










Overview
This is the second post in a two-part blog series discussing how to stream database changes into Kafka. You can read part one here. We will discuss adding a Kafka target to the CDC
source from the previous post. The application will ingest database changes (inserts, updates, and deletes) from the PostgreSQL source tables and deliver to Kafka to continuously to update a Kafka topic.
What is Kafka?
Apache Kafka is a popular distributed, fault-tolerant, high-performance messaging system.
Why use Striim with Kafka?
The Striim platform enables you to ingest data into Kafka, process it for different consumers, analyze, visualize, and distribute to a broad range of systems on-premises and in the cloud with an intuitive UI and SQL-based language for easy and fast development.
Step 1: How to add a Kafka Target to a Striim Dataflow
From the Striim Apps page, click on the app that we created in the previous blog post and select Manage Flow.
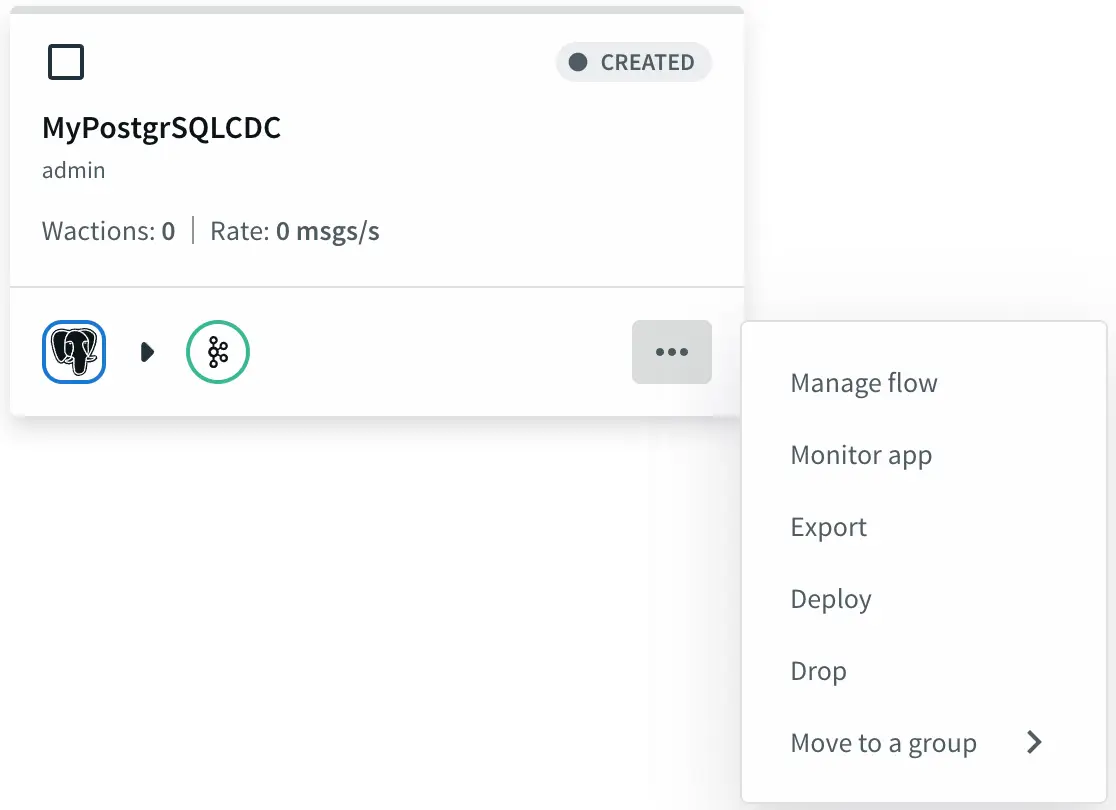
MyPostgreSQL-CDC App
This will open your application in the Flow Designer.
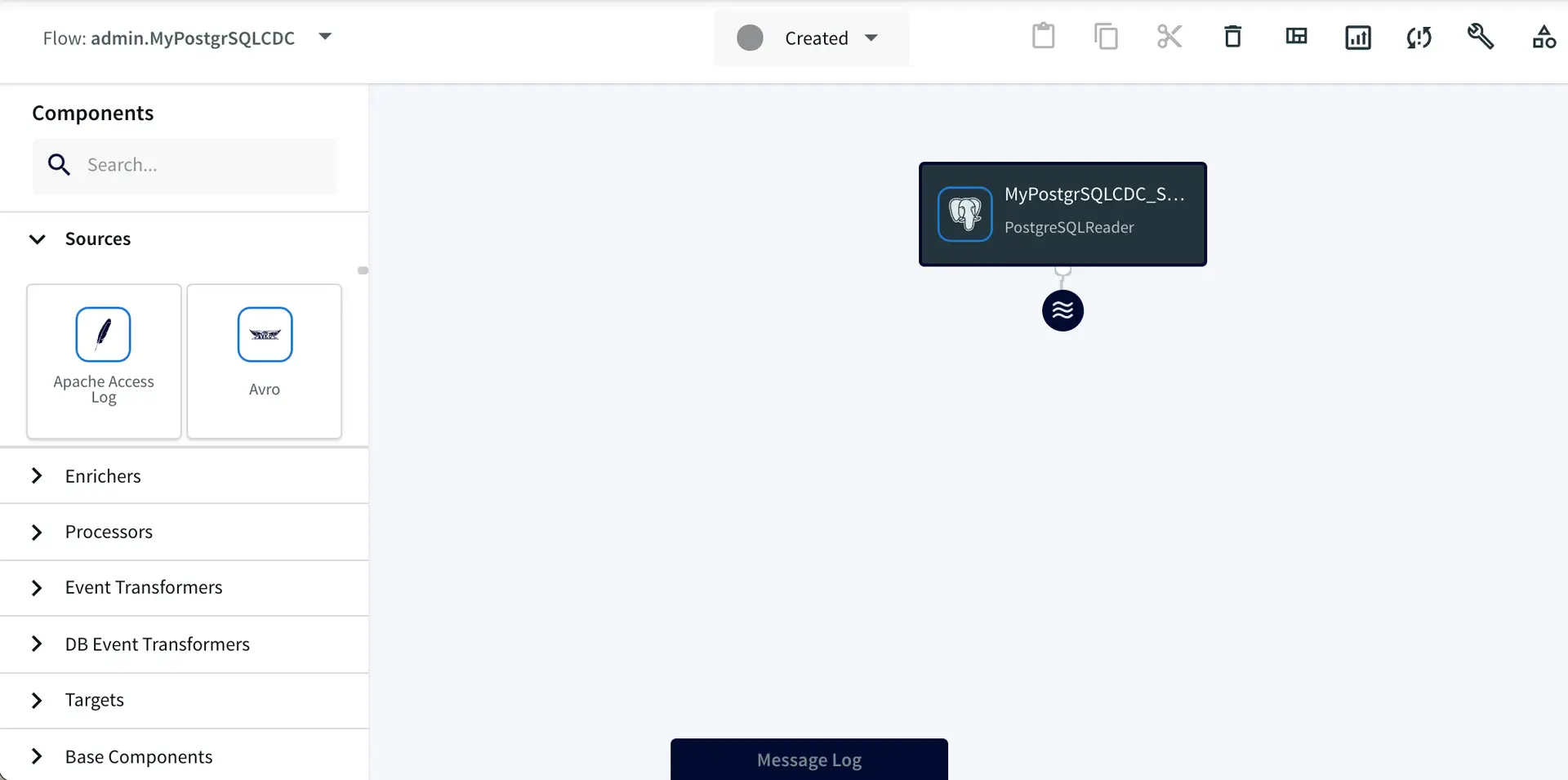
MyPostgrSQLCDC app data flow.
To do the writing to Kafka, we need to add a Target component into the dataflow. Click on the data stream, then on the plus (+) button, and select “Connect next Target component” from the menu.
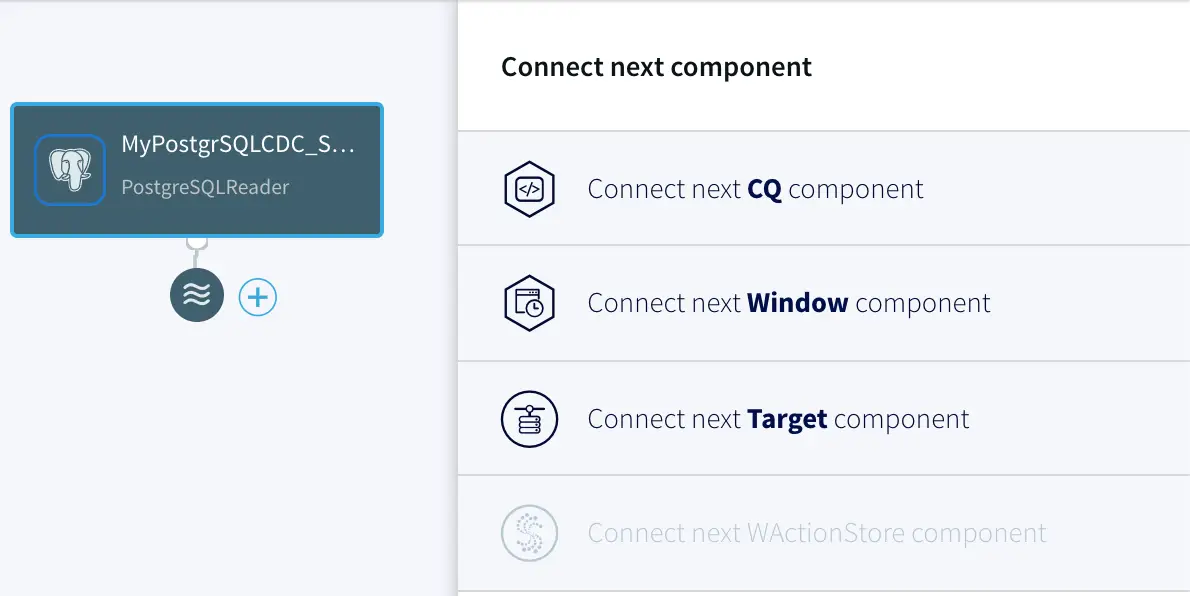
Connecting a target component to the data flow.
Step 2: Enter the Target Info
The next step is to specify how to write data to the target. With the New Target ADAPTER drop-down, select Kafka Writer Version 0.11.0, and enter a few connection properties including the target name, topic and broker URL.
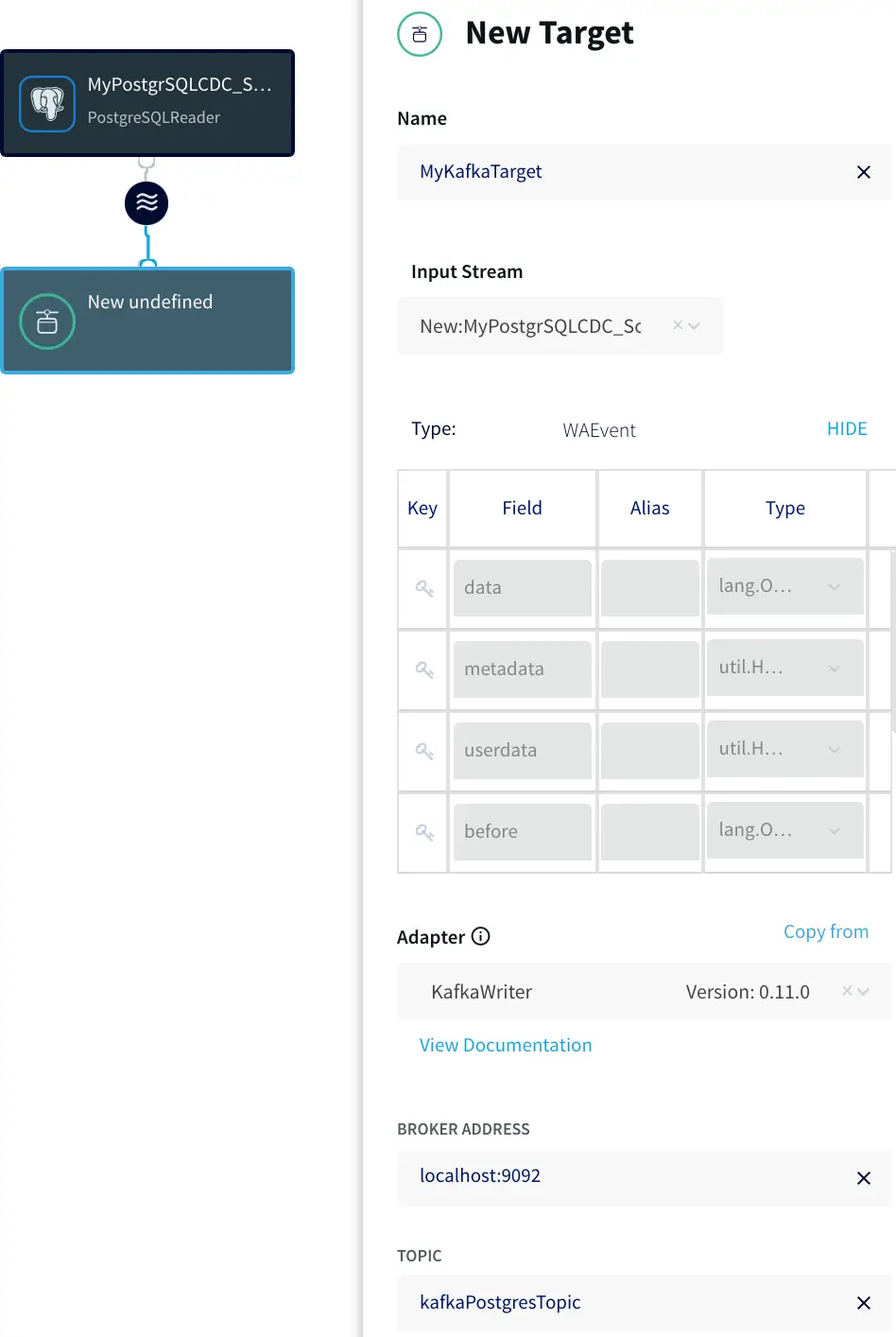
Configuring the Kafka target.
Step 3: Data Formatting
Different Kafka consumers may have different requirements for the data format. When writing to Kafka in Striim, you can choose the data format with the FORMATTER drop down and optional configuration properties. Striim supports JSON, Delimited, XML, Avro and free text formats, in this case we are selecting the JSONFormatter.
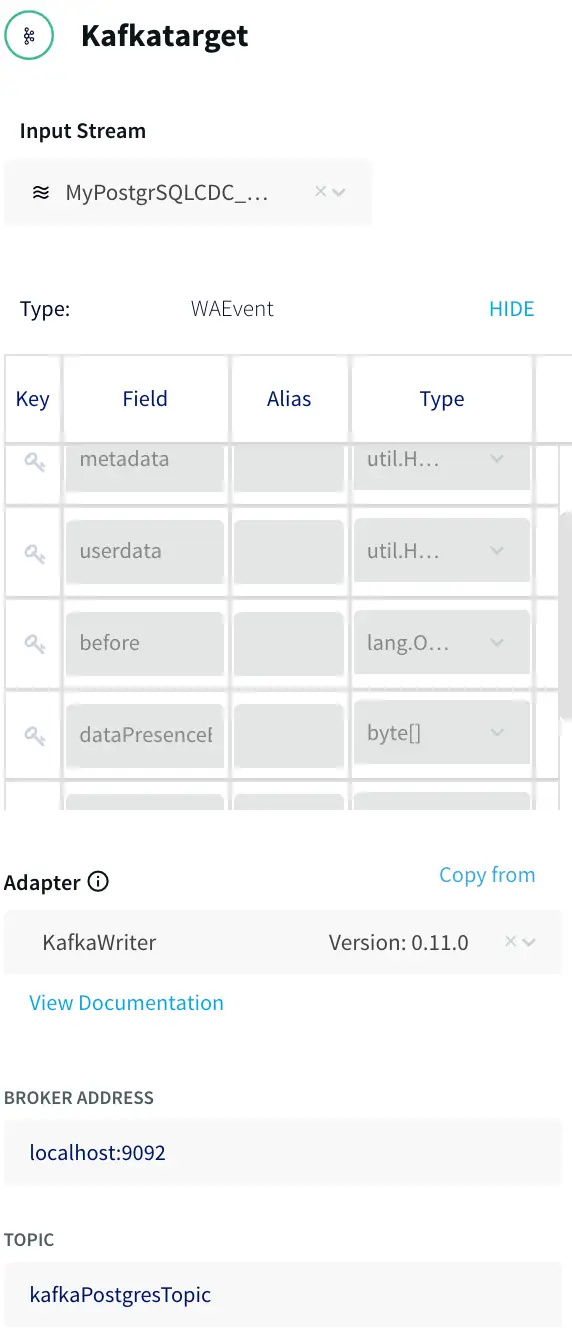
Configuring the Kafka target FORMATTER
Step 4: Deploying and Starting the Data Flow
The resulting data flow can now be modified, deployed, and started through the UI. In order to run the application, it first needs to be deployed, click on the ‘Created’ dropdown and select ‘Deploy App’ to show the Deploy UI.
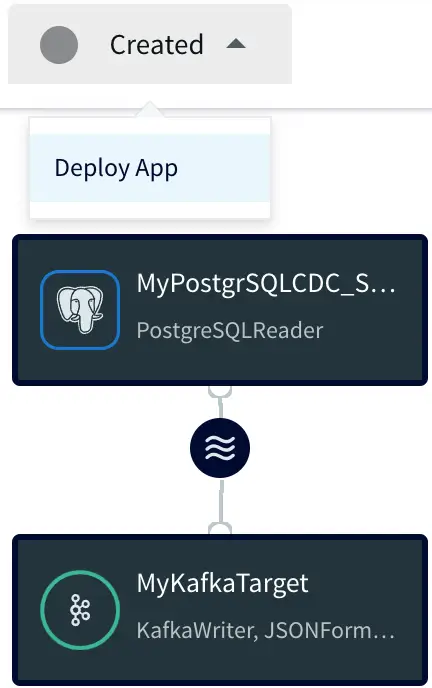
Deploying the app
The application can be deployed to all nodes, any one node, or predefined groups in a Striim cluster, the default is the least used node.
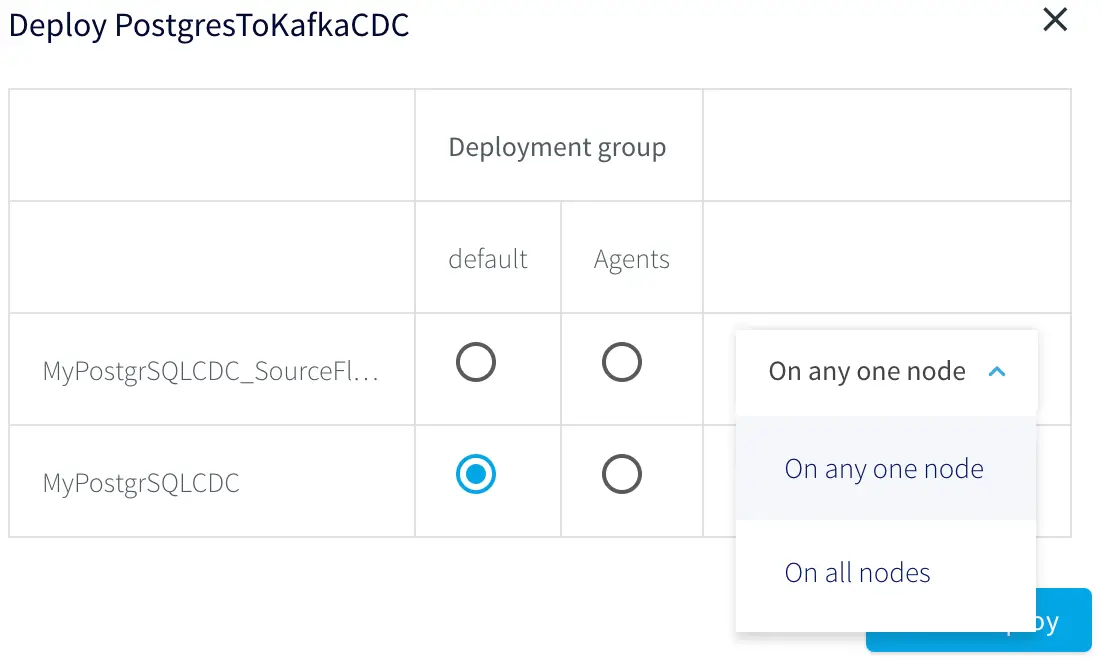
Deployment node selection
After deployment the application is ready to start, by selecting Start App.
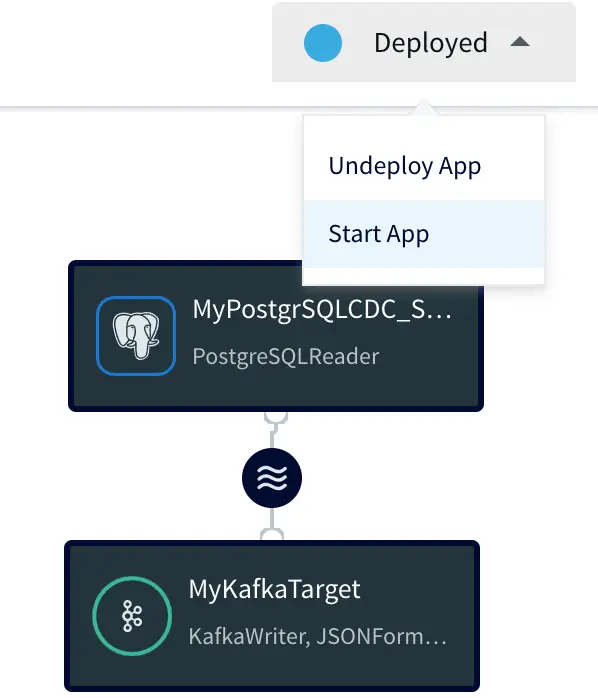
Starting the app
Step 5: Testing the Data Flow
You can use the PostgreSQL to Kafka sample integration application, to insert, delete, and update the PosgtreSQL CDC source table, then you should see data flowing in the UI, indicated by a number of msgs/s. (Note the message sending happens fast and quickly returns to 0).

Testing the streaming data flow
If you now click on the data stream in the middle and click on the eye icon, you can preview the data flowing between PostgreSQL and Kafka. Here you can see the data, metadata (these are all updates) and before values (what the data was before the update).
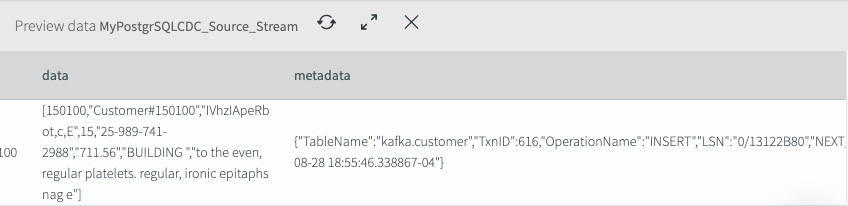
Previewing the data flowing from PostgreSQL to Kafka
There are many other sources and targets that Striim supports for streaming data integration. Please request a demo with one of our lead technologists, tailored to your environment.
Striim
Striim’s unified data integration and streaming platform connects clouds, data and applications.
PostgreSQL
PostgreSQL is an open-source relational database management system.

Snowflake
Snowflake is a cloud-native relational data warehouse that offers flexible and scalable architecture for storage, compute and cloud services.
