Traditional extract, transform, load (ETL) solutions have, by necessity, evolved into real-time ETL solutions as digital businesses have increased both the speed in executing transactions, and the need to share larger volumes of data across systems faster. In this two-part blog post series, I will describe the transition from traditional ETL to a streaming, real-time ETL and how that shift benefits today’s data-driven organizations.
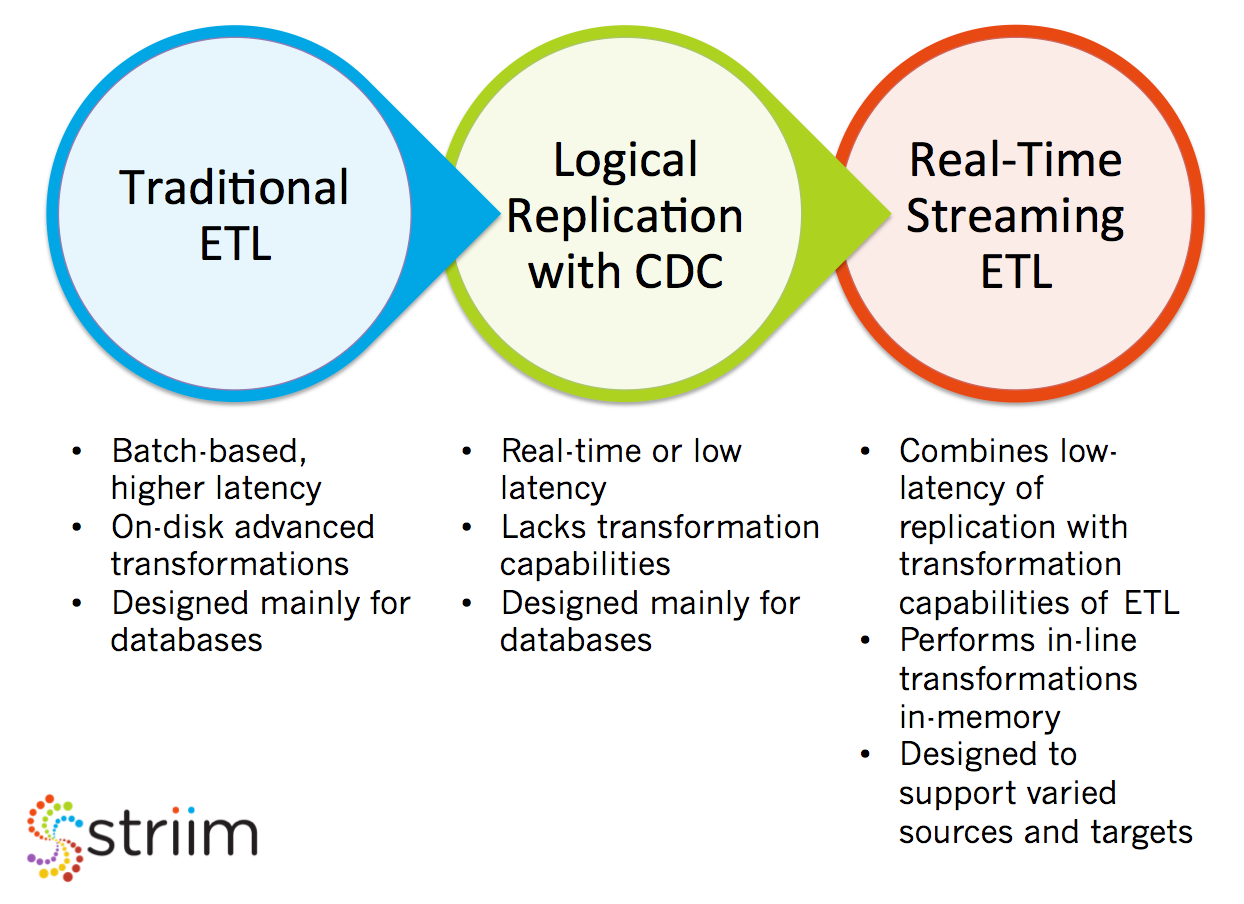 Data integration has been the cornerstone of the digital innovation for the last several decades, enabling the movement and processing of data across the enterprise to support data-driven decision making. In decades past, when businesses collected and shared data primarily for strategic decision making, batch-based ETL solutions served these organizations well. A traditional ETL solution extracts data from databases (typically at the end of the day), transforms the data extensively on disk in a middle-tier server to a consumable form for analytics, and then loads it in batch to a target data warehouse – with a significantly different schema – to enable various reporting and analytics solutions.
Data integration has been the cornerstone of the digital innovation for the last several decades, enabling the movement and processing of data across the enterprise to support data-driven decision making. In decades past, when businesses collected and shared data primarily for strategic decision making, batch-based ETL solutions served these organizations well. A traditional ETL solution extracts data from databases (typically at the end of the day), transforms the data extensively on disk in a middle-tier server to a consumable form for analytics, and then loads it in batch to a target data warehouse – with a significantly different schema – to enable various reporting and analytics solutions.
As consumers demanded faster transaction processing, personalized experience, and self-service with up-to-date data access, the data integration approach had to adapt to collect and distribute data to customer-facing applications and analytical applications more efficiently and with lower latency. In response, two decades ago, logical data replication with change data capture (CDC) capabilities emerged. CDC moves only the change data in real time, as opposed to all available data as a snapshot, and delivers data to various databases.
These “new” technologies enabled businesses to create real-time replicas of their databases to support customer applications, migrate databases without downtime, and allow real-time operational decision making. Because CDC was not designed for extensive transformations of the data, logical replication and CDC tools lead to an “extract, load, and transform” (ELT) approach where significant transformations and enrichment would be required on the target system to put the data in the desired form for analytical processing. Many of the original logical replication offerings are also architected to run single processes on one node, which creates a single point of failure and requires an orchestration layer to achieve true high availability.
The next wind of change came with the analytical solutions shifting from traditional on-premises data warehousing on relational databases to Hadoop and NoSQL environments and Kafka-based streaming data platforms, deployed heavily in the cloud. Traditional ETL had to now evolve further to a real-time ETL solution that works seamlessly with the data platforms both on-premises and in the cloud, and combines the robust transformation and enrichment capabilities of traditional ETL with low-latency data capture and distribution capabilities of logical replication and CDC.
In Part 2 of this blog post, I will discuss these real-time ETL solutions in more detail, particularly focusing on Striim’s streaming data integration software which moves data across cloud and on-premises environments with in-memory stream processing before delivering data in milliseconds to target data platforms. In the meantime, please check out our product page to learn more about Striim’s real-time ETL capabilities.
Feel free to Schedule a technical demo with one of our lead technologists, or download or provision Striim for free to experience first-hand its broad range of capabilities.


