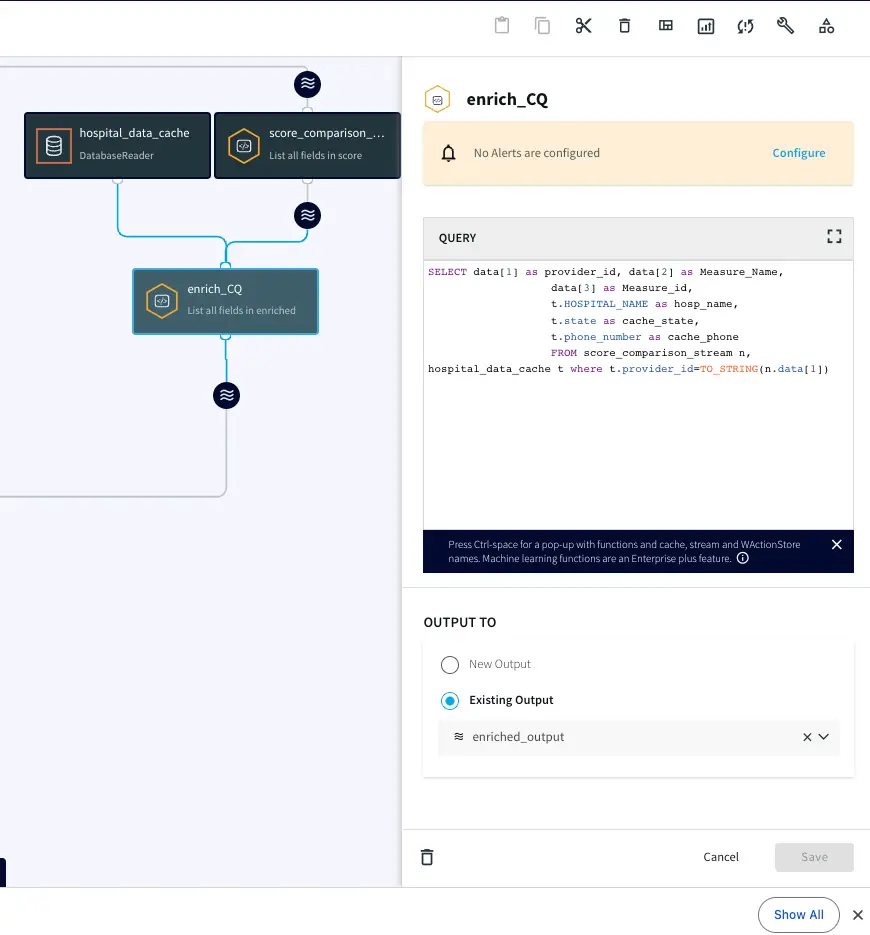
In this query, we enriched our streaming data using cache data about hospital details. The result of this query is to continuously output enriched (denormalized) events, shown below, for every CDC event that occurs for the HOSPITAL_COMPLICATIONS_DATA table. So with this approach we can join streams from an Oracle Change Data Capture reader with cached data for enrichment.
Step 7: Loading the Enriched Data to the Cloud for Real Time Analytics
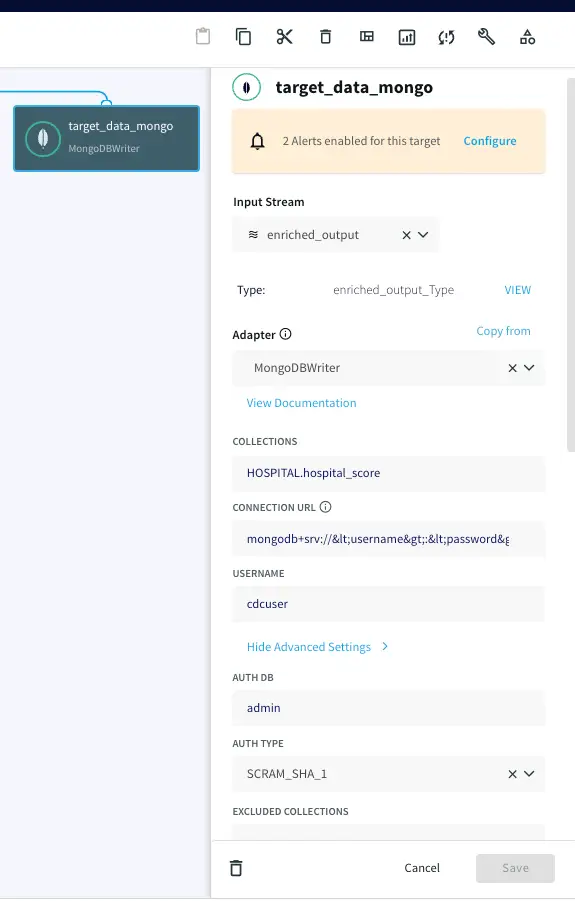
Now the Oracle CDC (Oracle change data capture) data, streamed and enriched through Striim, can be stored simultaneously in NoSQL Mongodb using Mongodb writer. Enter the connection url for your mongodb Nosql database in the following format and enter your username, password and collections name.
mongodb+srv://<username>:<password><hostname>/
Step 8: Running the Oracle CDC to Mongodb streaming application
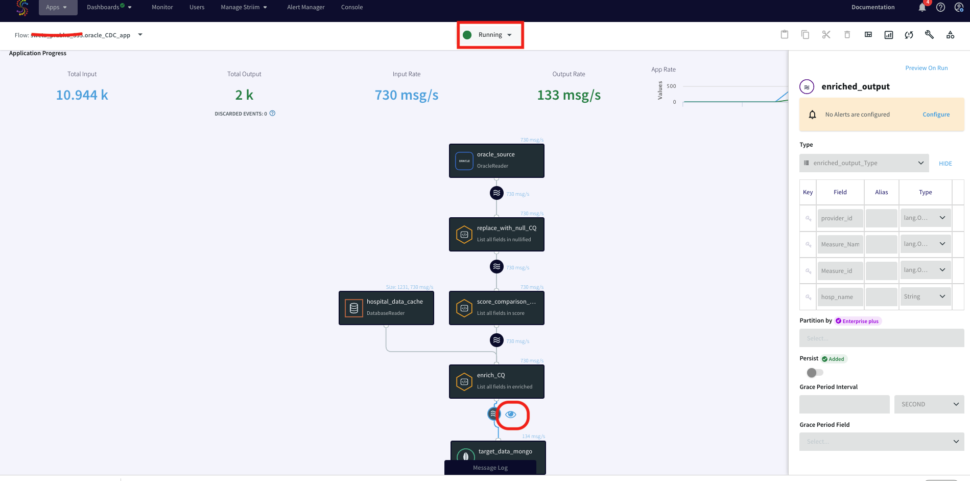
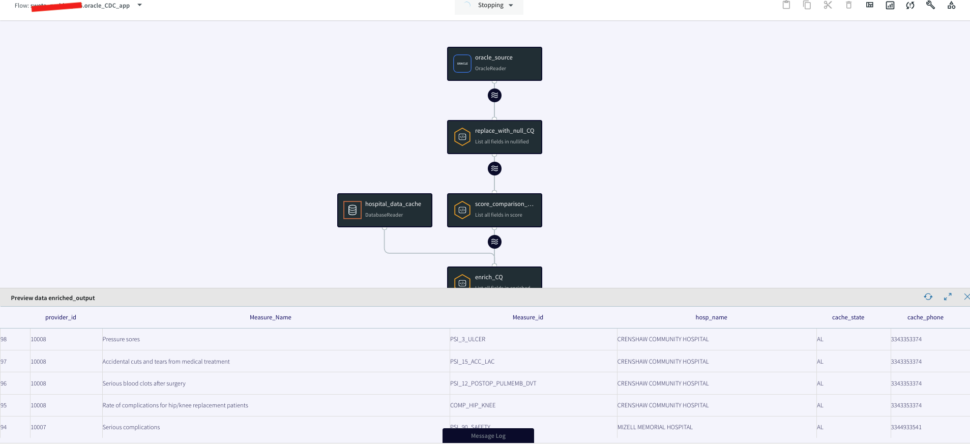
Now that the striim app is configured, you will deploy and run the CDC application. You can also download the TQL file (passphrase: striimrecipes) from our github repository and configure your own source and targets. Import the csv file to HOSPITAL_COMPLICATIONS_DATA table on your source database after the striim app has started running. The Change data capture is streamed through the various components for enrichment and processing. You can click on the ‘eye’ next to each stream component to see the data in real-time.
Using Kafka for Streaming Replay and Application Decoupling
The enriched stream of order events can be backed by or published to Kafka for stream persistence, laying the foundation for streaming replay and application decoupling. Striim’s native integration with Apache Kafka makes it quick and easy to leverage Kafka to make every data source re-playable, enabling recovery even for streaming sources that cannot be rewound. This also acts to decouple applications, enabling multiple applications to be powered by the same data source, and for new applications, caches or views to be added later.
Streaming SQL for Aggregates
We can further use Striim’s Streaming SQL on the denormalized data to make a real time stream of summary metrics about the events being processed available to Striim Real-Time Dashboards and other applications. For example, to create a running count of each measure_id in the last hour, from the stream of enriched orders, you would use a window, and the familiar group by clause.
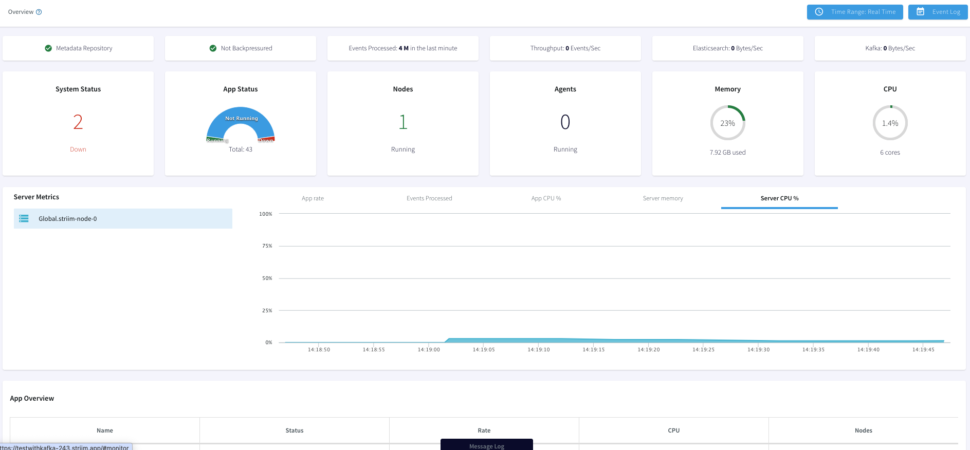
Monitoring
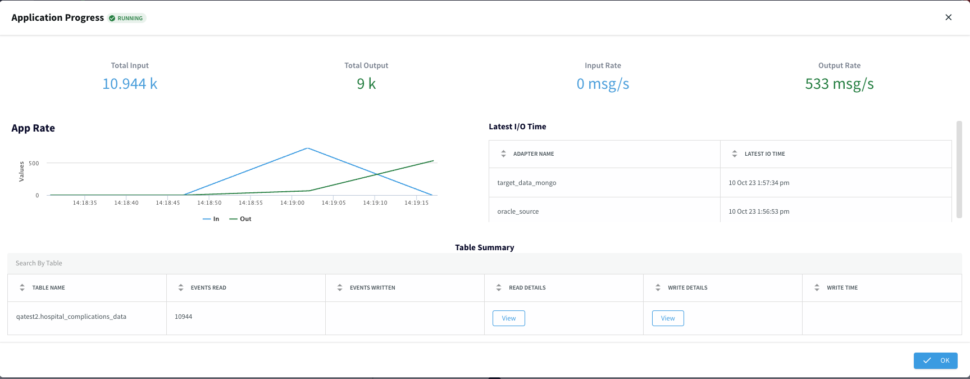
With the Striim Monitoring Web UI we can now monitor our data pipeline with real-time information for the cluster, application components, servers, and agents. The Main monitor page allows to visualize summary statistics for Events
Processed, App CPU%, Server Memory, or Server CPU%. Below the Monitor App page displays our App Resources, Performance and Components.
Summary
In this blog post, we discussed how we can use Striim to:
- Perform Oracle Change Data Capture to stream data base changes in real-time
- Use streaming SQL and caches to easily denormalize data in order to make relevant data available together
- Load streaming enriched data to Mongodb for real-time analytics
- Use Kafka for persistent streams
- Create rolling aggregates with streaming SQL
- Continuously monitor data pipelines
Wrapping Up
Striim’s power is in its ability to ingest data from various sources and stream it to the same (or different) destinations. This means data going through Striim is held to the same standard of replication, monitoring, and reliability.
In conclusion, this recipe showcased a shift from batch ETL to event-driven distributed stream processing. By capturing Oracle change data events in real-time, enriching them through in-memory, SQL-based denormalization, and seamlessly delivering to the Azure Cloud, we achieved scalable, cost-effective analytics without disrupting the source database. Moreover, the enriched events, optionally supported by Kafka, offer the flexibility to incrementally integrate additional event-driven applications or services.
To give anything you’ve seen in this recipe a try, sign up for our developer edition or sign up for Striim Cloud free trial.



