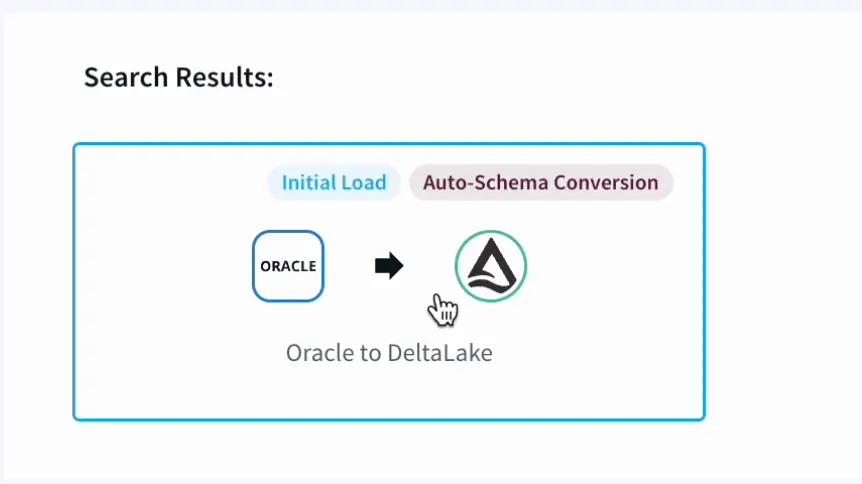
Part 1: Initial Load and Schema Creation
In this demo, we will be going over on how to move historical data from Oracle to Databrick’s Delta lake.
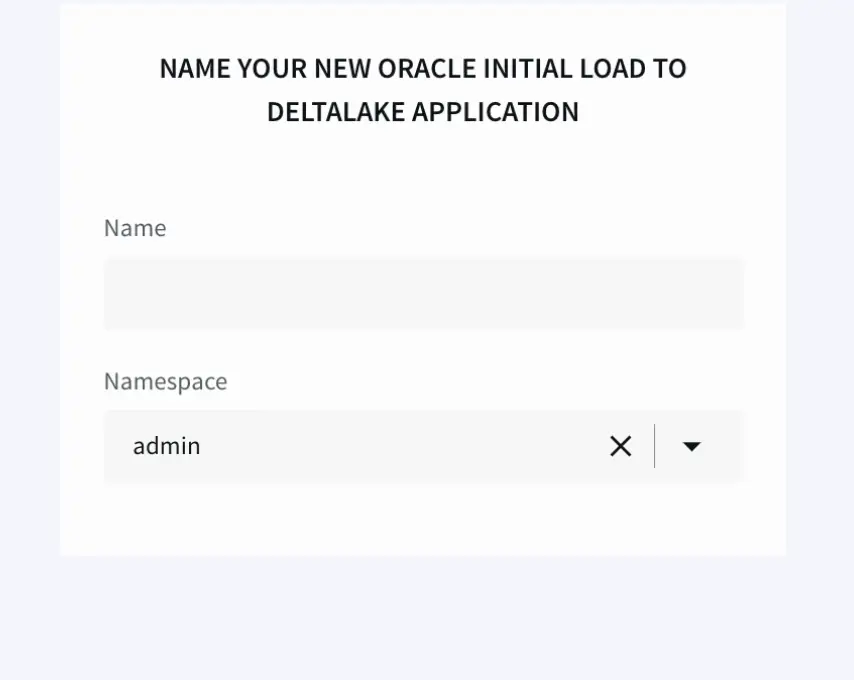
- With the help of Striim’s Intuitive Wizard we name the application,
With the added option to create multiple namespaces depending on our pipelines needs and requirements
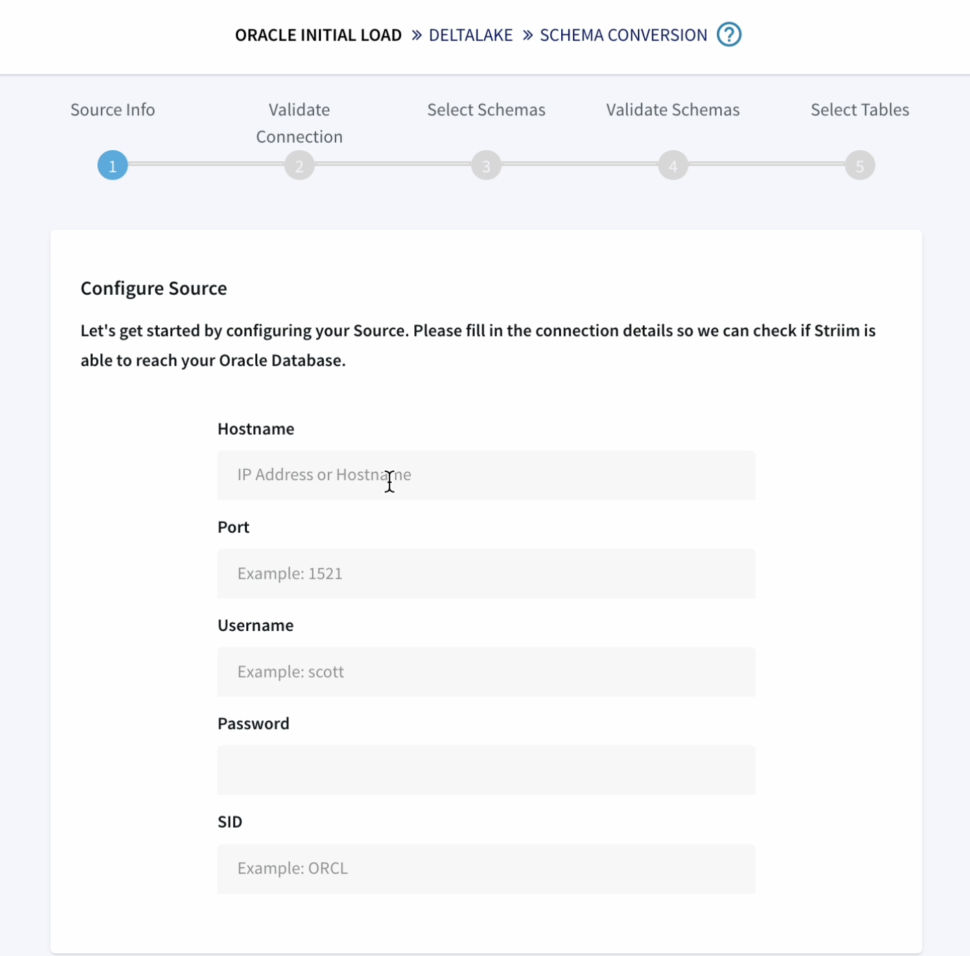
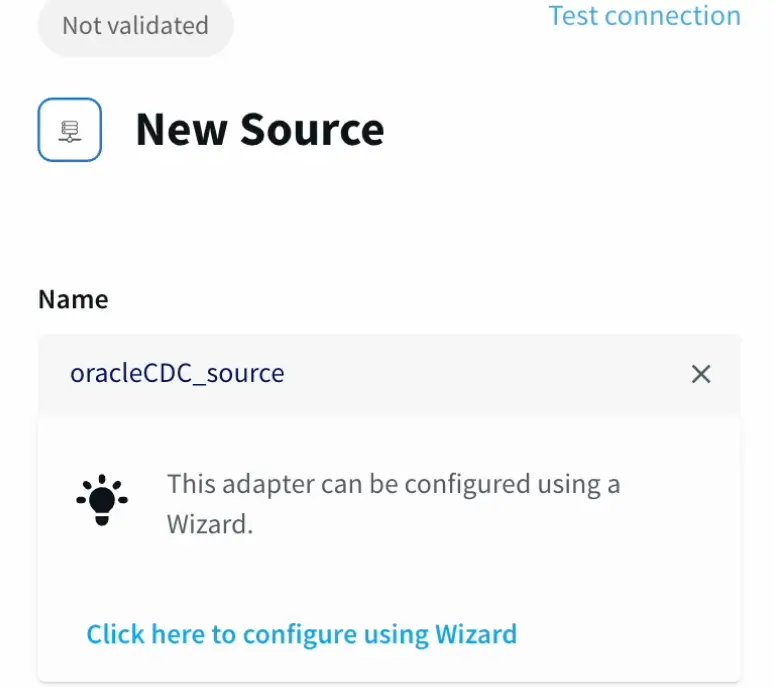
- First we configure the source details for the Oracle Database.

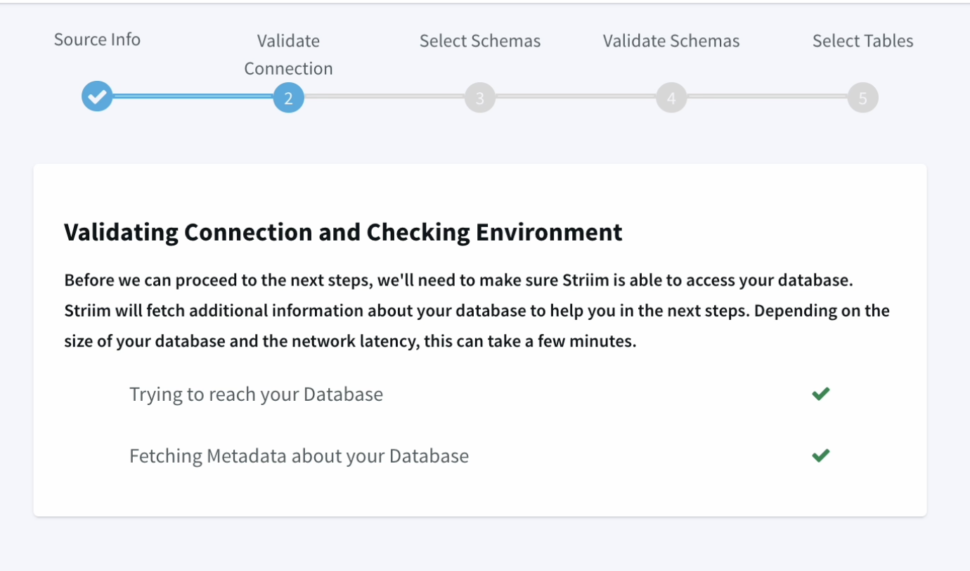
- We can validate our connection details

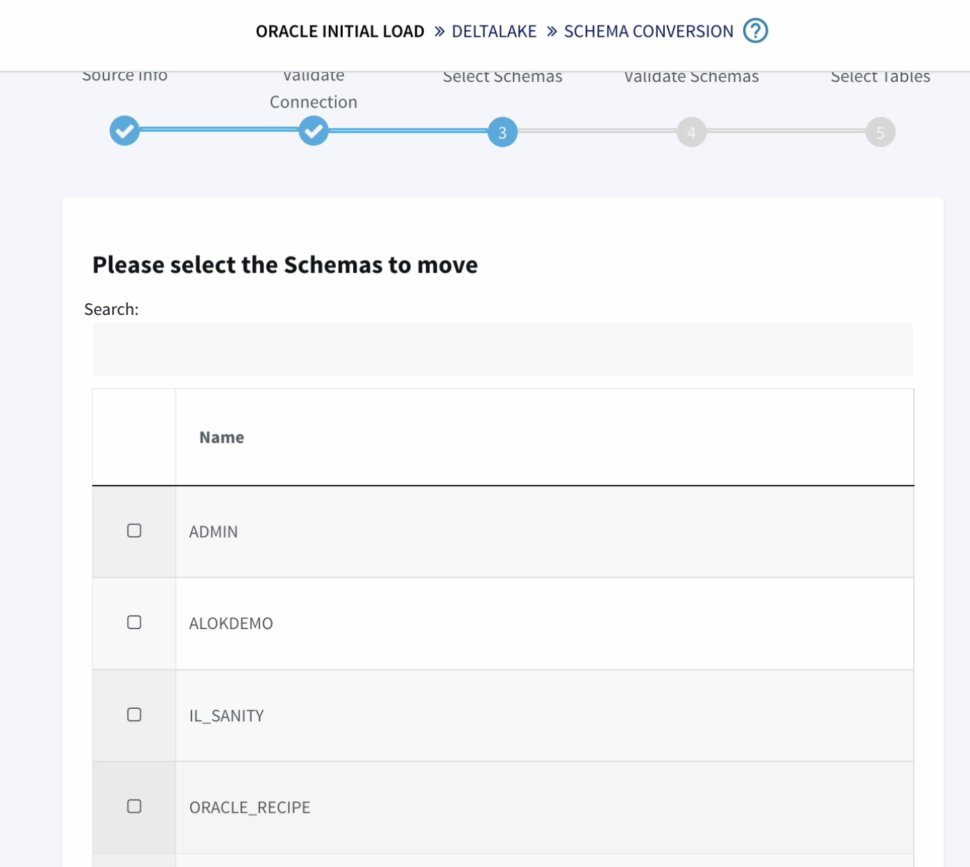
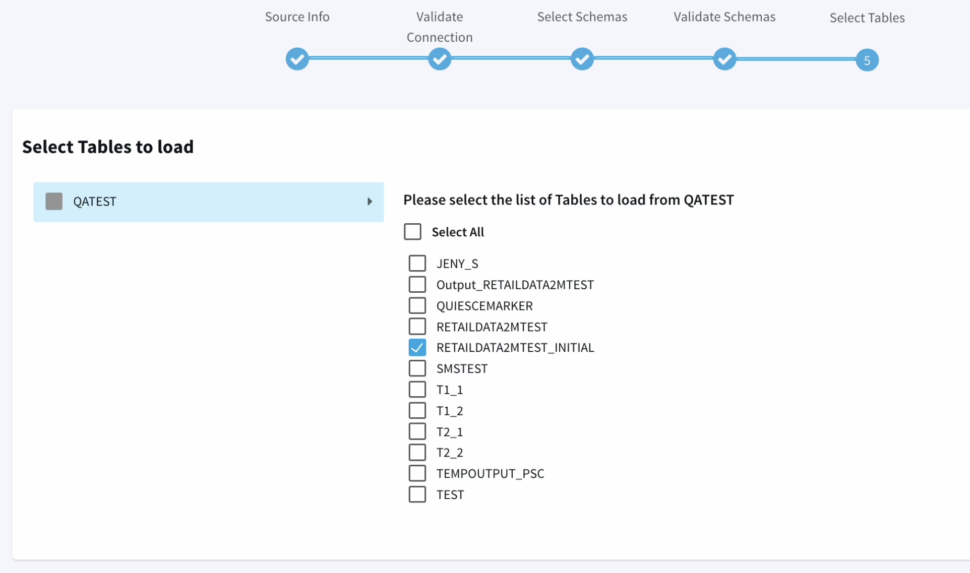
- Next we have to option to choose the schemas and tables that we specifically want to move, providing us with more flexibility instead of replicating the entire database or schema.


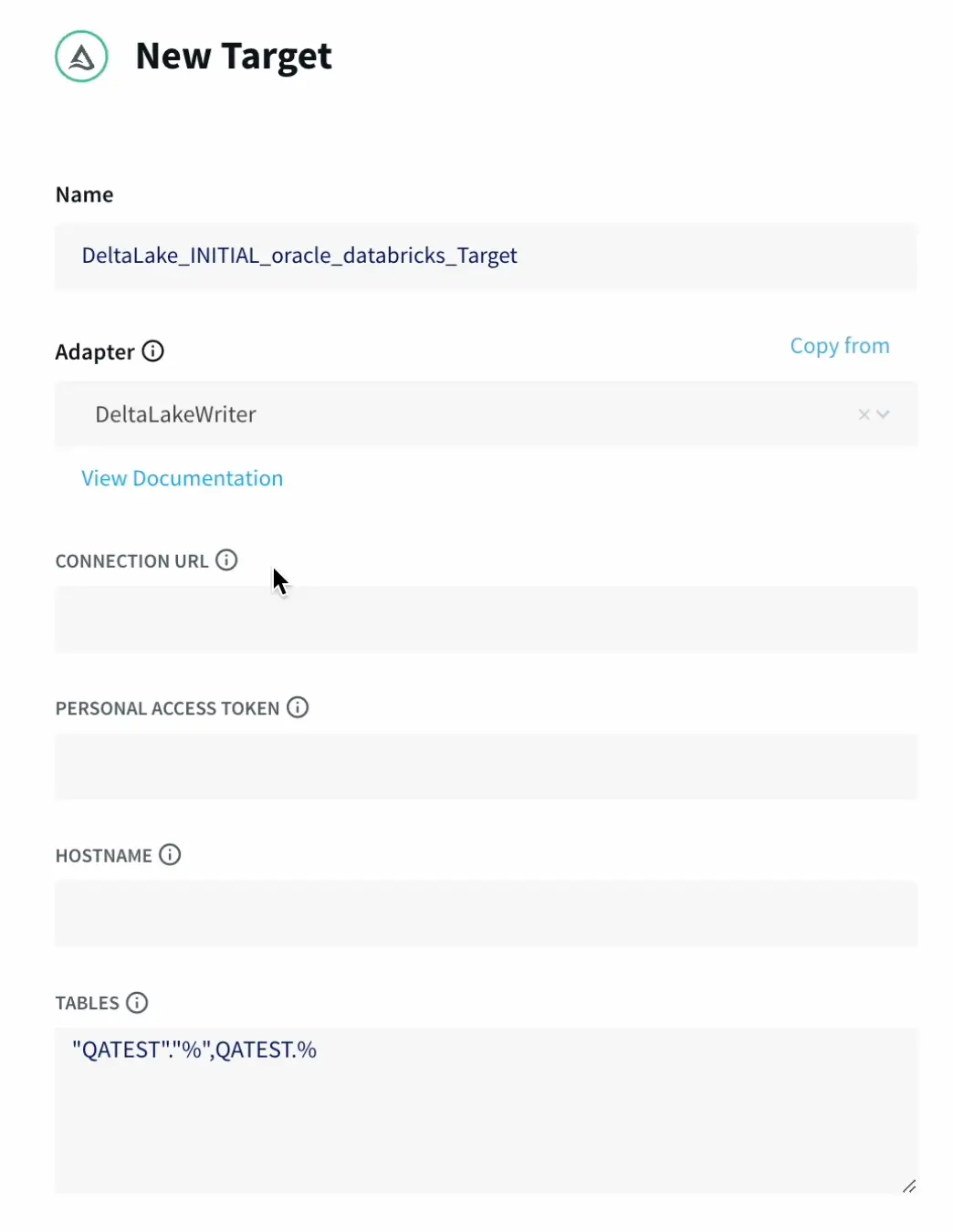
- Now we can start to configure our target Delta Lake.
Which supports ACID transactions, scalable metadata handling, and unifies streaming and batch data processing.
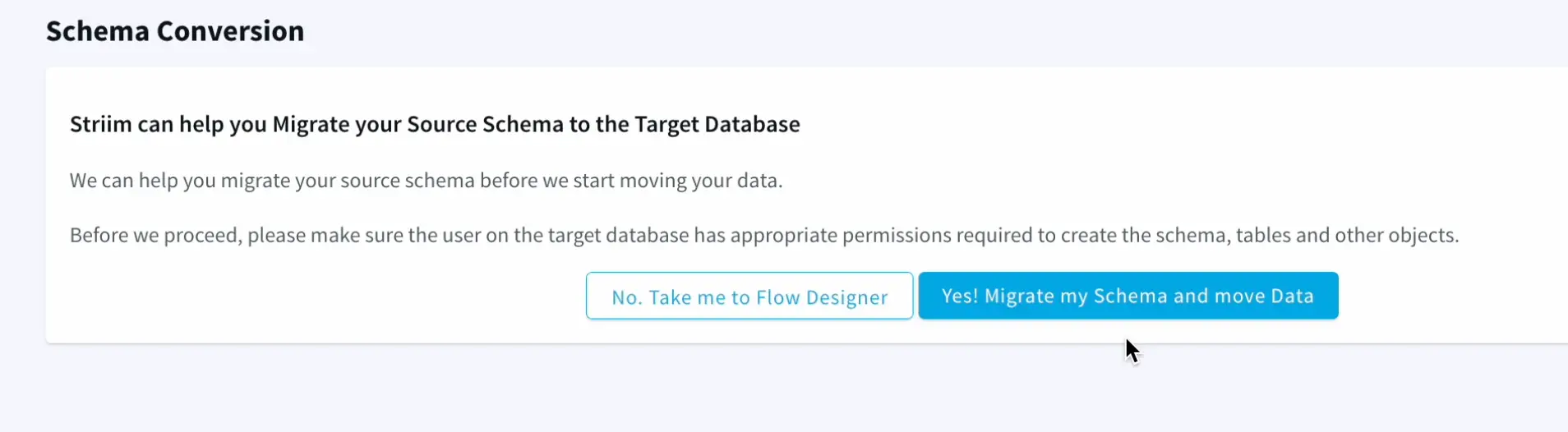
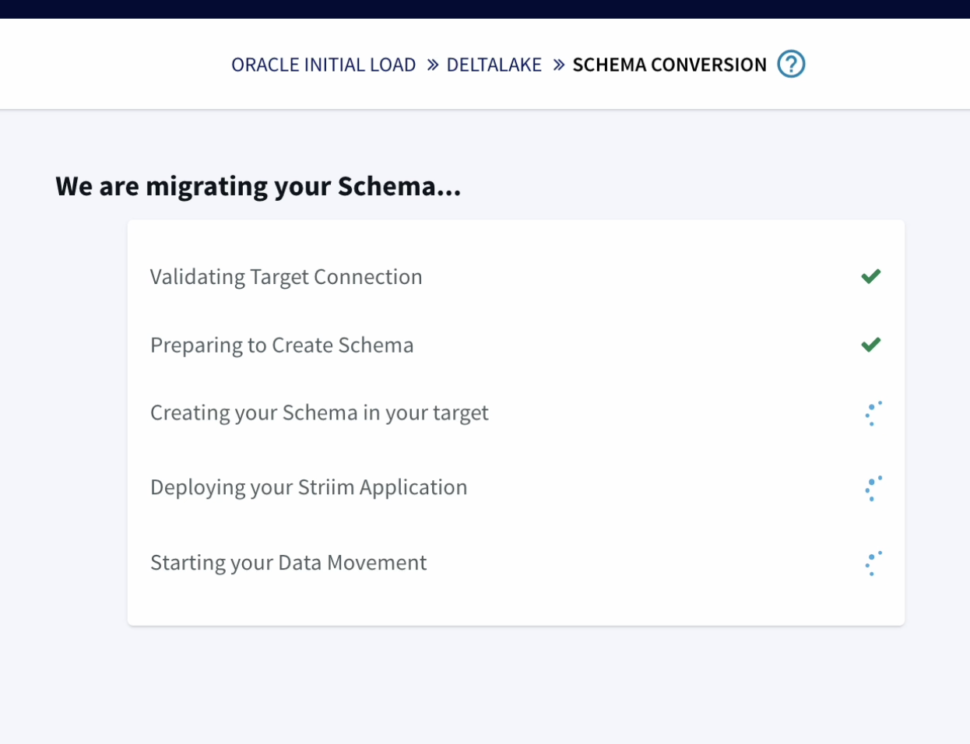
- Striim has the capability to migrate schemas too as part of the wizard which makes it very seamless and easy.

The wizard takes care of validating the target connections, using the oracle metadata to create schema in the target and initiate the historical data push to delta lake as well.
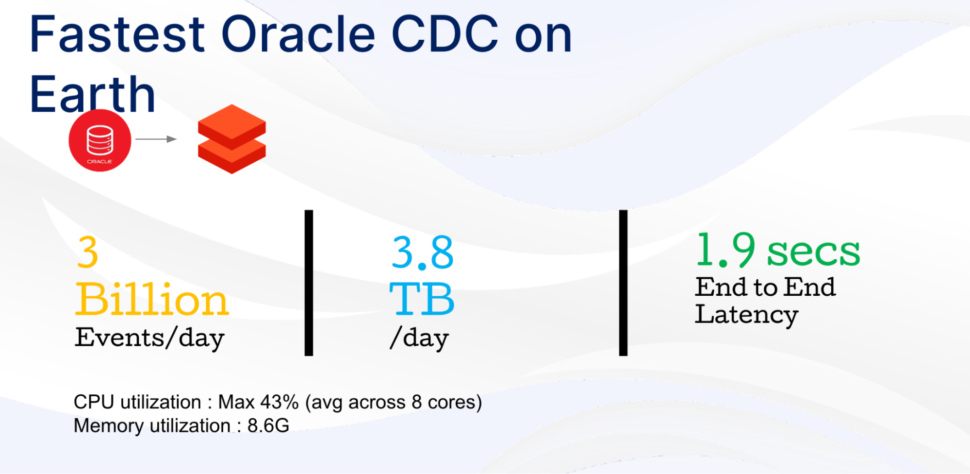
Making the whole end to end operation finish in less then a fraction of the time it would take with traditional pipelines.

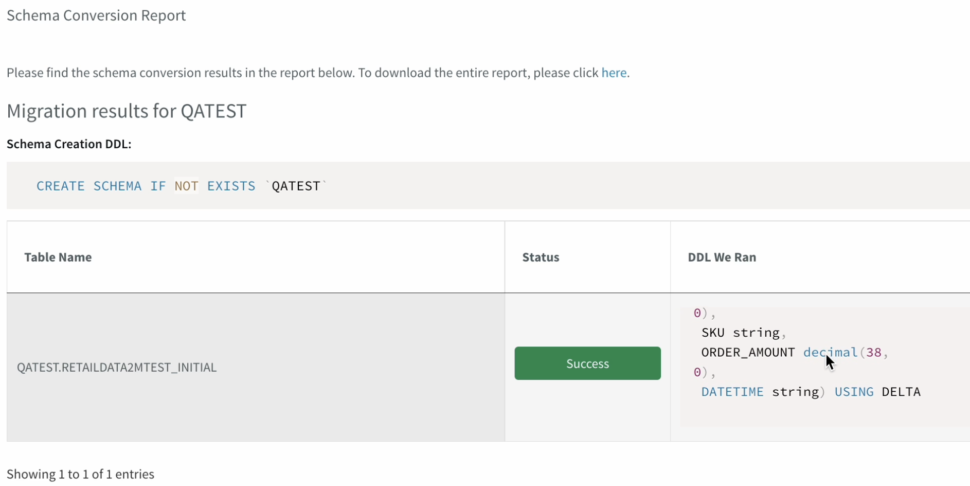
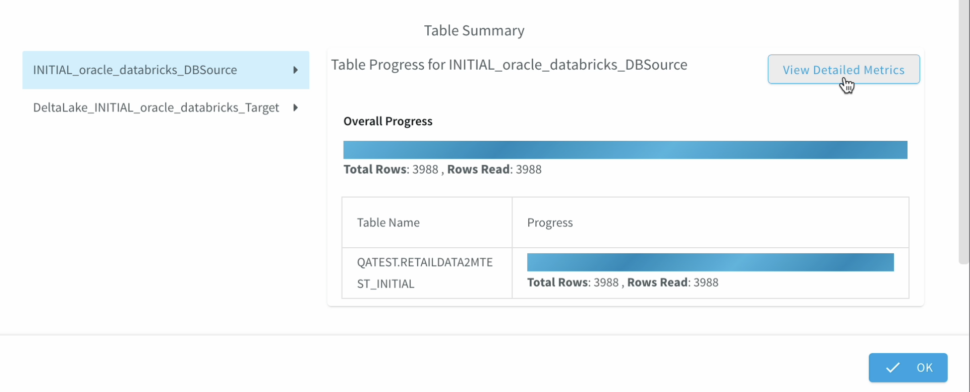
Once the schema is created, we can also verify it before we go ahead with the migration to Delta lake
- Striim’s unified data integration provides unprecedented speed and simplicity which we have just observed on how simple it was to connect a source and target.

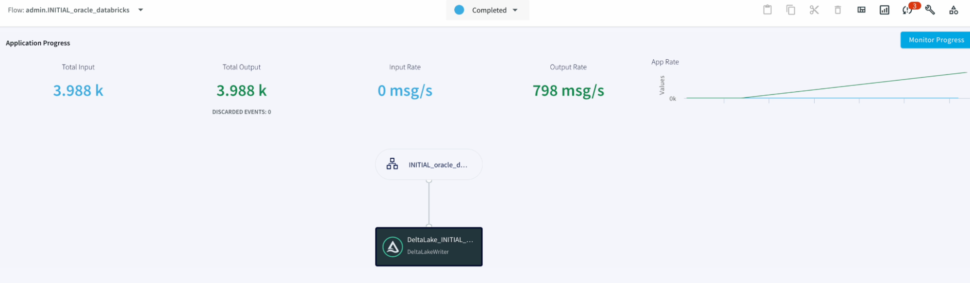
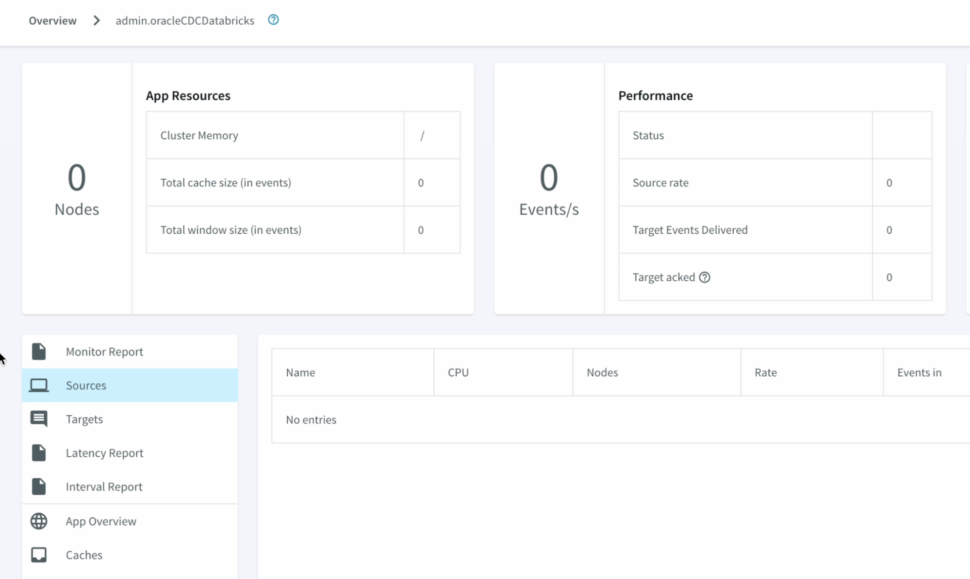
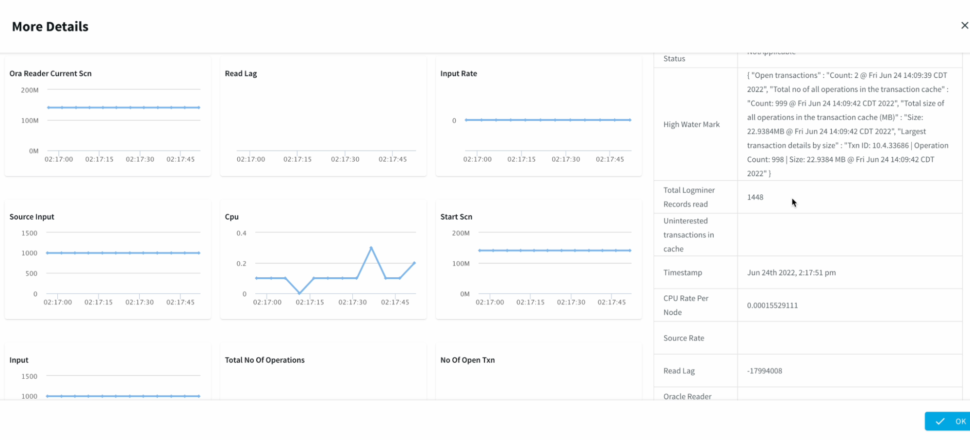
In case, we want to make additional changes to the Fetch size, provide a custom Query. The second half of the demo highlights , how we can apply those changes without the wizard. - We can Monitor the progress of the job with detailed metrics which would help with the data governance to ensure data has been replicated appropriately.

Part 2: Change Data Capture
As part of our second demo, we will be highlighting Striim’s Change data Capture that helps drive Digital transformation and leverage true real time analytics.
- Earlier we have gone through how to create a pipeline through the wizard, and Now we will have a look at how we can tune our pipeline without the wizard and use the intuitive drag and drop flow design

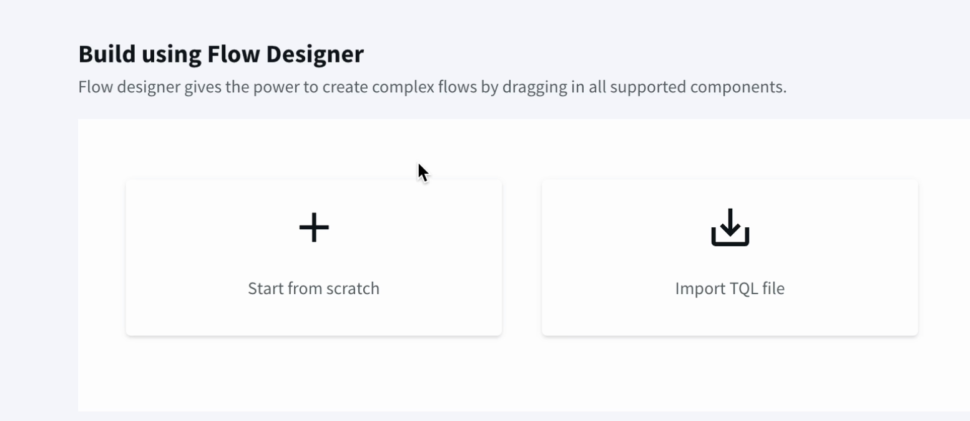
From the Striim dashboard , we can navigate the same way as earlier to create An Application from scratch or also import a TQL file if we already have a pipeline created.
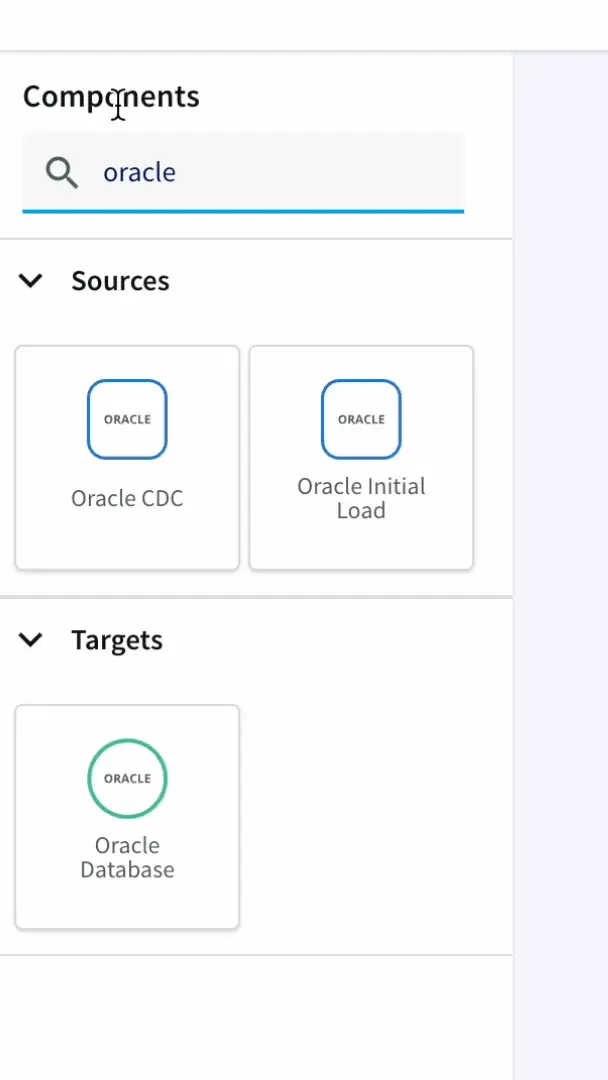
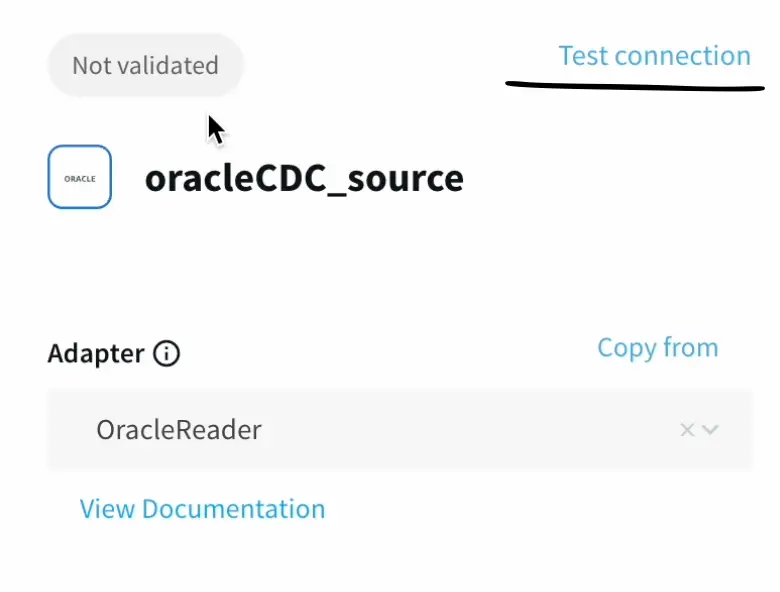
- From the search bar, we can search for the oracle CDC adapter. The UI is super friendly with an easy drag and drop approach.

- We can skip the wizard if we want and go ahead and enter the connection parameters like earlier.

In the additional parameters, we have the flexibility to make any changes to the data we pull from the source.
Lastly, we can create an output stream that will connect to the data sink
We can test connections and validate our connections even without deploying the app or pipeline.

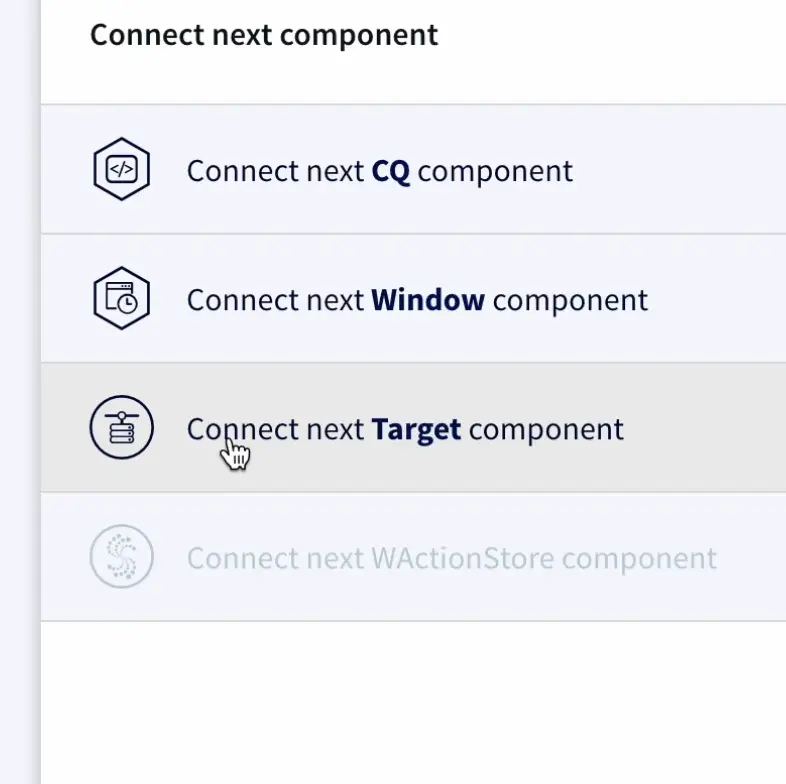
- Once the source connection is established , we can connect to a target component, and select the delta Lake adapter from the drop down.

Databricks has a unified approach to its design that allows us to bridge the gap between different types of users ranging from Analysts, Data Scientists, and Machine Learning Engineers.
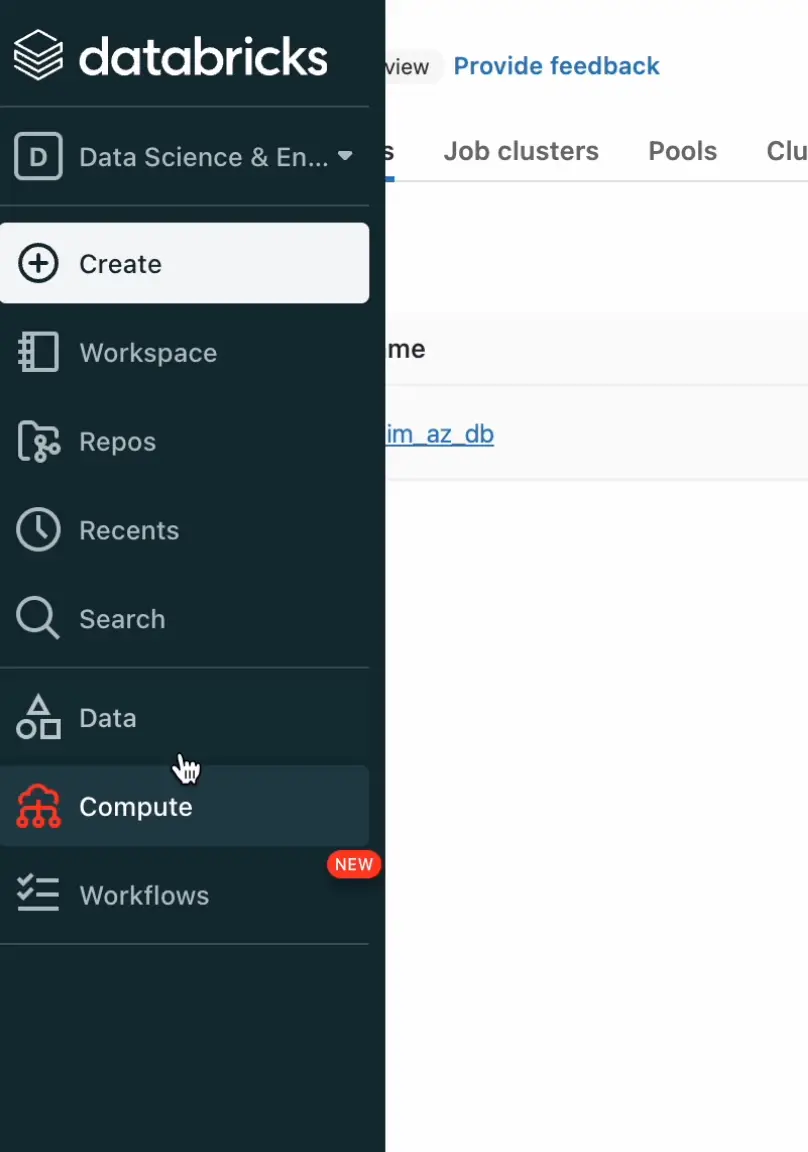
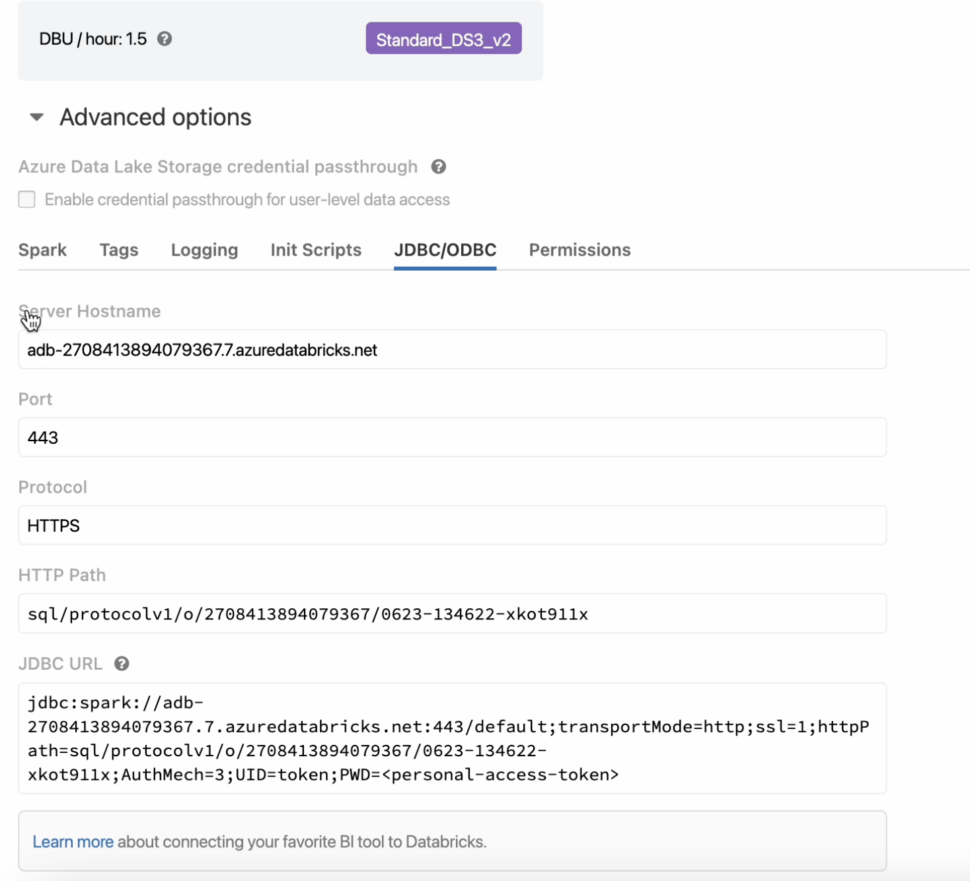
From the Databricks dashboard, we can navigate to the Compute section to access the cluster’s connection parameters.

- Under the advanced settings, select the JDBC/ODBC settings to view the cluster’s Hostname and JDBC URL.

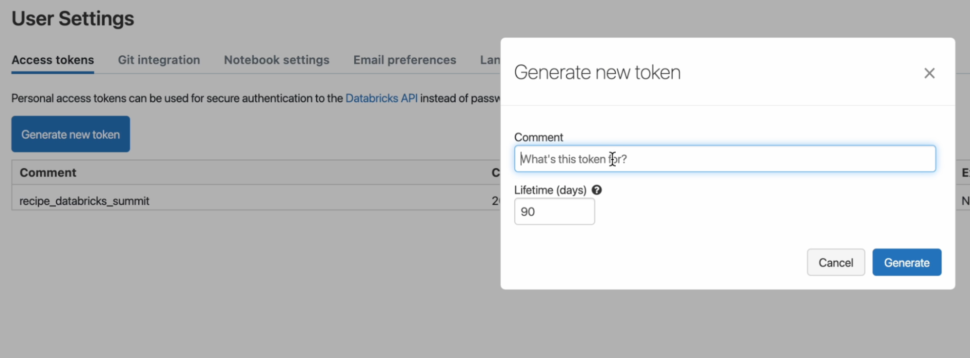
- Next, we can go ahead and generate a Personal access token that will be used to authenticate the user’s access to Databricks
From the settings, we can navigate to the user’s settings and click on Generate a new token.

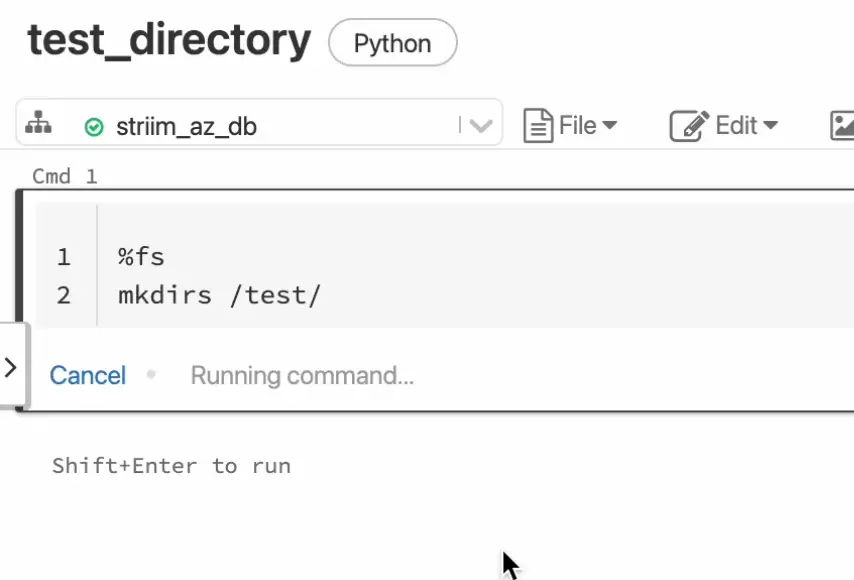
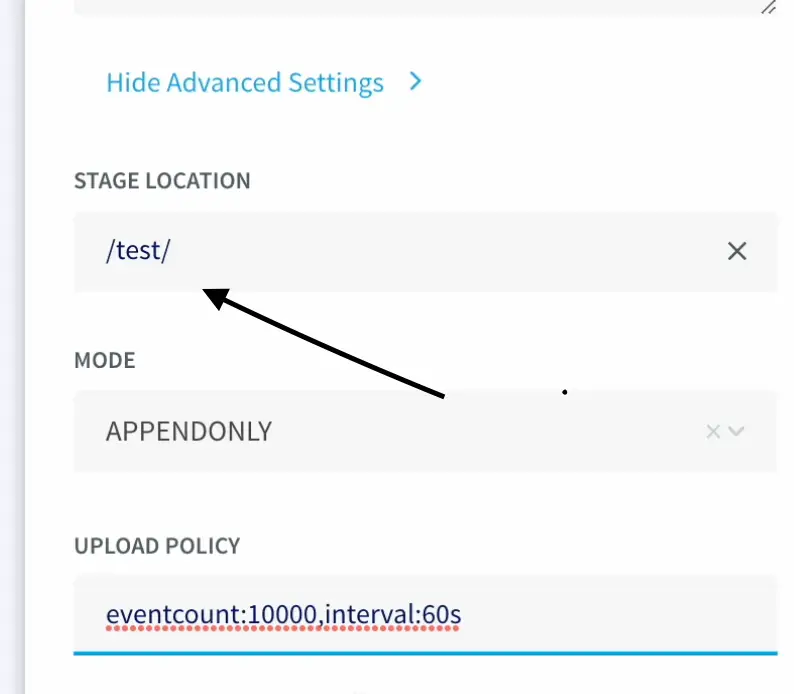
- After adding the required parameters, we can go ahead and create the directory in DBFS through the following commands in a notebook


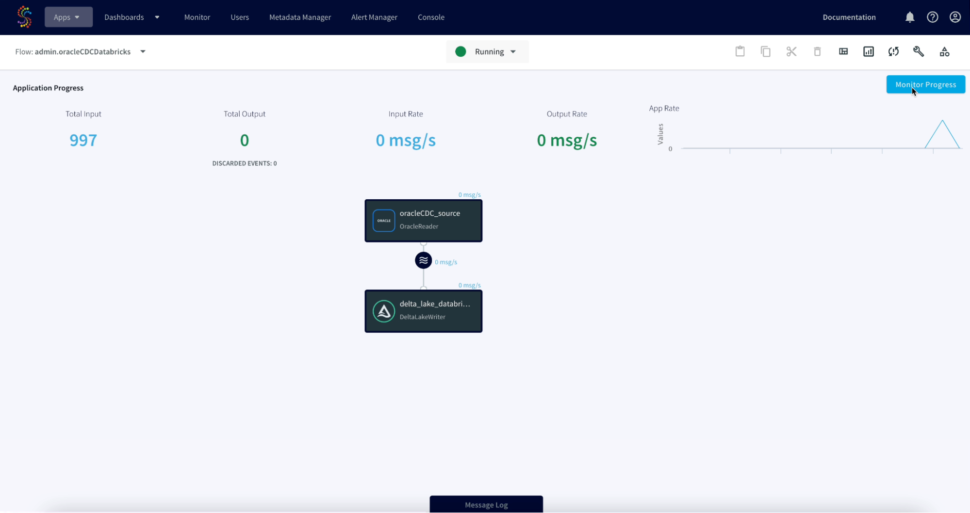
- Next, we can go ahead and deploy the app and start the flow to initiate the CDC.

- We can refresh Databricks to view the CDC data, Striim allows us to view the detailed metrics of a pipeline in real-time.




Striim
Striim’s unified data integration and streaming platform connects clouds, data and applications.

Databricks
Databricks combines data warehouse and Data lake into a Lakehouse architecture
Oracle
Oracle is a multi-model relational database management system.

Delta Lake
Delta Lake is an open-source storage framework that supports building a lakehouse architecture