Your Oracle Data Belongs in Microsoft Fabric. Here’s How to Get It There in Real Time.
Most enterprises running Oracle databases aren’t short on data. They’re short on access to it.
Customer records, financial transactions, inventory movements, order histories, it’s all locked inside a production system that was never designed to be an analytics platform. Meanwhile, the business is asking for live dashboards, AI-powered recommendations, and predictive models that need fresh data to function.
Microsoft Fabric is where a lot of that analytical work is now happening. It’s an end-to-end analytics platform that brings together data warehousing, data engineering, real-time intelligence, and Power BI under one roof, all backed by OneLake: a single unified data lake that serves every workload. The question isn’t whether Fabric is the right destination.
The biggest question for data architects and enterprise leaders is around execution: how you move Oracle data into Fabric without building a brittle batch pipeline that breaks every time a developer changes a table?
Striim is the answer. And the depth of the Oracle-to-Fabric integration goes further than most people realize.
Three Oracle Readers Built for Any Environment
Striim captures changes from Oracle using three purpose-built readers, each optimized for different environments and scale requirements.
Oracle Reader uses Oracle LogMiner for change capture — a non-intrusive approach that has minimal impact on the source database. It supports Oracle 11g through 21c, RAC, PDB/CDB environments, and Active Data Guard standby databases. It handles between 20 GB and 80 GB of CDC data per hour, covering INSERT, UPDATE, and DELETE operations across all standard Oracle data types.
OJet is built for a different class of problem. Using Oracle’s high-performance log mining API, OJet can process 150+ GB of redo data per hour, making it the right choice for high-volume, mission-critical environments. It adds support for TRUNCATE operations, downstream database capture, schema evolution across all supported Oracle versions, and an extended set of data types including BLOB, CLOB, and XMLTYPE. It runs on Oracle 11g through 23c, supports RAC and CDB/PDB topologies, and can read from both primary and downstream mining databases.
GG Trail Reader is the right choice for enterprises that already have Oracle GoldenGate deployed. Rather than creating an additional LogMiner session on the database server, Striim reads directly from existing GoldenGate trail files — preserving your current GoldenGate investment and avoiding any additional load on the source database. It supports GoldenGate 11g, 12c, 18.1, and 19c. If your Striim cluster is licensed for Oracle GoldenGate, the GG Trail Reader is available directly in the Flow Designer with no additional setup required.
All three readers are low to no impact on the source — they read from redo logs, archive logs, or trail files, not from production tables. Your Oracle workloads run untouched.
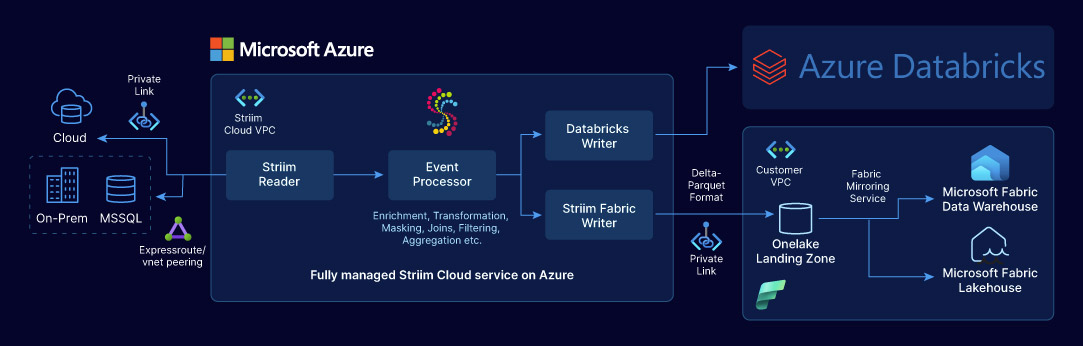
Three Fabric Writers, Three Use Cases
This is where Striim’s Oracle-to-Fabric integration becomes genuinely distinctive. Most integration tools give you one way to land data in a destination. Striim gives you three, each optimized for a specific Fabric workload. You choose based on what you’re trying to accomplish — and nothing stops you from using all three simultaneously from a single Oracle source.
Fabric Data Warehouse Writer
The Fabric Data Warehouse Writer writes directly to the SQL endpoint of a Fabric Data Warehouse, using ADLS Gen2 as a temporary staging layer before copying data into warehouse tables. It supports both merge mode — keeping Fabric in sync with the Oracle source in real time — and append-only mode, which preserves the full history of every change as an insert, even after records are updated or deleted in Oracle. That append-only mode is particularly powerful for audit trails and time-series analysis.
Schema evolution is supported — DDL changes from Oracle are automatically detected and propagated to Fabric Data Warehouse tables, keeping your target schema in sync as the source evolves. Authentication is flexible: Entra ID, Microsoft Entra Service Principal, Active Directory Password, manual OAuth, or Fabric workspace identity with trusted workspace access. Parallel threads are supported for higher write throughput, and Striim’s built-in monitoring surfaces key warehouse metrics in real time.
Best for: SQL-first analytics, Power BI reporting, business intelligence workloads, and any team that wants to query Oracle data with familiar T-SQL semantics inside Fabric.
Fabric Lakehouse File Writer
The Fabric Lakehouse File Writer writes data into the OneLake Files folder — the raw file layer of a Fabric Lakehouse. It supports Avro, DSV, JSON, Parquet, and XML output formats, with configurable upload policies based on file size, time interval, event count, or a combination of conditions. Files land in the OneLake Files folder in the format of your choice, ready to be consumed by Fabric notebooks, Spark jobs, and data science workloads.
A common pattern is to load data into the Lakehouse first — capturing the raw stream in its full fidelity — and then selectively promote data from the Lakehouse into a Data Warehouse for downstream consumers who need SQL access.
Best for: Data engineering workloads, Spark processing, ML feature stores, data science pipelines, and any use case that needs raw or semi-structured data stored flexibly before downstream transformation.
Fabric Mirror Writer
The Fabric Mirror Writer takes a different approach. Instead of writing directly to Fabric tables, it writes incoming data to Microsoft Fabric’s mirroring OneLake landing zone in Parquet format. Fabric’s own replicator service then picks up those files and replicates them into Fabric Data Warehouse tables — using Microsoft’s native mirroring infrastructure.
The Fabric Mirror Writer also supports schema evolution — automatically detecting and propagating DDL changes from Oracle into the Fabric mirror database tables, keeping target schemas in sync with the source as it evolves.
Best for: Teams that want Oracle data surfaced inside Fabric’s native mirroring experience, environments with active schema evolution, and use cases where Fabric’s own replication service managing the final write is preferred.
Read Once, Write Many
One of Striim’s most operationally significant capabilities for Oracle-to-Fabric pipelines is the read-once, write-many pattern. A single Oracle CDC stream — reading the redo log once — can simultaneously feed all three Fabric writers at the same time, plus any other targets in your environment.
In practice, this means a single Striim pipeline can take every INSERT, UPDATE, and DELETE from an Oracle ERP system and simultaneously:
- Write structured, queryable data to a Fabric Data Warehouse for Power BI dashboards
- Land raw change events in a Fabric Lakehouse for data science and ML workloads
- Populate a Fabric Mirror for teams operating within Microsoft’s native mirroring experience
- Stream the same events to Kafka for event-driven microservices
- Feed a real-time alerting system for operational monitoring
The Oracle database is read exactly once. Every downstream system gets the same data, in the format it needs, with sub-second latency.
Transform Data Before It Lands
Raw Oracle data rarely arrives in Fabric in the shape that analysts, data scientists, or AI models actually need. Column names don’t match target conventions. Currencies need normalization. Timestamps need conversion. Sensitive fields need masking before they’re accessible to a broader team.
Striim handles all of this in-flight, before data reaches any Fabric writer, using continuous SQL queries (CQs). These are standard SQL expressions that run on the stream as it moves through the pipeline, no separate transformation layer, no post-load processing job, no additional latency.
You can filter events to specific tables or conditions, join streams to enrich records with reference data, aggregate transactions before they’re written, mask PII fields to meet compliance requirements, or reshape the output schema to match what Fabric expects. The transformation logic travels with the pipeline and executes in memory, at streaming speed.
This is particularly valuable for Oracle-to-Fabric pipelines because Oracle’s data model — with its rich data types, denormalized schemas, and complex relational structures — rarely maps cleanly to what Fabric’s analytical workloads want to consume. Striim closes that gap without requiring a separate ETL tool.
AI Built Into the Pipeline
Striim doesn’t just move Oracle data to Fabric — it adds intelligence to the stream along the way. Striim’s built-in AI Agents run directly inside your pipeline, operating on data as it moves.
Euclid generates vector embeddings from Oracle records in-flight. Customer descriptions, product notes, support tickets, transaction narratives — any text field can be converted into a vector representation as the data streams through Striim, before it lands in Fabric. This makes your Oracle-to-Fabric pipeline a direct feeder for RAG architectures, semantic search systems, and AI models that require vector inputs, without needing a separate embedding pipeline downstream.
Foreseer applies time series forecasting and anomaly detection to your Oracle stream in real time. Instead of shipping raw transaction data to Fabric and running anomaly detection as a batch job after the fact, Foreseer flags unusual patterns — a spike in failed orders, a sudden shift in transaction volumes, an unusual cluster of updates to a specific account — as the events flow through the pipeline. The anomaly signal can be written to Fabric alongside the source data, or used to trigger alerts before the data ever lands.
Sherlock AI and Sentinel AI handle data governance in motion. Sherlock uses LLMs to classify and tag sensitive fields in Oracle data — PII, financial data, regulated content — as the stream passes through. Sentinel enforces protection policies in real time, ensuring that sensitive data is masked, redacted, or flagged before it reaches Fabric. For enterprises with GDPR, HIPAA, or SOC 2 obligations, this in-flight governance is fundamentally more reliable than applying controls after data has already landed in a data warehouse.
Striim CoPilot reduces the operational burden of building and managing these pipelines. It’s a built-in AI assistant that helps data engineers design pipeline logic, troubleshoot issues, and optimize configurations — directly inside the Striim platform, without switching context to external tools.
Monitoring and Alerting That Keeps Pipelines Honest
A pipeline that moves silently is a liability. Striim’s monitoring layer gives you continuous visibility into every Oracle-to-Fabric pipeline, with metrics tracked in real time rather than surfaced after problems have already propagated downstream.
For Oracle sources, Striim monitors redo log read rates, CDC lag, captured SCN progress, and memory utilization on the source database. For Fabric writers, it tracks write throughput, batch completion rates, and connection health. When something goes wrong — a network interruption, a spike in lag, a failed write — Striim’s alerting system fires before the impact reaches your dashboards or your AI models. Alerts can be delivered via email, Slack, or Microsoft Teams, keeping the right people informed the moment a condition is met.
At-least-once processing with automatic retry ensures that transient failures don’t cause data loss. Pipelines recover cleanly from interruptions without manual intervention, replaying events from the last confirmed checkpoint. The result is a pipeline you can trust to stay current — not one you have to monitor manually to confirm it’s still running.
Real-World Use Cases
Real-time financial reporting. Oracle ERP and Oracle Financials are the backbone of financial operations for a significant portion of Global 2000 companies. Streaming that data into a Fabric Data Warehouse means finance teams get Power BI reports that reflect the current state of the ledger, not yesterday’s snapshot. Close processes, variance analysis, and cash flow monitoring all run on live numbers.
AI-powered customer intelligence. Oracle CRM data — customer profiles, interaction history, purchase behavior, support cases — is enormously valuable to AI models. A Striim pipeline from Oracle to a Fabric Lakehouse, with Euclid generating embeddings in-flight, creates a continuously updated vector store that AI agents can query for personalized recommendations, churn prediction, and next-best-action systems.
Operational anomaly detection. Manufacturing, logistics, and supply chain systems running on Oracle generate millions of transactional events per day. Foreseer, running inside a Striim pipeline, can detect anomalies — unusual inventory movements, order processing delays, quality control outliers — before they surface as customer-facing problems. The detection happens at stream speed, not at the end of a nightly batch run.
Compliance-safe data federation. Enterprises with Oracle databases in regulated industries — healthcare, financial services, insurance — need to get data into analytics platforms without violating data governance requirements. Sherlock and Sentinel handle PII classification and protection in-flight, so Fabric receives governed, compliant data from day one.
Oracle modernization without disruption. For enterprises in the middle of an Oracle-to-cloud migration, Striim’s read-once, write-many architecture makes it possible to run Oracle and Fabric in parallel — keeping both systems current — while the migration progresses at its own pace. No big-bang cutover, no data gaps, no production risk.
The Bottom Line
Oracle databases hold decades of business-critical data. Microsoft Fabric is where modern analytics, AI, and business intelligence are converging. The gap between them shouldn’t require a custom ETL project, a batch window, or a team of engineers maintaining fragile extraction scripts.
Striim bridges that gap with sub-second latency, three purpose-built Oracle readers for any environment, three Fabric writers for three distinct use cases, in-flight transformations, AI agents that add intelligence to the stream, and monitoring that keeps every pipeline accountable.
Read Oracle once. Write to Fabric in every form it needs.
Ready to see it in action? Schedule a demo or explore the documentation to start building your Oracle-to-Fabric free pipeline today with Striim Developer.