










Streaming data integration is a fundamental component of any modern data architecture. Increasingly, companies need to make data-driven decisions – regardless of where data resides, when it matters most – immediately. Streaming data integration is one of the first steps in being able to leverage the next-generation infrastructures such as Cloud, Big Data, real-time applications, and IoT that underlie these decisions.
In this post, we’re going to take a look at how the Striim platform was built from the ground up for streaming data integration, and how organizations are benefitting from it. Striim enables businesses to move to Cloud, easily build real-time applications, and get more value from Hadoop solutions.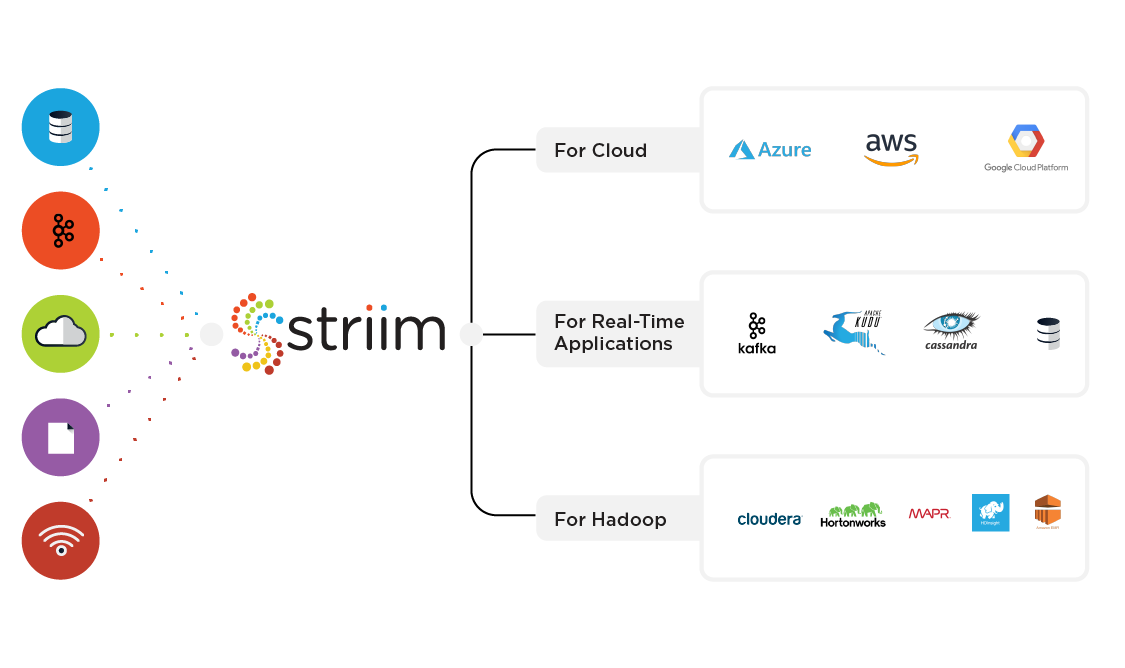
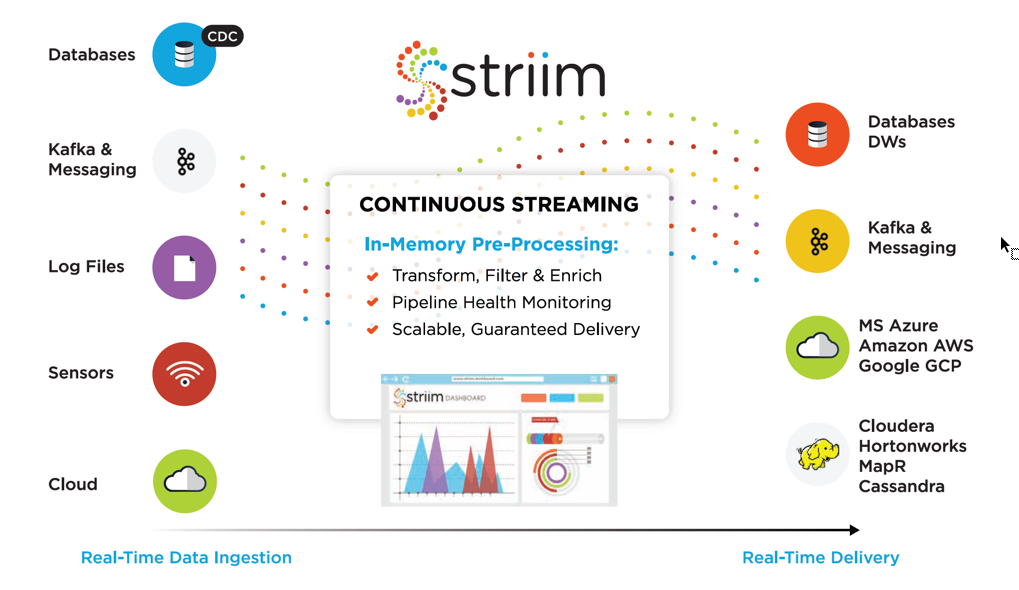
Striim is patented, enterprise-grade software for streaming data integration, which offers continuous data collection, stream processing, pipeline monitoring, and real-time delivery with verification across heterogeneous systems. Striim provides up-to-date data in a consumable form in Kafka, Hadoop, and databases — on-prem or in the Cloud — to support operational intelligence and other high-value workloads.
Core Platform Capabilities
- Continuous, Structured, and Unstructured Data Collection: Striim captures real-time data from a wide variety of sources including databases (using low-impact chance data capture), cloud applications, log files, IoT devices, and message queues.
- SQL-based Stream Processing: Striim applies filtering, transformations, aggregations, masking, and enrichment using static or streaming reference data.
- Pipeline Monitoring and Alerting: Striim allows users to visualize the data flow and the content of data in real time, and offers delivery validation.
- Real-Time Delivery: Striim distributes real-time data in a consumable form to all major targets including Cloud environments, Kafka and other messaging systems, Hadoop, relational and NoSQL databases, and flat files.
 Key Platform Differentiators
Key Platform Differentiators
- Streaming data integration with intelligence via an in-memory platform
- Real-time data movement across on-prem and cloud environments
- Low-impact CDC for Oracle, SQL Server, HPE NonStop, and MYSQL
- In-flight filtering, aggregation, transformation, and enrichment using SQL
- Quick-to-deploy and easy-to-integrate via drag-and-drop UI
- Continuous data pipeline monitoring and built-in delivery validation
- Integration with existing technologies and open source solutions
Common Use Cases
Here are just a few of the most common ways Striim customers leverage its patented software to solve critical enterprise challenges:
Hybrid Cloud Integration
Striim eases cloud adoption by continuously moving real-time data from on-premises and cloud sources to Microsoft Azure, Amazon Web Services (AWS), and Google Cloud Platform environments. Many Striim customers use pre-built data pipelines to feed their cloud solutions from their on-premises databases, files, messaging systems, and sensors to enable operational workloads in the cloud. By filtering, aggregating, transforming, and enriching the data-in-motion before delivering to the cloud, Striim delivers real-time data in consumable form and helps to optimize cloud storage. Available on-premises or in the cloud, Striim enables businesses to get up and running in a matter of minutes.
Data Integration for Real-Time Applications
Striim enables real-time applications on event-based messaging systems such as Kafka, fast analytics storage solutions such as Kudu, and NoSQL databases such as Cassandra by continuously feeding pre-processed data in real time. Striim offers a wizard-based UI and SQL-based language for easy and fast development. Also, when needed Striim performs SQL-based streaming analytics and visualizes the streaming data, before delivering the data to the target to provide real-time operational intelligence.
Real-Time Integration and Pre-Processing for Hadoop
Striim enables a modern, smart data architecture for data lakes by non-intrusively and continuously collecting real-time data from databases, logs, messaging systems, and sensors, and pre-processing the data-in-motion for operational reporting and analytics. To accelerate insights and optimize storage, Striim filters, masks, aggregates, transforms, and enriches the data before delivering with sub-second latency to HDFS, HBase, and Hive. Striim can also pre-process and extract features suitable for machine learning before continually delivering training files to Hadoop. Models built using Hadoop technologies can be brought into Striim, so real-time insights can guide operational decision making and truly transform the business. Striim can also monitor model fitness and trigger retraining of models for full automation.
To learn more about our streaming data integration capabilities, please visit our Real-time Data Integration solution page, schedule a demo with a Striim expert, or download the Striim platform to get started!



