Change Data Capture to Data Lakes and Data Warehouses on AWS
Rapidly Set Up Real-Time Data Streams
Break Down Data Silos with Smart Data Pipelines
Fully Managed Data Streaming with Unprecedented Speed and Simplicity
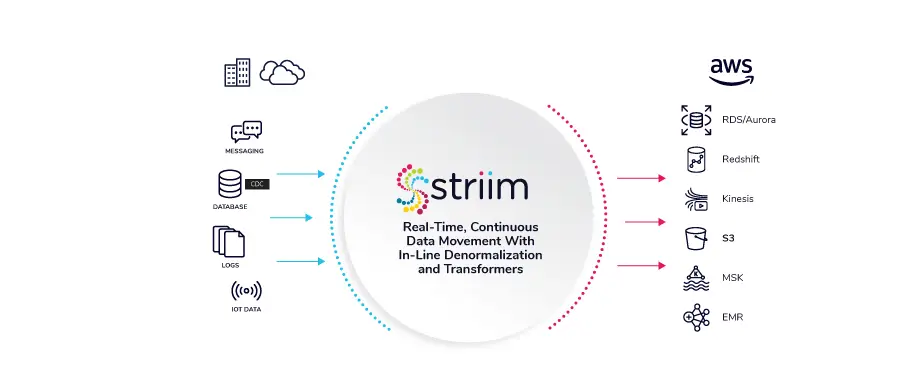
Striim moves real-time data from virtually any data source, including enterprise databases via log-based change data capture (CDC), other cloud environments, log files, applications, messaging systems, and IoT into AWS. AWS customers can rapidly build real-time data pipelines to Amazon Redshift, Amazon S3, Amazon RDS for Oracle, Amazon RDS for SQL Server, Amazon RDS for MySQL, Amazon Aurora, and Amazon Kinesis services to enable up-to-date data for critical workloads in the cloud. With real-time data synchronization capabilities, Striim also helps AWS customers move data from legacy databases to AWS RDS or Aurora databases with zero downtime and zero data loss, and enables an immediate switchover to the AWS environment.
Data Streaming to Amazon Redshift with Striim
Striim enables secure, reliable, and scalable real-time data pipelines for unstructured, semi-structured, and structured data into Amazon Redshift.
Industry's Fastest Oracle CDC to AWS RDS, S3, Databricks, Kinesis, MSK and other AWS Platforms
Leverage the industry’s fastest, cloud-scale Oracle CDC as a fully managed service on AWS to stream real-time data to all your AWS Platforms.
Striim Cloud on AWS
Build smart data pipelines on AWS in minutes with out-of-the-box support for top AWS targets like S3, Kinesis, Redshift, MSK and more.
Usage-Based Pricing that Scales with Your Business Needs
Scale your consumption up and down as needed. Whether you're processing billions of events per hour or on stand-by for new events, Striim meters exactly what you use.
Striim is a unified data integration and streaming platform that enables real-time analytics across every facet of your operations. Keep data flowing from legacy solutions, proactively run your business, and reach new levels of speed and performance with Striim’s change data capture (CDC) for real-time ETL.