










Apache Kafka has proven itself as a fast, scalable, fault-tolerant messaging system, and has been chosen by many leading organizations as the standard for moving data around in a reliable way. In this blog series, I would like to share how to make the most of Kafka when building streaming Kafka integration or Kafka analytics applications, including how to make Kafka easy. I’ll also highlight critical considerations when including Kafka as part of an overall enterprise data architecture.
If you have adopted, or are considering adopting Apache Kafka, you need to determine:
- How do you integrate data into Kafka from your enterprise sources, including databases, logs, devices?
- How do you deliver data from Kafka to targets like Hadoop, Databases, Cloud storage?
- How do you process and prepare Kafka data?
- How do you perform Kafka analytics?
- How do you ensure all the pieces work together and are enterprise grade?
- How do you do all this in a fast and productive way without involving an army of developers?
Let’s start by answering the last question first.
Ease of Use
Kafka is extremely developer oriented. It has been created by developers, for developers. This implies that if you are adopting Kafka you will need a team of developers to build, deploy, and maintain any stream processing or analytics applications that use it. The documentation for Kafka talks about APIs and gives lots of code examples, but if you want to do real-time web analytics, build location tracking applications, or monitor and manage security threats, you are speaking a different language.
At Striim we think about things differently. All of the things you need to do to make best use of Kafka should be easy, and you shouldn’t have to write Java code to create business solutions.
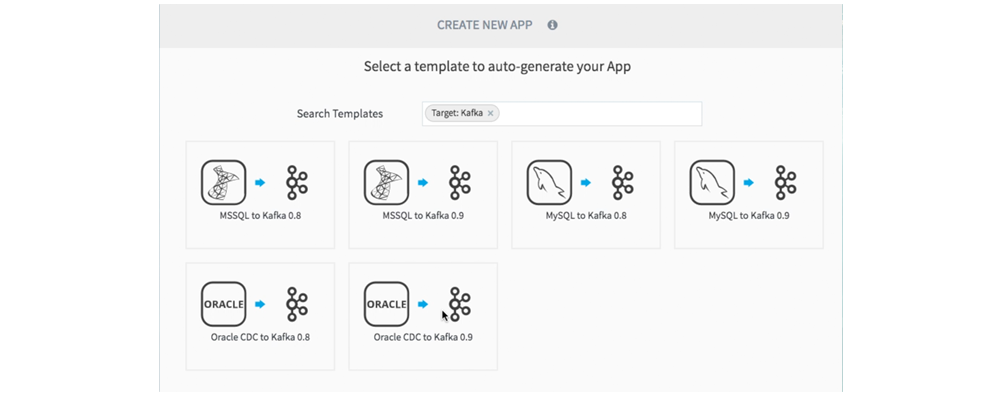 Striim not only integrates Kafka as a source and target, which we will go into later, Striim ships with Kafka built in. You can optionally start a Kafka cluster when you spin up a Striim cluster, and easily switch between our high speed in-memory messaging and Kafka using a keyword (or a toggle in our UI). Kafka can become transparent and its capabilities harnessed without having to code to a bunch of APIs.
Striim not only integrates Kafka as a source and target, which we will go into later, Striim ships with Kafka built in. You can optionally start a Kafka cluster when you spin up a Striim cluster, and easily switch between our high speed in-memory messaging and Kafka using a keyword (or a toggle in our UI). Kafka can become transparent and its capabilities harnessed without having to code to a bunch of APIs.
Striim has offered SQL-query-based processing and analytics for Kafka since 2015. This, combined with Striim’s drag-and-drop UI, pre-built wizards for configuring ingestion into Kafka, and custom utilities, make Striim the easiest platform to deliver end-to-end streaming integration and analytics applications involving Kafka.
For more information on Striim’s latest enhancements relating to Kafka ease-of-use and Exactly Once Processing, please read today’s press release, “New Striim Release Further Bolsters SQL-based Streaming and Database Connectivity for Kafka.” Or download the Striim platform for Kafka and try it for yourself.
Continue reading this series with Part 2: Making the Most of Apache Kafka – Ingestion into Kafka.



