










I recently gave a presentation on operationalizing machine learning entitled, “Fast-Track Machine Learning Operationalization Through Streaming Integration,” at Intel AI Devcon 2018 in San Francisco. This event brought together leading data scientists, developers, and AI engineers to share the latest perspectives, research, and demonstrations on breaking barriers between AI theory and real-world functionality. This post provides an overview of my presentation.
Background
The ultimate goal of many machine learning (ML) projects is to continuously serve a proper model in operational systems to make real-time predictions. There are several technical challenges practicing such kind of Machine Learning operationalization. First, efficient model serving relies on real-time handling of high data volume, high data velocity, and high data variety. Second, intensive real-time data pre-processing is required before feeding raw data into models. Third, static models cannot achieve high performance on dynamic data in operational systems even though they are fine-tuned offline. Last but not the least, operational systems demand continuous insights from model serving and minimal human intervention. To tackle these challenges, we need a streaming integration solution, which:
- Filters, enriches and otherwise prepares streaming data
- Lands data continuously, in an appropriate format for training a machine learning model
- Integrates a trained model into the real-time data stream to make continuous predictions
- Monitors data evolution and model performance, and triggers retraining if the model no longer fits the data
- Visualizes the real-time data and associated predictions, and alerts on issues or changes
Striim: Streaming Integration with Intelligence
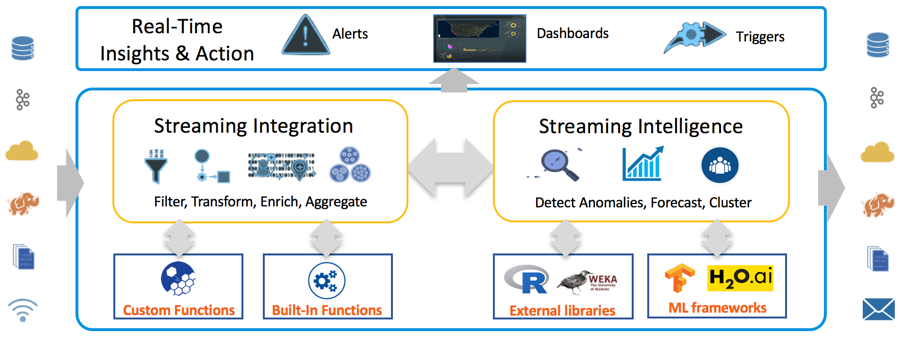
Striim offers a distributed, in-memory processing platform for streaming integration with intelligence. The value proposition of the Striim platform includes the following aspects:
- It provides enterprise-grade streaming data integration with high availability, scalability, recovery, validation, failover, security, and exactly-once processing guarantees
- It is designed for easy extensibility with a broad range of sources and targets
- It contains rich and sophisticated built-in stream processors and also supports customization
- Striim platform includes capabilities for multi-source correlation, advanced pattern matching, predictive analytics, statistical analysis, and time-window-based outlier detection via continuous queries on the streaming data
- It enables flexible integration with incumbent solutions to mine value from streaming data
In addition, it is an end-to-end, easy-to-use, SQL-based platform with wizards-driven UI. Figure 1 describes the overall Striim architecture of streaming integration with intelligence. The architecture enables Striim users to flexibly investigate and analyze their data and efficiently take actions, while the data is moving.
Striim’s Solution of Fast-Track ML Operationalization
The advanced architecture of Striim enables us to leverage it to build a fast-track solution for operationalizing machine learning. Let me walk you through the solution in this blog post using a case of network traffic anomaly detection. In this use case, we deal with three practical tasks. First, we detect abnormal network flows using an offline-trained ML model. Second, we automatically adapt model serving to data evolution to keep a low false positive rate. Third, we continuously monitor the network system and alert on issues in real time. Each of these tasks correspond with a Striim application. For a better understanding with a hands-on experience, I recommend you download the sandbox where Striim is installed and these three applications are added. You can also download full instructions to install and work with the sandbox.
Abnormal network flow detection
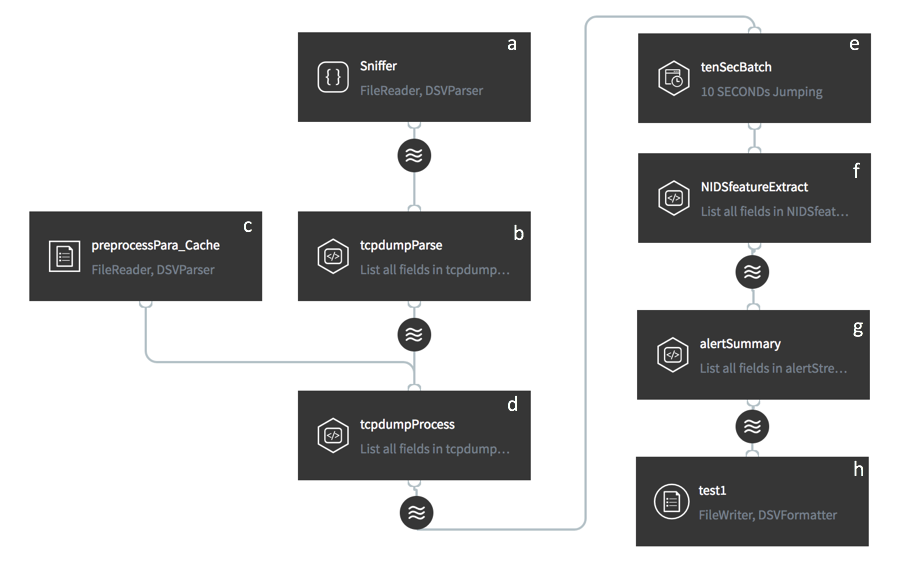
We utilize one-class Support Vector Machine (SVM) to detect abnormal network flows. One-class SVM is a widely used anomaly detection algorithm. It is trained on data that has only one class, which is the normal class. It learns the properties of normal cases and accordingly predict which instances are unlike the normal instances. It is appropriate for anomaly detection because typically there are very few examples of the anomalous behavior in the training data set. We assume that there is an initial one-class SVM model offline trained on historical network flows with specific features. This model is then served online to identify abnormal flows in real time. This task requires us to perform the following steps.
- Ingest raw data from the source (Fig. 2 a);
For ease of demonstration, we use a csv file as the source. Each row of the csv file indicates a network flow with some robust features generated from a tcpdump analyzer. Striim users simply need to designate the file name, and the directory where the file locates, and then select DSVParser to parse the csv file. These configurations can be written in a SQL-based language TQL. Alternatively, Striim web UI can navigate users to make the configurations easily. Note that you can work with virtually any other source in practice, such as NetFlow, database, Kafka, security logs, etc. The configuration is also very straightforward.
- Filter the valuable data fields from data streams (Fig. 2 b);
Data may contain multiple fields, and while not all of them are useful for the specific task, Striim enables users to filter the valuable data fields for their tasks using standard SQL within continuous query (CQ). The SQL code of this CQ is as below, where 44 features plus a timestamp field are selected and converted to the specific types, and an additional field “NIDS” is added to identify the purpose of data usage. Besides, we pause for 15 milliseconds at each row to simulate continuous data streams.
SELECT “NIDS”,TO_DATE(TO_LONG(data[0])*1000), TO_STRING(data[1]), TO_STRING(data[2]), TO_Double(data[3]),TO_STRING(data[4]),TO_STRING(data[5]),TO_STRING(data[6]),TO_Double(data[7]),TO_Double(data[8]), TO_Double(data[9]),TO_Double(data[10]),TO_Double(data[11]),TO_Double(data[12]),TO_Double(data[13]),TO_Double(data[14]),TO_Double(data[15]),TO_Double(data[16]),TO_Double(data[17]),TO_Double(data[18]),TO_Double(data[19]),TO_Double(data[20]),TO_Double(data[21]),TO_Double(data[22]),TO_Double(data[23]),TO_Double(data[24]),TO_Double(data[25]),TO_Double(data[26]),TO_Double(data[27]),TO_Double(data[28]),TO_Double(data[29]),TO_Double(data[30]),TO_Double(data[31]),TO_Double(data[32]),TO_Double(data[33]),TO_Double(data[34]),TO_Double(data[35]),TO_Double(data[36]),TO_Double(data[37]),TO_Double(data[38]),TO_Double(data[39]),TO_Double(data[40]),TO_Double(data[41]),TO_Double(data[42]),TO_Double(data[43]),TO_Double(data[44]) FROM dataStream c WHERE PAUSE(15000L, c)
- Preprocess data streams (Fig. 2 c, d);
To guarantee SVM to perform efficiently, the numerical features need to be standardized. The mean and standard deviation values of these features are stored in cache (c) and used to enrich the data streams output from b. Standardization is then performed in d.
- Aggregate events within a given time interval (Fig. 2 e);
Suppose that the network administration does not want to be overwhelmed with alerts. Instead, he or she cares about a summary for a given time interval, e.g., every 10 seconds. We can use a time bounded (10-second) jumping window to aggregate the pre-processed events. The window size can be flexibly adjusted according to the specific system requirements.
- Extract features and prepare for model input (Fig. 2 f);
Event aggregation not only prevents information overwhelming but also facilitates efficient in-memory computing. Such an operation enables us to extract a list of inputs, where each input contains a specific number of features, and to feed all inputs into the analytics model to get all of the results once. If analytics is done by calling remote APIs (e.g., cloud ML API) instead of in-memory computing, aggregation can additionally decrease the communication cost.
- Detect anomalies using an offline-trained model (Fig. 2 g);
We utilize one-class SVM algorithm from Weka library to perform anomaly detection. A SVM model is first trained and fine-tuned offline using historical network flow data. Then the model is stored as a local file. Striim allows users to call the model in the platform by writing a java function specifying model usage and then wrapping it into a jar file. When there are new network flows streaming into the platform, the model can be applied on the data streams to detect anomalies in real time.
- Persist anomaly detection results into the target (Fig. 2 h).
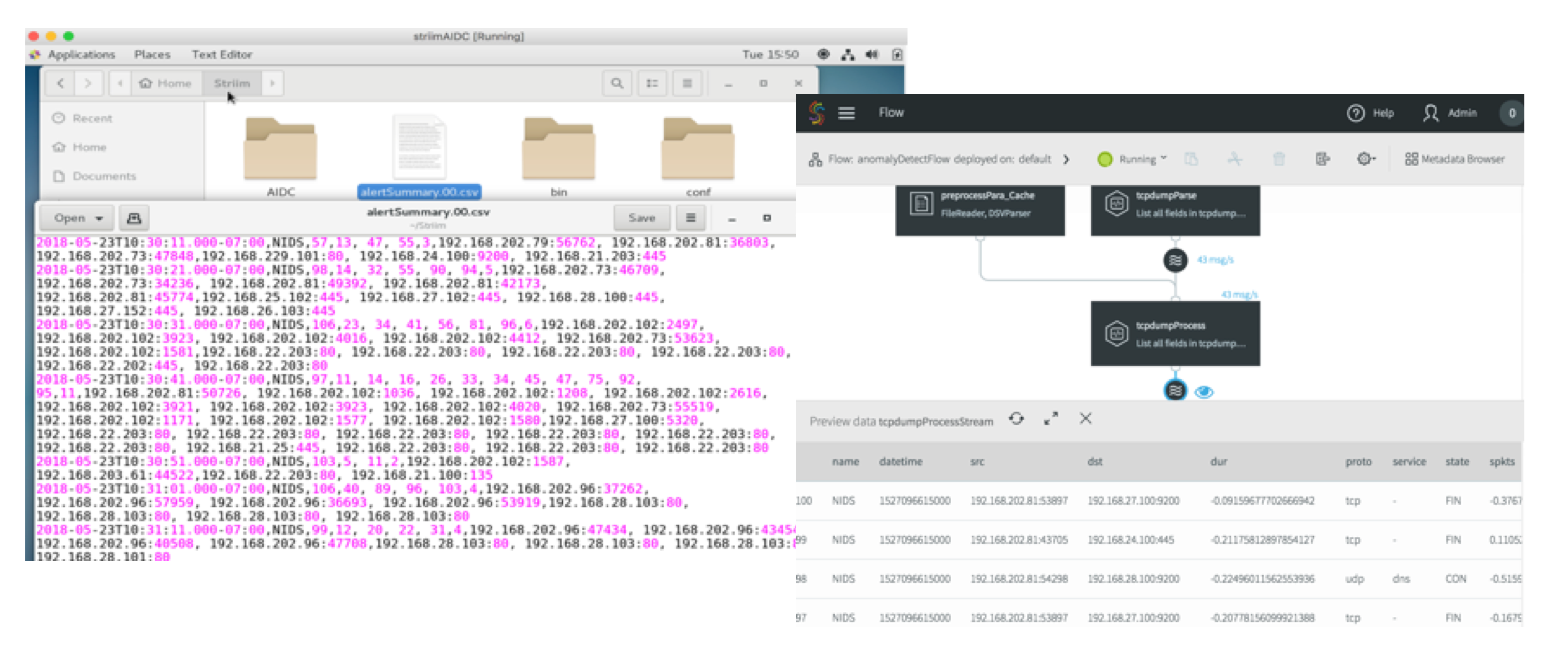
The anomaly detection results can be persisted into a wide range of targets, such as database, files, Kafka, Hadoop, cloud environments etc. Here we choose to persist the results in local files. By deploying and running this first application, you will see the intermediary results by clicking each stream in the flow and see the final results continuously being added in the target files, as shown in Fig. 3.
In part 2 of this two-part post, I’ll discuss how you can use the Striim platform to update your ML models. In the meantime, please feel free to visit our product page to learn more about the features of streaming integration that can support operationalizing machine learning.




