










This scalability post is the third blog in a six-part series on making In-Memory Computing Enterprise Grade. Read the entire series:
- Part 1: overview
- Part 2: data architecture
- Part 3: scalability
- Part 4: reliability
- Part 5: security
- Part 6: integration
In this blog I am going to talk about Scalability. What might you need to consider to make an In-Memory Computing platform Scalable?
The working definition of Scalability I am going to use is this: “Scalability is a characteristic of a system that describes its capability to cope and perform under an increased or expanding workload.”
In the context of an In-Memory Computing platform, this means that we have to consider scaling of all the components of the data architecture.

Scalability is not just about being able to add additional boxes, or spin up additional VMs in Amazon. It is about being able increase the overall throughput of a system to be able to deal with an expanded workload. This needs to take into account not just an increase in the amount of data being ingested, but also additional processing load (more queries on the same data) without slowing down the ingest. You also need to take into account scaling the volume of data that you need to hold in-memory, and any persistent storage you may need. All of this should happen as transparently as possible without impacting running data flows.
Data Ingest
On the data ingest side, you are looking to to scale up to receive large amounts of data. Striim uses server technology and each server is capable of doing everything we covered in the stack from the architecture blog. You can certainly use servers for data collection, and that works in many cases, but it is a lot of software. Each server is able to hold and process large amounts of in-memory data, and store these high volumes of data on disk.
If you ask people in the enterprise, “Can we put this big server that can do all these things on your web server?” they’ll likely say “No!” because they don’t want something that uses lots of memory, cpu, and storage running on their production web servers. So, in addition to the servers, we have lightweight collection agents designed specifically to be very low-impact. Their only job is collecting and filtering before moving into the rest of the cluster with minimal impact on the endpoints.
If we are talking about IoT, however, things are a little different. With IoT data, not only do you need to collect from many endpoints, you may want to do some additional pre-processing. IoT data can have redundancy, so you may want to strip it out before you move into the rest of the cluster. In those cases, if you’re running data through an IoT gateway, you may want to perform the initial processing before moving it somewhere else.
So, to scale data ingest, you simply add more servers, or lightweight collection agents to your topology. You can start off, for example, streaming data from two of your web servers, and easily scale to hundreds. The High-Speed Messaging layer ensures all that data is collected and distributed across the processing nodes.
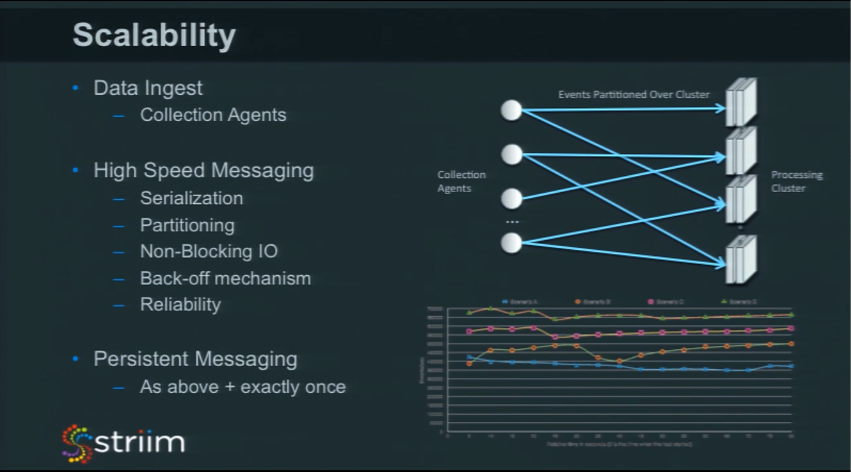
High-Speed Messaging
How can you go about making the high-speed messaging layer scalable? There are a few pieces that you would want to focus on in order to get this to work. The first is serialization of data. When it’s moving from one place to another in the network, it goes across as as bytes (actually fluctuations in electrical signals). In the Java space, serialization is something that can be slow. There’s a number of different serialization libraries out there. It’s worth benchmarking each one, comparing characteristics, and the best way of getting data from one place to another. Striim standardized on Kryo as a serialization layer because it was the fastest thing we found, so we wrote optimized code utilizing Kryo to serialize data really quickly.
Partitioning is also important because when you move data from one place to another, and you’ve set up a number of processing nodes that can process the data, you probably want to partition the data so that it processes the data consistently. An example would be if you had a huge amount of stock trades coming in, you’d want to partition things by ticker symbol so that the same symbol would always land on the same node. That way, you can start doing your aggregates and other calculations on one node without having to worry about your symbol appearing somewhere else. This can cause issues occasionally. You may want to have different levels of partitioning. There was an issue when Facebook went public and the service couldn’t handle it because all the Facebook trades were happening on one node. You may have to consider more advanced partitioning schemes in some circumstances.
Non-blocking IO is another essential part of high-speed messaging. If your processes can’t handle the throughput being sent, and you have a backlog, then you need to somehow back off what you are actually sending in. This might simply be queuing things up earlier, or spilling things to disk before you actually send them out. This helps when the queries in your processing layer are complex and can’t handle the throughput you are trying to throw at them. If that’s the case, you may want to further scale the processing layer to handle the throughput.
Reliability is also an essential part of scalability. If your nodes go down, you need to be able to maintain the throughput that you have, and do so in a consistent way so you don’t lose data.
Persistent Messaging
We use Kafka for persistent messaging, which is inherently designed to scale. However, because it is persistent, if things do go down, then you might find yourself coming back up on another node or restarting. In this scenario, you risk sending the same data again, not knowing you already sent it. You need to be able to ensure you are sending data once and only once, that is, understanding what you’ve actually sent on persistent messaging to make sure you don’t send the same data again.

Metadata / Control IMDG
Metadata can be used to handle clustering and synchronization between nodes, making sure actions happen in the right places within a cluster. This can enable hot clustering so you can add new nodes and it will register itself with the cluster. By default, we utilize the multicast scenario by starting up a server which talks to all the other servers and says, “Hi, I’m here.” Then, there’s a single service that works out what services need to run on what servers. This automates things like additional repartitioning of data, load distribution, and application management when a new server starts up.
We also use the metadata control in-memory data grid for distributing Java bytecode. A fair proportion of the Striim platform works by dynamic generation of Java bytecode – not loading code from jar files – but generating new code in-memory in order to do certain processing. If you’re doing that, then you need to make sure same code exists on all the machines in the cluster and you don’t generate it everywhere. The Striim platform has a distributed ClassLoader built on top of the in-memory data grid that allows you to define a class once that is visible across the whole cluster.
The goal for scalability is to enable clustering and easy addition of nodes, without the user being responsible for complex configuration, or assigning services.
Context IMDG
The in-memory data grid that we use for context is a slightly different beast. In order to get high throughput, you don’t want your context cache to be doing remote lookups. The High-Speed Messaging layer works with the Context IMDG to make sure, when routing an event, it lands on the right node that actually has the data locally, in-memory within that cache. We do this by using a consistent hashing algorithm across the messaging layer and across the cache layer.
This is a little bit more complicated in our platform because we don’t always treat the whole cluster as the place where we are running stuff. When we deploy within our platform, we can choose a subset of the nodes within the cluster to actually run things on. This partitioning of events and data also takes into account this sub-clustering capability. We also must refresh the data that’s in-memory and keep processing going. We do transactional refreshes so we don’t suddenly have an empty cache. We effectively have a working copy in-memory, and a copy that’s being loaded into memory. Once it’s done, then we switch to using the new one.
If you are loading tens of millions of records into memory to add context to streaming data, it is imperative that the cache can scale through partitioning across a number of machines, without slowing the processing throughput.
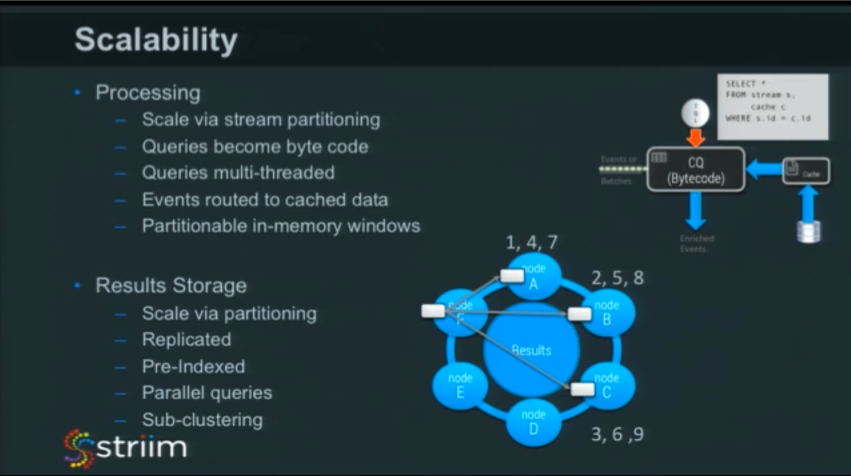
Processing
To scale processing, we rely heavily on stream partitioning because of it’s ability to send data to a particular node in a consistent fashion, based on some partitioning algorithm – some key. This allows us to scale processing of data across a large number of nodes. It works a little like MapReduce because we are mapping out the data to a number of nodes for processing. When we write results, those results are accessible across the cluster.
The queries that people write in data flows built in our platform actually become Java bytecode. We found this more efficient over having a general-purpose query engine. A general-purpose engine, a scripting language, or anything else would be much less efficient than Java bytecode generated specifically for that task.
With all these data streams running, you often want to be able to run queries against a view over the streams, which is called a window. This allows you to ask questions like, “What’s been happening in the last five minutes?” With windowing, you can turn infinite, unending streams into a bounded set that, although it changes all the time, it remains bounded.
These in-memory windows take up memory, so this need to be a consideration in Scalability. If you’re going to scale then you also need to be able to partition your windows across a number of different nodes.
Results Storage
By default, we use Elastic Search for results storage, so many of the features of Elastic Search help us scale. The result is automatically partitioned, replicated, and pre-indexed, so the queries on the stored data happen really fast. We also take into account the fact that we do sub-clustering. Although you may have a whole cluster, say with a hundred machines, you may only choose to write your results to only four of them. Striim is able to handle those situations as well.
Stay tuned for our next blog in the Making IMC Enterprise-Grade series, covering all aspects of Reliability.




