










This architecture post is the second blog in a six-part series on making In-Memory Computing Enterprise Grade. Read the entire series:
- Part 1: overview
- Part 2: data architecture
- Part 3: scalability
- Part 4: reliability
- Part 5: security
- Part 6: integration
You have to remember that Striim is an end-to-end distributed IMC Platform providing Streaming Integration and Analytics through continuous Ingest, Processing, Enrichment, Analysis, Delivery, Alerting, and Visualization of streaming data. As such, it has a lot of moving parts that need to work together seamlessly to meet these requirements.
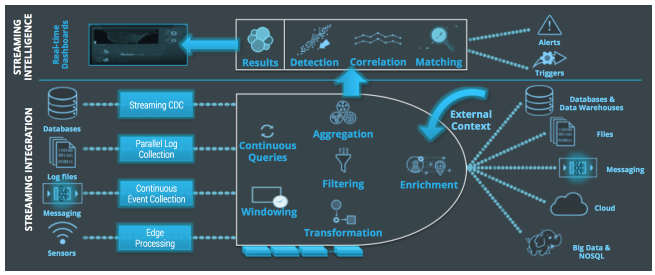
The Striim platform can employed for a large variety of different real-time data integration and streaming analytics use cases. This can be as simple as moving database data supporting enterprise applications into a Data Lake, or Kafka in real-time, or much more complex analytics applications such preventing fraud, monitoring infrastructure, or watching customer behavior to improve their experience. In all of these cases, ensuring scalable, reliable and secure processing that integrates into existing resources is paramount.
As we drill down into each of these requirements, it is useful to understand the Distributed In-Memory Architecture that Striim employs to provide this end-to-end streaming integration and analytics platform.
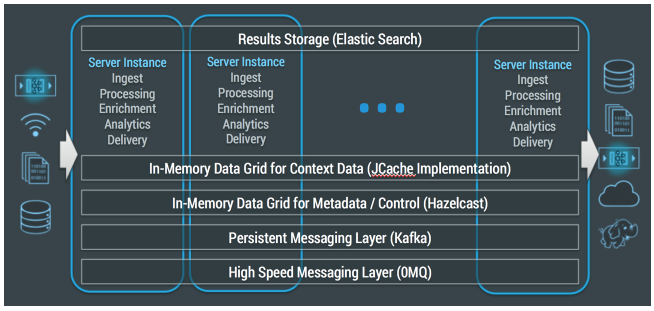
There are seven main components to this architecture, and each needs to be considered when making the platform Enterprise Grade.
Each of these components has unique characteristics and combining them all together to provide Striim is an example of a converged platform. Making any one of these components Enterprise Grade is a tricky enough proposition, but ensuring each of them are, and arranging things such that the interaction between components does not break anything, is much harder.
| Data Ingest | Integrating data from existing enterprise sources in real-time |
| High Speed Messaging | Moving huge volumes of data between Striim nodes with very low latency |
| Persistent Messaging | Storage of messages for replay in the case of failure |
| IMDG for Metadata / Control | Clustering Striim nodes and distribution of metadata and user actions |
| IMDG for Context | In memory storage of external data for context and denormalization purposes |
| Processing | Continuous queries for processing, enrichment and analytics |
| Results | Storage of results within the platform or in external resources |
In subsequent blogs we will drill down into each of the Enterprise Grade requirements, and outline how we designed things so that each of the above components is scalable, reliable, secure and integrates well with the enterprise infrastructure as required.
The architecture part starts at the 5m12s mark:




