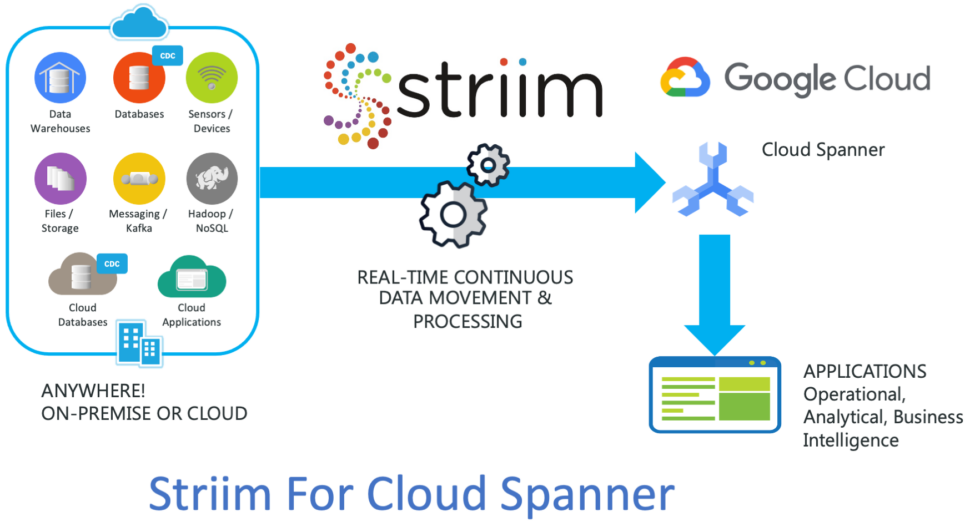
Designed for supporting mission-critical applications, Cloud Spanner requires seamless and risk-free database migration. With real-time data synchronization capabilities, Striim enables Cloud Spanner customers to migrate their data from existing relational databases, such as Oracle, SQL Server, HPE NonStop, MySQL, PostgreSQL, without data loss risk or downtime.
Using Striim, Spanner customers can continuously load real-time transactional data from a wide range of cloud-based or on-premises source systems and smoothly run their critical workloads on Cloud Spanner.
Striim also has a unique offering for low-latency data capture from Cloud Spanner. In addition to relational databases, Striim moves data from log files, Kafka, sensors, Hadoop and NoSQL databases in real time. Striim can be deployed in the cloud, on-premises, or in a hybrid topology to fit organizations evolving needs.
Why Striim for Cloud Spanner
Striim offers an enterprise-grade software platform for real-time ingestion, in-flight data processing, and continuous delivery with sub-second latency into Google Cloud Spanner.
For real-time data collection from databases, Striim uses a non-intrusive, low-impact change data capture (CDC) which minimizes overhead on source production systems.
Striim’s built-in scalability, reliability, security, and delivery with transactional integrity make it suitable to mission-critical applications running on Spanner.
Striim offers continuous pipeline health monitoring and delivery verification to prevent data loss for both migration and on-going data integration solutions.
Run Operational Workloads on Spanner
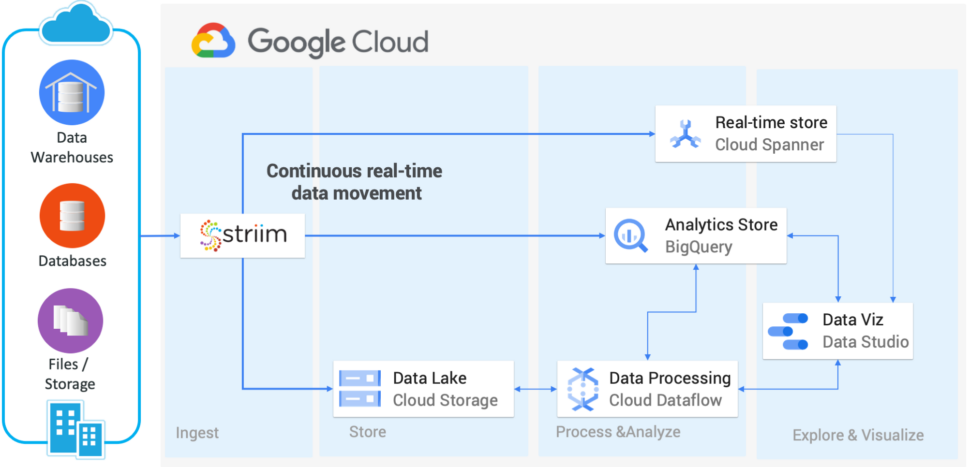
With Striim’s PaaS solution, you can rapidly build highly reliable, scalable and performant real-time data pipelines into Spanner. By continuously ingesting high-volume, high-velocity data from on-premises and cloud-hosted data sources in real time, you can offload business-critical workloads to Cloud Spanner and achieve maximum benefit from the service.
Striim also offers in-flight data processing (including filtering, aggregation, transformation, masking, and enrichment), to deliver data to Cloud Spanner in the format the end users need.
Getting started is easy. Sign up for a free trial or talk to a cloud integration expert.