










This security post is the fifth blog in a six-part series on making In-Memory Computing Enterprise Grade. Read the entire series:
- Part 1: overview
- Part 2: data architecture
- Part 3: scalability
- Part 4: reliability
- Part 5: security
- Part 6: integration
Security is another key requirement for making In-Memory Computing Enterprise Grade. Not only do the individual components of an architecture need to be secure, but the overall system needs a single, consistent end-to-end authentication and authorization mechanism to protect data flow components and any external touch-points.
This cannot be an afterthought.
Unfortunately, with many implementations, it often is… especially if you are going from a prototype built using open source technologies to a production environment. Not only do many components of open source not include any security measures (or introduce them late in the game), the security that is available is often at a cost, offered by the vendor supporting that open source technology. Many different components often requires many different vendors, and an integration nightmare to get all the security models to work well together.

For this article I am defining security as “the mechanism by which a system is protected from data corruption, destruction, interception, loss or unauthorized access.” As such, Security covers every aspect of in-memory computing. You need authentication and authorization to provide protection for all resources, and encryption of data and resources where that makes sense.
This is true for all layers of your enterprise data architecture. The mechanisms used to protect and encrypt data ingest and messaging need to work seamlessly with those used during processing.
Data Ingest
If your users are writing some configuration or code to actually get to data (maybe in a database or some other system that is secured), you often need access through passwords or keys. You cannot include these passwords as plain text in code or in some script, so you have to make sure that you secure the passwords, and do so in such a way that they’re hard to crack. You may have seen the news about LinkedIn’s password hack, so please use salt on any encryption of passwords or access keys. It’s really important that you can secure anything users may see that they don’t want anyone else to see.
If you have a platform where many people can work with different sources, it may be necessary to protect a particular source. Maybe there’s wonderful dashboard you’ve created showing summary information about financial transactions happening in the organization in real time that’s being driven by raw data. You may need to give certain people access to the end results, but not to the raw data. In this scenario, you need to be able to secure things differently all along the way and make sure that there’s a single consistent security model across everything.
High-Speed Messaging
For secure transmissions you need to encrypt data on the wire. It’s really important to use modern encryption techniques to ensure everything traveling from one node to another is encrypted. Anything going over the network within an organization is easily accessible, so make sure it’s encrypted to prevent unauthorized access to data streams.
Persistent Messaging
If you’re using a third-party messaging layer (internally we’re using Kafka for persistent messaging), you’ll need to secure that as well. It’s easy for someone to connect to a topic if they know what you’re doing, and then they have access to the full data stream. Again, all critical or PII data needs to be protected so only those permitted can have access. Again, encrypt it and use a nice salted encryption scheme that isn’t easy to to crack, even if you have the code. Within the IMC platform, the priority is to prevent unauthorized access through a common security model. Ideally, it’s tied into your enterprise LDAP architecture, or whatever your existing user management and authentication mechanism is.
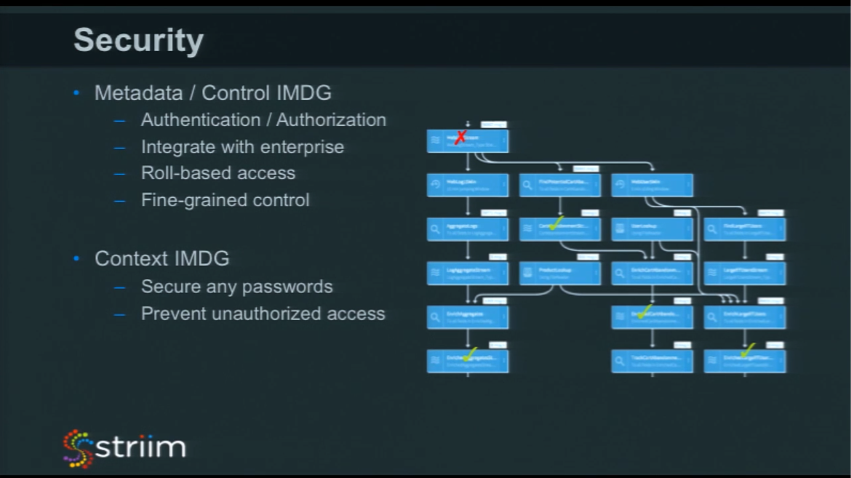
Metadata / Control IMDG
Internally within our platform, we utilize the metadata and control data grid to deal with security. It’s through this layer that people try and access all the individual components. Within this layer we have role-based security with fine-grained access. You can create a general role that says, “you can access applications, or view dashboards,” but within that you can say, “you can access applications but this one stream here, with personally identifiable information in it, you can’t see that.” There’s only one guy they can see that. You need to have a security model broad enough to make it easy to work with, but also can be fine-grained so you can protect data as you need to.
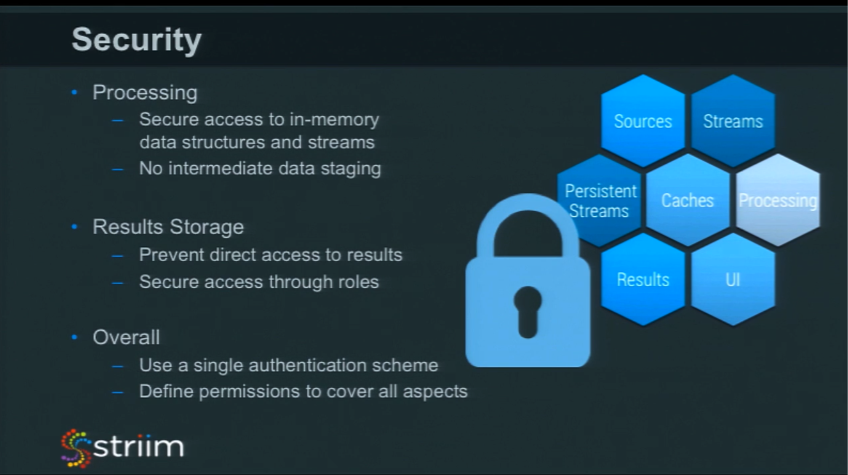
Processing
With data processing, there are some things that you should care about. If you’re using Java code, you can secure some of the Java functions using a security policy. A key objective for an in-memory platform is to avoid intermediate data staging as much as you possibly can. If you’re creating a data pipeline, try not to write intermediate files at each stage of the pipeline. Passing and working with data in-memory is much safer. As soon as things are written to disk, you can encrypt them, but they’re written to disk, so they’re much easier to access. Something that is transient, in-memory, and in-use is going to disappear.
If, like us, you have a querying mechanism against data streams, that mechanism needs to check authorization at the time of query compilation. Users without privileges should not be able to write queries against protected streams.
Overall
The most important thing to remember is that, overall, security should be consistent. Ideally, there would be a single authentication and authorization scheme to protect all aspects of in-memory computing that you are using. Judicious use of encryption for protected resources (like passwords and keys) and for data going over any network is also critical to making your IMC enterprise-grade.




