Companies Join Forces to Bring Real-Time Change Data Capture (CDC) to the Apache Kafka Community
PALO ALTO, CA, April 26, 2016 – Striim, Inc., providers of an end-to-end, streaming integration + intelligence platform, today announced that it has entered into a partnership with Confluent, Inc., the company founded by the creators of Apache Kafka, to bring real-time change data capture (CDC) to the Kafka ecosystem.
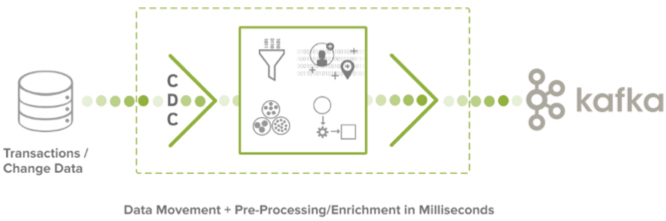
![]() Striim™ provides a non-intrusive solution for moving change data in real time from transactional systems onto Apache™ Kafka™ message queues. Data movement is continuous, the instant the data is born. This simple, cost-effective CDC-to-Kafka delivery solution is managed through a single application that provides enterprise-grade security, scalability and reliability.
Striim™ provides a non-intrusive solution for moving change data in real time from transactional systems onto Apache™ Kafka™ message queues. Data movement is continuous, the instant the data is born. This simple, cost-effective CDC-to-Kafka delivery solution is managed through a single application that provides enterprise-grade security, scalability and reliability.
“As enterprise adoption for Kafka soars, partners like Striim are key to meeting the demands for streaming integration of transactional data,” said Jabari Norton, VP of Business Development at Confluent. “Our joint effort to enable companies to move change data into the Kafka messaging system opens the door to new realms of real-time information distribution throughout the enterprise.”
Confluent™ provides Striim with increased access to the rapidly growing ecosystem around Apache Kafka and the Confluent Platform. Joining forces with Confluent paves the way for Striim to deliver an even more sophisticated streaming integration solution based on the Kafka Connect™ framework, as well as to promote the Striim solution directly to Apache Kafka customers worldwide.
“At Striim, we help companies free data from enterprise databases,” said Sami Akbay, founder and EVP of Striim. “Our partnership with Confluent makes it easy for our joint customers to release their most valuable data and make it available in real time to the organization in a way that is orchestrated, secure and reliable.”
For more advanced applications, Kafka users can leverage the Striim platform to incorporate data transformations, filtering, aggregation, enrichment and correlation of streaming data through simple SQL-like queries as it flows from enterprise databases to Kafka.
About Striim, Inc.
The Striim™ platform makes data useful the instant it’s born. Striim (pronounced “stream”) is the only end-to-end streaming integration + intelligence solution, making it easy to deliver custom streaming analytics applications. The platform enables multi-stream data integration and real-time Change Data Capture (CDC) across a wide variety of data sources including transactions from enterprise databases, log files, message queues, application and IoT sensor data. With the Striim platform, enterprises can aggregate and correlate streams from multiple data pipelines, detect anomalies, identify and visualize events of interest, and trigger alerts and workflows – all in-memory, before data lands on disk. Based in Palo Alto, CA, Striim was founded by the core team from GoldenGate Software, Inc. (acquired by Oracle in 2009), and is backed by leading investors including Intel Capital, Summit Partners, Atlantic Bridge, Frank Caufield, and Regis McKenna. For more information on the Striim platform, please visit www.striim.com, read our blog at www.striim.com/blog/, or follow @striimteam.
About Apache Kafka
Apache™ Kafka™ is an open source technology that acts as a real-time, fault tolerant, highly scalable messaging system. It is widely adopted for use cases ranging from collecting user activity data, logs, application metrics, stock ticker data and device instrumentation. Its key strength is its ability to make high volume data available as a real-time stream for consumption in systems with very different requirements—from batch systems like Hadoop, to real-time systems that require low-latency access, to stream processing engines that transform the data streams as they arrive. This infrastructure lets you build around a single central nervous system transmitting messages to all the different systems and applications within a company.
About Confluent
Confluent™, founded by the creators of Apache Kafka, enables organizations to harness business value from stream data. The Confluent Platform manages the barrage of stream data and makes it available throughout an organization. It provides various industries, from retail, logistics and manufacturing, to financial services and online social networking, a scalable, unified, real-time data pipeline that enables applications ranging from large volume data integration to big data analysis with Hadoop to real-time stream processing. Backed by Benchmark, Data Collective, Index Ventures and LinkedIn, Confluent is based in Palo Alto. To learn more, please visit www.confluent.io. Download Apache Kafka and Confluent Platform at www.confluent.io/download.