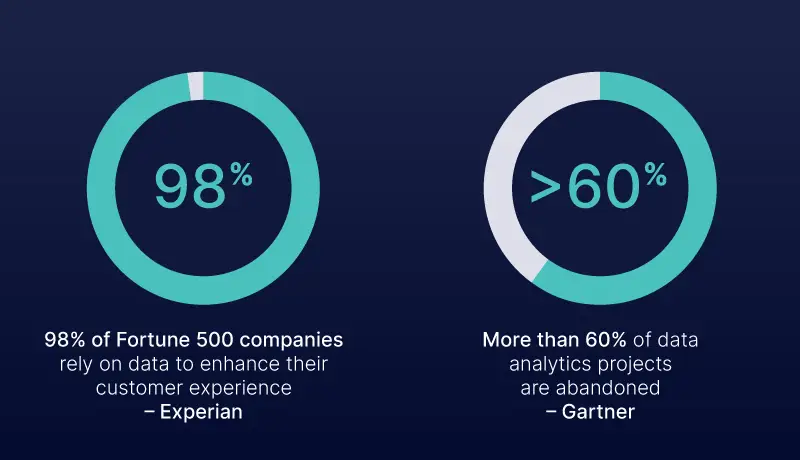
According to a study by Experian, 98% of companies rely on data to enhance their customer experience. In today’s data age, getting data analytics right is more essential than ever. Organizations compete based on how effective their data-driven insights are at helping them with informed decision-making.
However, executing analytics projects is a bane for many. According to Gartner, more than 60% of data analytics projects bite the dust due to fast-moving and complex data landscapes.
Recognizing the modern data challenges, organizations are adopting DataOps to help them handle enterprise-level datasets, improve data quality, build more trust in their data, and exercise greater control over their data storage and processes.
What Is DataOps?
DataOps is an integrated and Agile process-oriented methodology that helps you develop and deliver analytics. It is aimed at improving the management of data throughout the organization.
There are multiple definitions of DataOps. Some think it’s a magic bullet that solves all data management issues. Others think that it just introduces DevOps practices for building data pipelines. However, DataOps has a broader scope that goes beyond data engineering. Here’s how we define it:
DataOps is an umbrella term that can include processes (e.g., data ingestion), practices (e.g., automation of data processes), frameworks (e.g., enabling technologies like AI), and technologies (e.g., a data pipeline tool) that help organizations to plan, build, and manage distributed and complex data architectures. This includes management, communication, integration and development of data analytics solutions, such as dashboards, reports, machine learning models, and self-service analytics.
DataOps aims to eliminate silos between data, software development, and DevOps teams. It encourages line-of-business stakeholders to coordinate with data analysts, data scientists, and data engineers.
The goal of DataOps is to use Agile and DevOps methodologies to ensure that data management aligns with business goals. For instance, an organization sets a target to increase their lead conversion rate. DataOps can make a difference by creating an infrastructure that provides real-time insights to the marketing team, which can convert more leads.
In this scenario, an Agile methodology can be useful for data governance, where you can use iterative development to develop a data warehouse. Likewise, it can help data science teams use continuous integration and continuous delivery (CI/CD) to build environments for the analysis and deployment of models.
DataOps Can Handle High Data Volume and Versatility
Companies have to tackle high amounts of data compared to a few years ago. They have to process it in a wide range of formats (e.g., graphs, tables, images), while their frequency of using that data varies, too. For example, some reports might be required daily, while others are needed on a weekly, monthly, or ad-hoc basis. DataOps can handle these different types of data and tackle varying big data challenges.
With the advent of the Internet of Things (IoT), organizations have to tackle the demons of heterogeneous data as well. This data comes from wearable health monitors, connected appliances, and smart home security systems.
To manage the incoming data from different sources, DataOps can use data analytics pipelines to consolidate data into a data warehouse or any other storage medium and perform complex data transformations to provide analytics via graphs and charts.
DataOps can use statistical process control (SPC) — a lean manufacturing method — to improve data quality. This includes testing data coming from data pipelines, verifying its status as valid and complete, and meeting the defined statistical limits. It enforces the continuous testing of data from sources to users by running tests to monitor inputs and outputs and ensure business logic remains consistent. In case something goes wrong, SPC notifies data teams with automated alerts. This saves them time as they don’t have to manually check data throughout the data lifecycle.
DataOps Can Secure Cloud Data
Around 75% of companies are expected to move their databases into the cloud by 2022. However, many organizations struggle with data protection after migrating their data to the cloud. According to a survey, 70% of companies have to deal with a security breach in the public cloud.
DataOps borrows some of its elements from DevSecOps — short for development, security, and operations. This fusion is also known as DataSecOps, which can help with data protection. DataSecOps brings a security-focused approach where security is embedded in all data operations and projects from the start.
DataSecOps offers security by focusing on five areas:
- Awareness – Improve the understanding of data sets and their sensitivity by using data dictionaries or data catalogs.
- Policy – Incorporate and uphold a data access policy that makes it crystal clear who can access data and what form of data they can access.
- Anonymization – Introduce anonymization into the data access’ security layer, ensuring that business users, who aren’t supposed to view personal identifiable information (PII) data, aren’t able to see it in the first place.
- Authentication – Provide a user interface for managing data access and tools.
- Audit – Offer the ability to track, report, and audit access when required, as well as develop and monitor access control.
DataOps Can Improve Time to Value
The time it takes to turn a raw idea into something of value is integral to businesses. DataOps reduces lead time with its Agile-based development processes. The waiting time across phases decreases too. In addition, the approach of building and making releases in small fragments enables solutions to be implemented in a gradual manner.
If you develop data solutions at a slow pace, then it might lead to shadow IT. Shadow IT happens when other departments build their own solutions without the approval or involvement of the IT department.
DataOps can increase your development speed by getting feedback to you faster via sprints. Sprints are short iterations where a team is tasked with completing a specific amount of work. A sprint review occurs at the end of each sprint, which allows continuous feedback from data consumers. This feedback also brings more clarity by allowing the feedback to steer the development and create a solution that your data consumer wants.
DataOps Can Automate Repetitive and Menial Tasks
Around 18% of a data engineer’s time is spent on troubleshooting. DataOps brings a focus to automation to help data professionals save time and focus on more valuable high-priority tasks.
Consider one of the most common tasks in the data management lifecycle: data cleaning. Some data professionals have to manually modify and remove data that is incomplete, duplicate, incorrect, or flawed in any way. This process is repetitive and doesn’t require any critical thinking. You can automate it by either setting your customized scripts or installing a built-in data cleaning software.
Some other processes that can be automated include:
- Simplifying data maintenance tasks like tuning a data warehouse
- Streamlining data preparation tasks with a tool like KNIME
- Improving data validation to identify flags and typos, such as types and range
Build Your Own DataOps Architecture with Striim
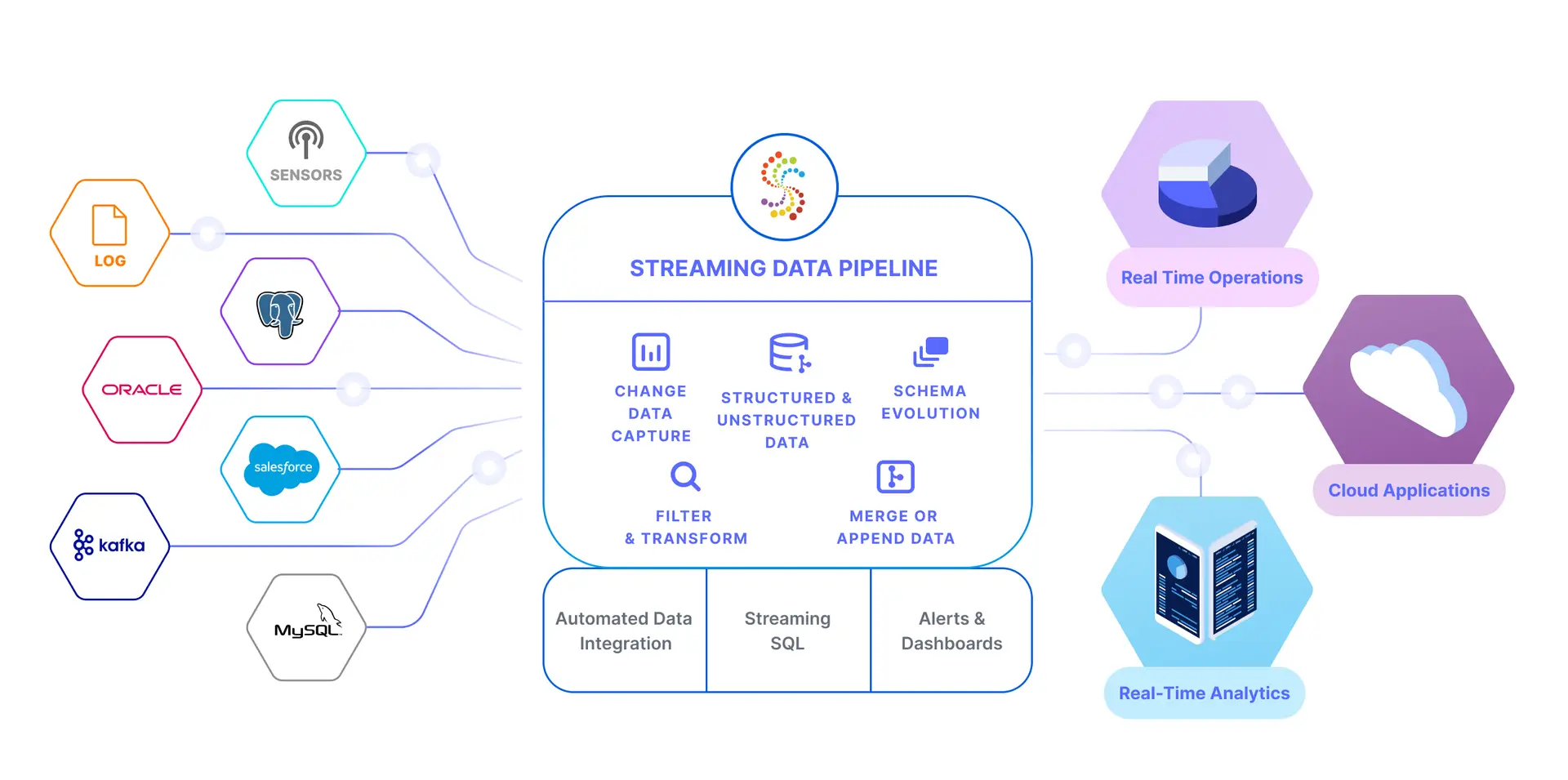
To develop your own DataOps architecture, you need a reliable set of tools that can help you improve your data flows, especially when it comes to key aspects of DataOps, like data ingestion, data pipelines, data integration, and the use of AI in analytics. Striim is a unified real-time data integration and streaming platform that integrates with over 100 data sources and targets, including databases, message queues, log files, data lakes, and IoT. Striim ensures the continuous flow of data with intelligent data pipelines that span public and private clouds. To learn more about how you can implement DataOps with Striim, get a free demo today.


