Fortune 500 companies power their cloud initiatives with Striim
Striim vs. Qlik Feature Comparison
Cloud-Scale Architecture
Striim scales horizontally on in-memory compute with high availability and failover for maximum uptime.
Qlik Replicate is a single-node solution. Doesn’t scale horizontally. Must be deployed as a virtual machine. Can deploy in a server cluster to run separate data pipelines but a single pipeline can’t scale across nodes.
Qlik
Real-time Transformations + Analysis
Striim users can build detailed in-flight transformations, data masking, filtering logic using high-speed SQL queries. Striim scales horizontally with in-memory compute for high performance transformations.
Qlik Replicate supports a limited set of pre-defined transformations and basic filters. Qlik doesn’t scale on in-memory compute, therefore scalable in-flight transformations and data processing/analysis aren’t possible.
Qlik
Real-Time Data Visualization Dashboards
Striim offers real-time dashboards visualizing end-to-end data delivery from source to target. Striim matches source and target transactions and alerts users to missing transactions, making it easy to catch issues as they happen.
Striim offers data delivery SLAs and customers see end-to-end latency under 2 seconds.
Qlik Replicate provides a graphical overview of replication tasks, but only provides the table name, number of records loaded, and time when error occurred. This makes it difficult to debug data lag and data loss scenarios.
Qlik
Cloud Partnerships
Striim’s cloud partners include Google, Microsoft, AWS, and Snowflake. Striim partners closely with cloud vendors to support a full breadth of endpoints for a variety of strategic use cases. Striim also supports deployment via metered and SaaS marketplace offerings to take advantage of cloud scalability.
Qlik partners with cloud vendors including Google, Microsoft, and Snowflake, but its solution is not built to take advantage of the scalability of the cloud. Offers limited technical integration with cloud partners.
Qlik
Striim offers a modern data platform that's both powerful and easy to use.
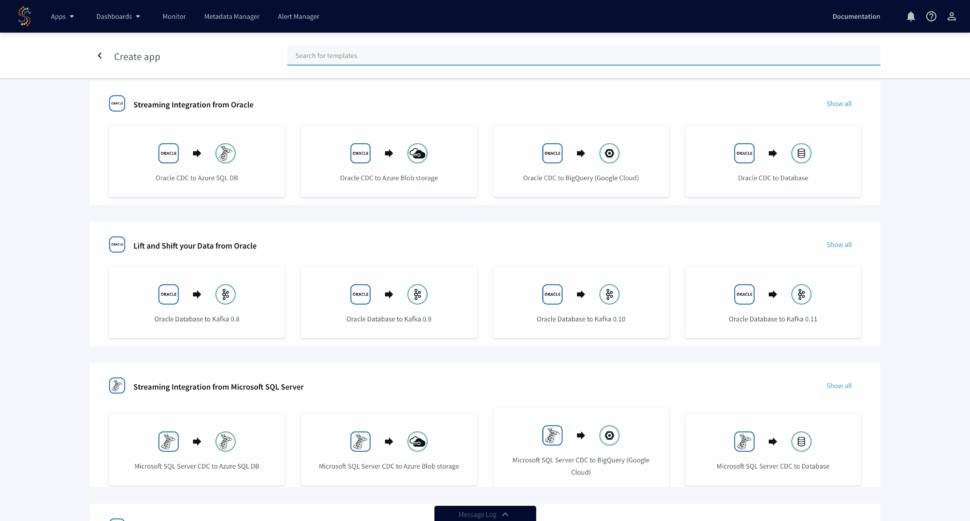
Simplify Data Flows
Select from hundreds of templates to simplify building your data flows. A step-by-step wizard will lead you through the process of connecting to your source and target to create a data flow application. You can also create custom data flows from scratch.
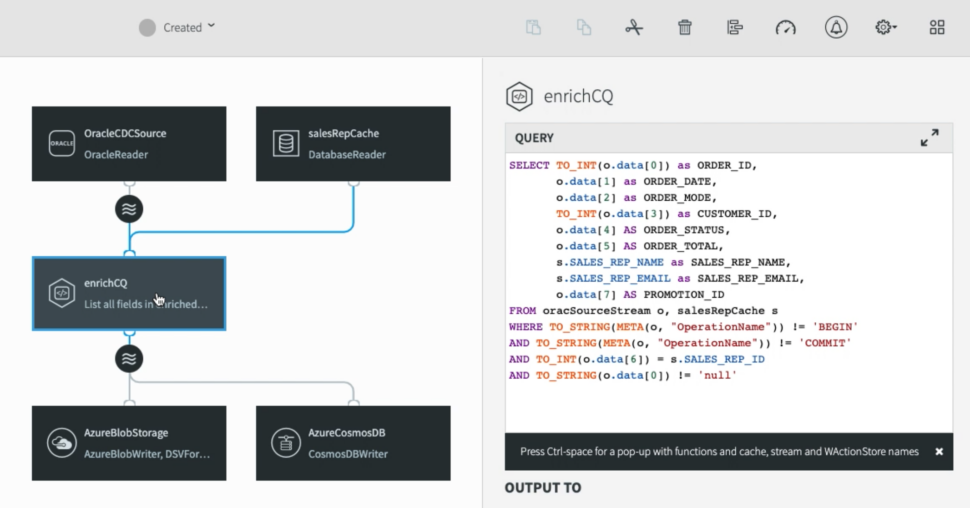
Define and Optimize
Your data flow defines how to collect, process, and deliver data. The simplest data flow just has a source, a stream, and a target. In many cases you will need to perform some processing on your data. Striim enables you to set up continuous SQL queries optimized for streaming, real-time data.
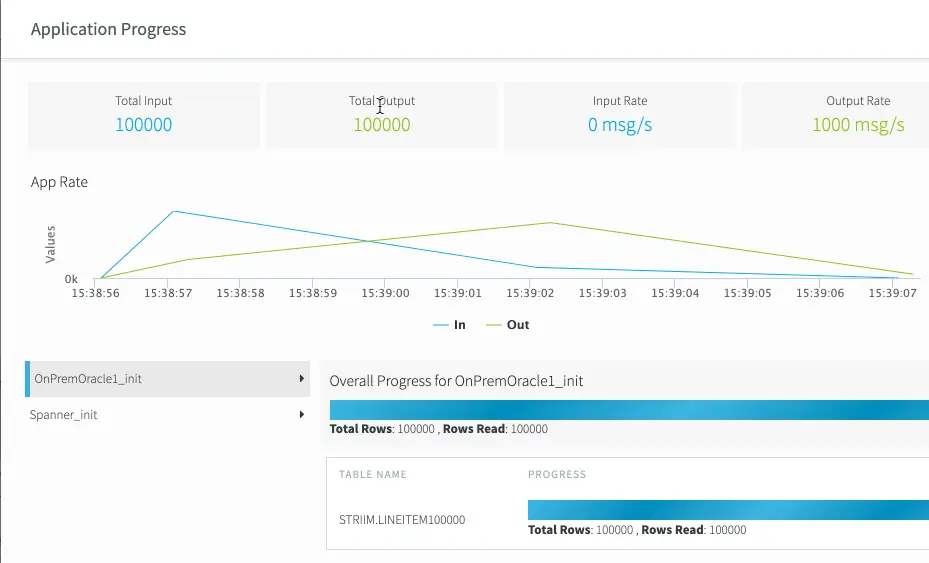
Real-Time Visibility
Our built-in dashboards and monitoring enable you to see the state of your data flows in real-time and easily identify any bottlenecks. Striim can also validate that your data has been delivered and provide visibility into the end-to-end lag. This level of visibility is essential for mission-critical systems that may have SLAs regarding how current the data is.
Detailed Metrics for Maximum Performance
You can also drill down on any of the components in a data flow to see detailed statistics that include read/write rate, lag, latency, CPU usage, and many other metrics. This detailed information can help identify any bottlenecks, and aids in tuning data flows for maximum performance and minimal latency.
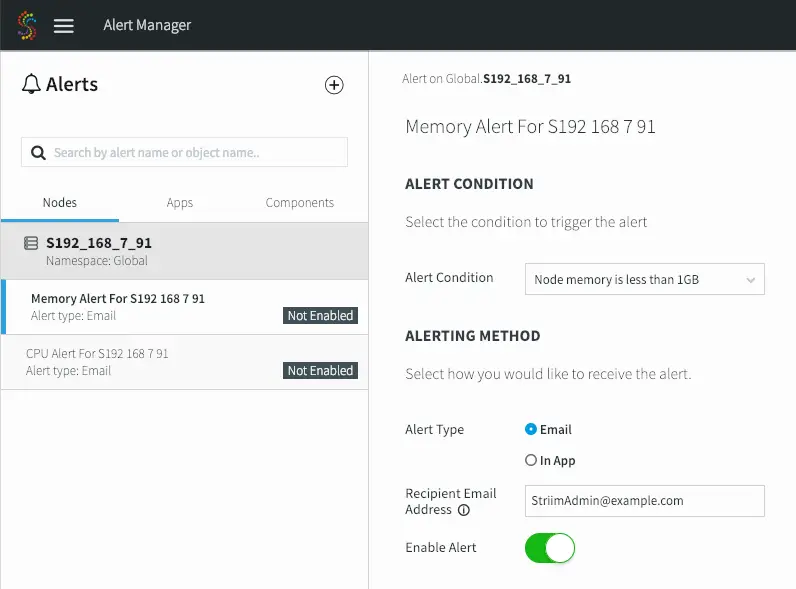
Automation & Custom Alerts
Striim allows you to define SQL-based custom alerts so you can stay informed about the status and performance of your data flows.
In the case of errors, or failures, you can also automate workflows to perform corrective actions. By tapping into error or status streams you can trigger compensating data flows to start, or perform other actions to remediate problems.
“At UPS, we’re reshaping the shipping landscape by prioritizing lower premiums and improved convenience for our customers. Opting for high-confidence shipping addresses not only slashes costs but also assures customers of dependable and secure deliveries, empowering them to shop online with confidence and ease. Striim and Google Cloud have jointly enabled us to enhance the customer experience with AI and ML.”
Pinaki Mitra
VP of Data Science and Machine Learning at UPS Capital
“Striim is a fully managed service that reduces our total cost of ownership while providing a simple drag and drop UI. There’s no maintenance overhead for American Airlines to maintain the infrastructure.”
“One of the most notable benefits we’ve experienced since integrating Striim into our operations has been the significant enhancement in how we communicate with our customers. The real-time updates on order status have not only improved transparency but also helped to reduce the number of customer service calls. This change has streamlined our operations, allowing us to allocate resources more efficiently and improve overall customer satisfaction.”
“We have a significant software portfolio and the ability to tie that into modern ML use cases where we need to do that is important for us. We are a highly data-driven organization and the ability to tie in predictive models or propensity models is really critical to our strategy. The objective with Striim and CDC usage was to simplify pipelines and minimize latency for real-time decision support.”