










This reliability post is the fourth blog in a six-part series on making In-Memory Computing Enterprise Grade. Read the entire series:
- Part 1: overview
- Part 2: data architecture
- Part 3: scalability
- Part 4: reliability
- Part 5: security
- Part 6: integration
For mission-critical Enterprise applications, Reliability is an absolutely requirement. In-memory processing and data-flows should not stop, and should guarantee processing of all data. In many cases it is also imperative that results are generated once-and-only-once, even in the case of failure and recovery. If you are doing distributed in-memory of processing, data will be partitioned over many nodes. If a single node fails, the system not only needs to pick up from where it left off, it also needs to repartition over remaining nodes, recover state, and know what results have been written where.
Data Ingest
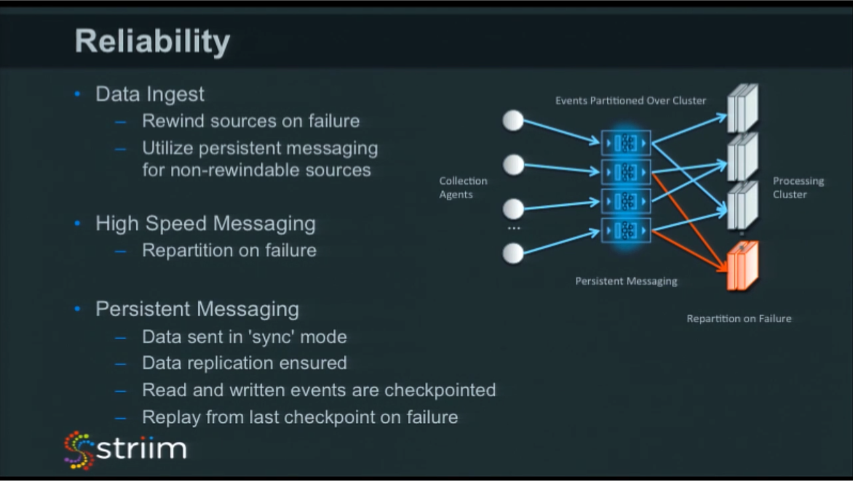
On the data ingest side, we use a checkpointing mechanism for reliability. In general, there are two different approaches to reliability in a distributed in-memory architecture:
- continuous journaling and state transfer
- periodic checkpointing and reply
In the first case, every time something changes, you log what changed, and then you transfer those logs to another machine so you have at least two copies of those logs. Then, if something fails, you can restart from the logs. You can reload state, windows state, or other query state into memory.
We didn’t go this route. Instead we implemented a periodic checkpointing approach. We keep track of all the events that we process and how far they got down various data pipelines. If something fails, we know what the last known good state was, and what position we need to recover from.
The biggest issue we had to solve related to windows. If you have defined data windows (for example, the last five minutes), how do you reload those windows so that they are in a consistent state when you start up? You can’t just say, “start from where you left off” because that will yield an empty data window. You don’t have the last five minutes worth of data, and your results are going to be incorrect. What you need to do is rewind sources on failure. Rewind to a position so that it will start and fill up all those windows in the right place, and then you start your processing. This problem is even more difficult in the case of cascading windows.
A lot of the data sources that we support, especially file-based sources, support replaying of data. You can easily rewind to a point in a file and start from that point and play on. With Change Data Capture (CDC), another technology we use, you can rewind the database logs and replay from a certain point.
However, there are whole categories of sources that are non-rewindable, the main one being sensors. If they are continually pushing data out over TCP / UDP / MQTT / HTTP or AMQP, you can’t call back to all those sensors and say “hey sensors, send me all your data again for last five minutes.” First, you can’t talk to them in that way and, second, they probably no longer have that data to send.
In the case of such transient and volatile data, we rely on persistent messaging using a Kafka-based architecture. As things are being ingested, we immediately store them and checkpoint into the persistent messaging. We don’t use that everywhere – especially not with the rewindable sources. But with non-rewindable ones, it’s really essential. When you continually persist the data, if you need to recover, you have all the data available.
High Speed Messaging
Our high-speed messaging layer has been designed to be fast and simple, if you lose a node, we will repartition on failure. For example, imagine sending stocks for a company somewhere, and that node goes down. We will then send that data to a new node in a consistent fashion. If windows are being used we will spot that, and stop rewind and replay the application to ensure no data loss and correct results.
Persistent Messaging
The are two major benefits to using persistent messaging from a reliability perspective:
- It enables previously non-rewindable sources to be replayed from a point in the past
- It decouples multiple data flows that may depend on the same source, since each can maintain their own checkpoints
In order to achieve this, there are a few tricks that we employ in order to get exactly once processing. The hardest bit for us was knowing whether we’d actually sent something before a node went down and it actually made it into the persistent messaging. The approach we took is to have a reader to the same persistent messaging topics that we are writing to. As soon as you put something in, we check to see if it has been written. Now the platform can checkpoint, confident in the knowledge that the data has made it to the persistent queue. Of course, data is also written out between checkpoints, so on restart, we again query the head of the persistent messaging to see what was the last event written. This ensures we output all the data, and only write the data out once.

Metadata / Control IMDG
The metadata and clustering IMDG allows us to watch for node failure, as well as detect application failure and failure of certain services. For example, we have a particular service responsible for starting, stopping, and deploying applications within our platform. That runs on one node. If that node goes down, then we’ll know about it immediately and that service will start up somewhere else within the cluster.
These are things that users shouldn’t have to worry about. They shouldn’t have to manually do any of these things, and they shouldn’t have to do complex configurations to get it working. The servers should really try and take care of themselves when it comes to this level of reliability.
Context IMDG
The in-memory grid that we use for data is inherently replicated. If you lose one node, then you still have the data and it will replicate, adding it to another node. You have full control over the number of replicas from only one to every node. The amount of replication depends on your data size and tolerance for failure.
The crucial thing is that, when you repartition, you repartition the high-speed messaging layer as well. You have to make sure the two happen at the same time so that you’re consistently taking the right events to the right nodes that now have the cache data. This is where the “application control” part of the control IMDG comes into play. In the case of failure, we coordinate the restart to ensure cache repartitioning has occurred prior to sending events, so that the data is available on the right nodes.
Processing
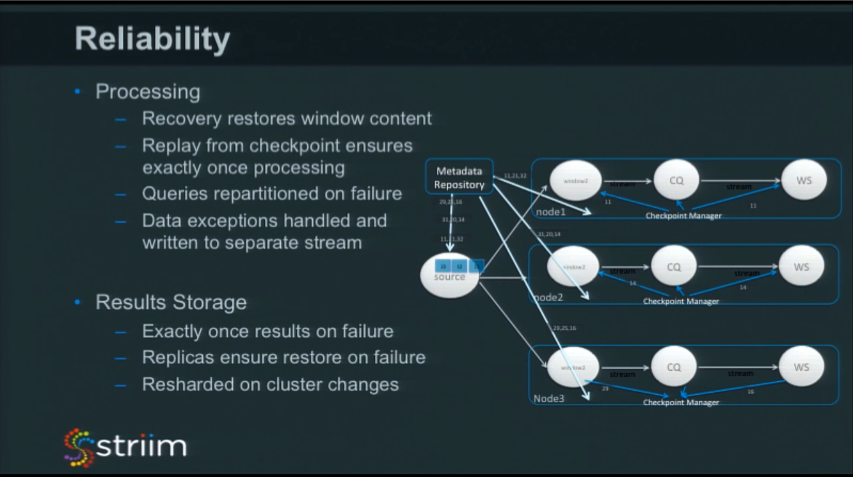
On the processing side, the recovery has to enable the restoration of window content. This can just be filling a five-minute window back up. But what if you had some processing fill the five-minute window? Or you have some other processing that is looking for trends in that five minutes and is writing into a another window, and then that is writing to somewhere else. You have to go all the way back through this chain of windows in order to remember what the state was so you can get it to the right point.
And that’s just the first half of the equation. The second half is to remember what the last event was you saw go out of the window. As you are filling it all back up again, you have to make sure you’re not replicating and regenerating all of these events that you saw previously.
It’s also important you can handle different types of exceptions. If you have hardware problems, then you may get a complete node failure resulting in repartitioning. However, there are other cases where it’s a data issue. Maybe some data is null that you’re trying to access, or there’s a query that’s doing a “divide by zero,” or some other type of data issue. In this case you have to log these issues, and push them into a different data stream so that you can process them separately. If you do see these issues, maybe you want to auto-crash the application and notify the users. This allows you to fix your data, or fix your queries, and restart from where you left off.
Results Storage
We rely on the sharding and replication of elastic search for reliability in our results store. However, we also need to ensure that during recovery we do not repeat results. To achieve this, the platform monitors what we write into the results store and includes details of the last events written as part of the checkpointing information. This ensures that, if we are recovering, we can check what was the last result written and ensure we don’t store the same result again.



