Here’s the thing: Getting a 500: Server error is never good news to a business, regardless of its source. Granted, the error could stem from a number of issues, but what happens when a problem with your database is the cause of the error? Are you going to start panicking because you don’t have a backup, or would you be calm, assured that your replica is up and running?
This is just one of the uses of MySQL replication. Replication is the process of copying data from one database (source) to another (replica). The data copied can be part or all of the information stored in the source database. MySQL database replication is carried out according to the business needs — and if you’re considering having a replica, here’s what you need to know.
Why Replication?
Replication may seem expensive from afar — and it usually is if you consider time and effort expended. On a closer look and in the long run, you’ll see it delivers great value to your business. It saves you time, and more money, in the future.
Most of the benefits of replication revolve around the availability of the database. However, it also ensures the durability and integrity of the data stored.
Replication Improves the Server’s Performance
HTTP requests to the server are either read (SELECT) or write(CREATE, UPDATE, DELETE) queries. An application may require a large chunk of these queries per minute, and these may, in turn, slow down the server. With replicas, you can distribute the load in the database.
For example, if the bulk of your requests are read queries, you can have the source server handle all write operations on the server, and then the replicas can be read-only. As a result, your server becomes more efficient as this load is spread across the databases. Doing this also helps avoid server overload.
Replication Allows for Easier Scalability
As a business grows, there is often a heavier load on the server. You can tackle this extra load by either scaling vertically by getting a bigger database or scaling horizontally by distributing your database’s workload among its replicas. However, scaling vertically is often a lengthy process because it takes a while — from several hours to a few months — to fully migrate your data from one database to another.
When scaling horizontally, you spread the load without worrying about reaching the load limit of any one database — at least for a while. You also do not need to pause or restart your server to accommodate more load as you would have done when moving your data to another database.
Replication Improves Application Availability (Backup)
Without replicas, you might have to do backups on tape, and in the event of a failover, it could take hours before the system is restored. And when it’s fully restored, it’ll only contain data from the last backup; the latest data snapshot is often lost. Having replicas means you can easily switch between databases when one fails without shutting down the server.
You can automate the switch so that once a source stops responding, queries are redirected to a replica in the shortest time possible. Then, when the source is back online, it can quickly receive updates to the replica.
Replication Provides an Easy Way to Pull Analytics
Pulling analytics on data stored in the database is a common procedure, and replication provides a hassle-free way to do this. You can draw insights for analytics from replicas, so you avoid overloading the source. Doing this also helps preserve the data integrity of the source — the information remains untouched, preventing any tampering with the data (whether by accident or otherwise).
Otherwise, the source can always sync up with the replica to get the latest data snapshot as needed.
Whatever the size of your database, MySQL replication is beneficial — especially if you intend to grow your business. First, figure out if and how replication affects your business and go from there to decide how many replicas to have and which replication method to use.
Use Cases For MySQL Replication
MySQL replication allows you to make exact copies of your database and update them in near real-time, as soon as updates to your source database are made. There are several cases where MySQL replication is helpful, and a few of them include:
Backups
Data backups are usually performed on a replica so as not to affect the up-time and performance of the source. These backups can be done in three forms: using mysqldump, raw data files, and backing up a source while it’s read-only. For small- to medium-sized databases, mysqldump is more suitable.
Using mysqldump involves three steps:
- Stop the replica from processing queries using mysqladmin stop-replica
- Dump selected or all databases by running mysqldump
- Restart the replication process once the dump is completed. mysqladmin start-replica does that for you.
Since information backed up using mysqldump is in the form of SQL statements, it would be illogical to use this method for larger databases. Instead, raw data files are backed up for databases with large data sets.
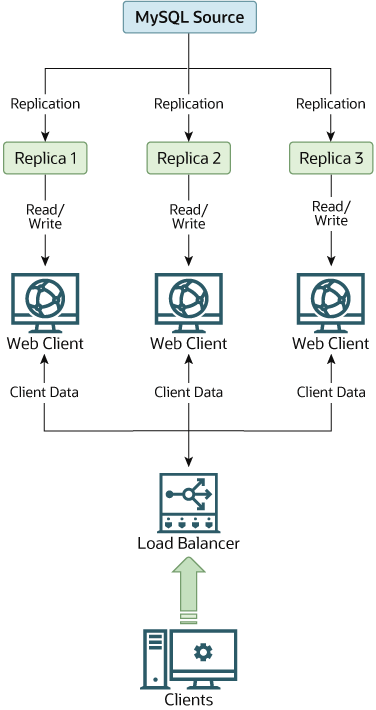
Scaling Out
Using replication to scale out is best for servers with more reads and fewer writes. An example is a server for e-commerce where more users look through your product catalog than users adding to your catalog. You’re then able to distribute the read load from the source to the replicas.
Have an integrated platform for read and write connections to the server and the action of those requests on the server. That platform could be a library that helps carry out these functions. Here’s an example layout of replication for scale-out solutions.
Switching Sources
MySQL allows you to switch your source database when need be (e.g., failover) using the CHANGE REPLICATION SOURCE TO statement. For example, say you have a source and three replicas, and that source fails for some reason. You can direct all read/write requests to one of the replicas and have the other two replicate from your new source. Remember to STOP REPLICA and RESET MASTER on the new source.
Once the initial source is back, it can replicate from the active source using the same CHANGE REPLICATION SOURCE TO statement. To revert the initial source to source, follow the same procedure used to switch sources above.
Whatever your reason for adopting MySQL replication, there’s extensive documentation on MySQL statements that can help you achieve your replication goal.
The Common Types of MySQL Replication
You can set up MySQL replication in a number of ways, depending on many factors. These factors include the type of data, the quantity of the data, the location, and the type of machines involved in the replication.
To help you determine the right type of MySQL replication for your needs, let’s review the most common MySQL replication types:
Snapshot Replication
As the name implies, snapshot replication involves taking a picture-like replica of a database. It makes an exact replication of the database at the time of the data snapshot. Because it’s a snapshot, the replica database does not track updates to the source. Instead, you take snapshots of the source at intervals with the updates included.
Snapshot replication is simple to set up and easy to maintain and is most useful for data backup and recovery. And the good news is that it’s included by default in a lot of database services.
Merge Replication
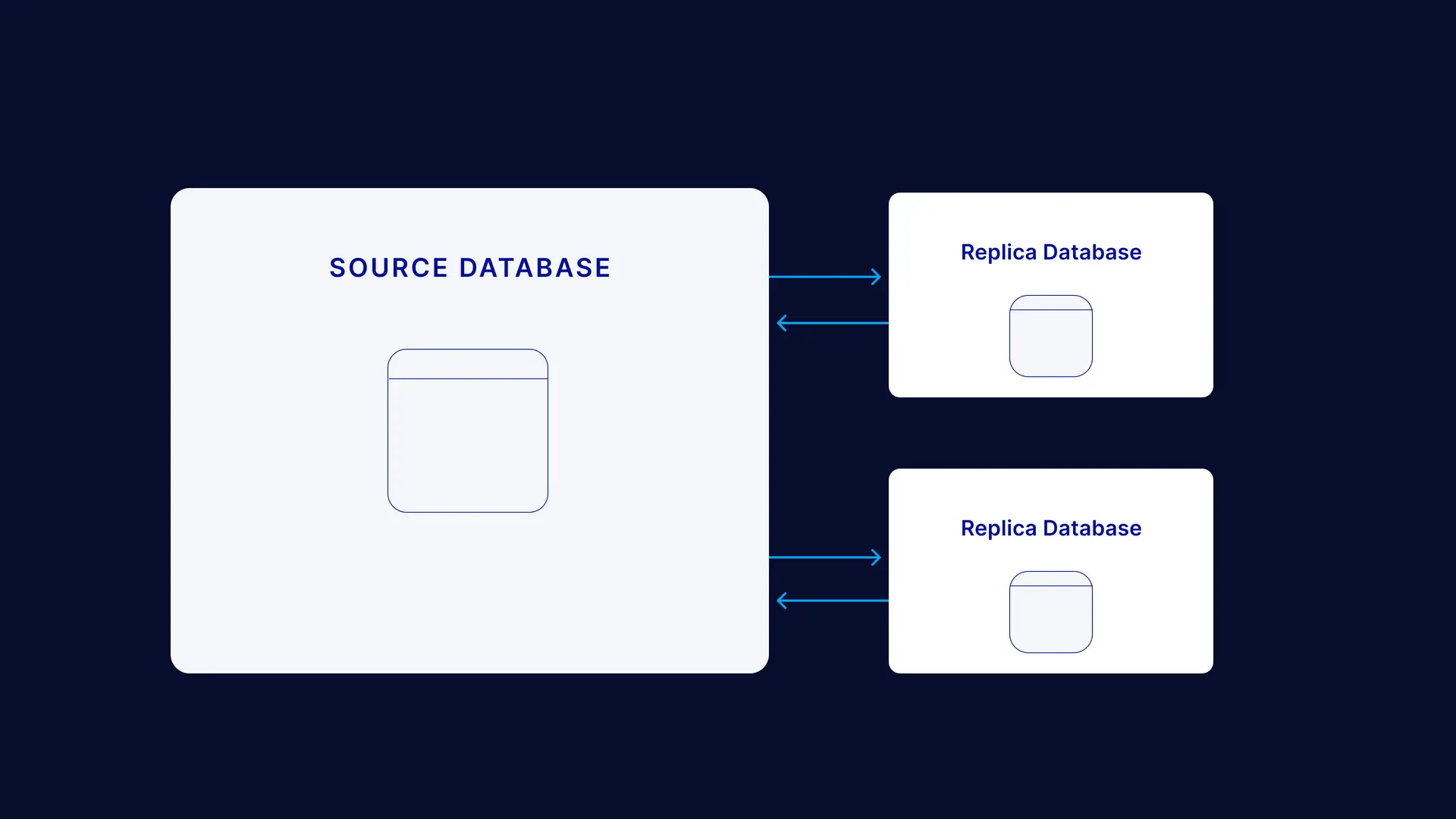
The word “merge” means to combine or unite to form a single entity. That’s the basis for merge replication — it unites data from the source database with the replica. Merge replication is bidirectional: changes to the source are synchronized with the replicas and vice versa.
You can use merge replication when there are multiple replicas working autonomously, and the data on each database needs to be synchronized at certain operational levels of the server. It is mostly used in server-client environments.
An example of a merge replication use case would be a retail company that maintains a warehouse and tracks the stock levels in a central (source) database. Stores in different locations have access to replica databases, where they can make changes based on products sold (or returned). These changes can be synchronized with the source database. In turn, changes to the source database are synchronized with the replicas, so that everyone has up-to-date inventory information.
Transactional Replication
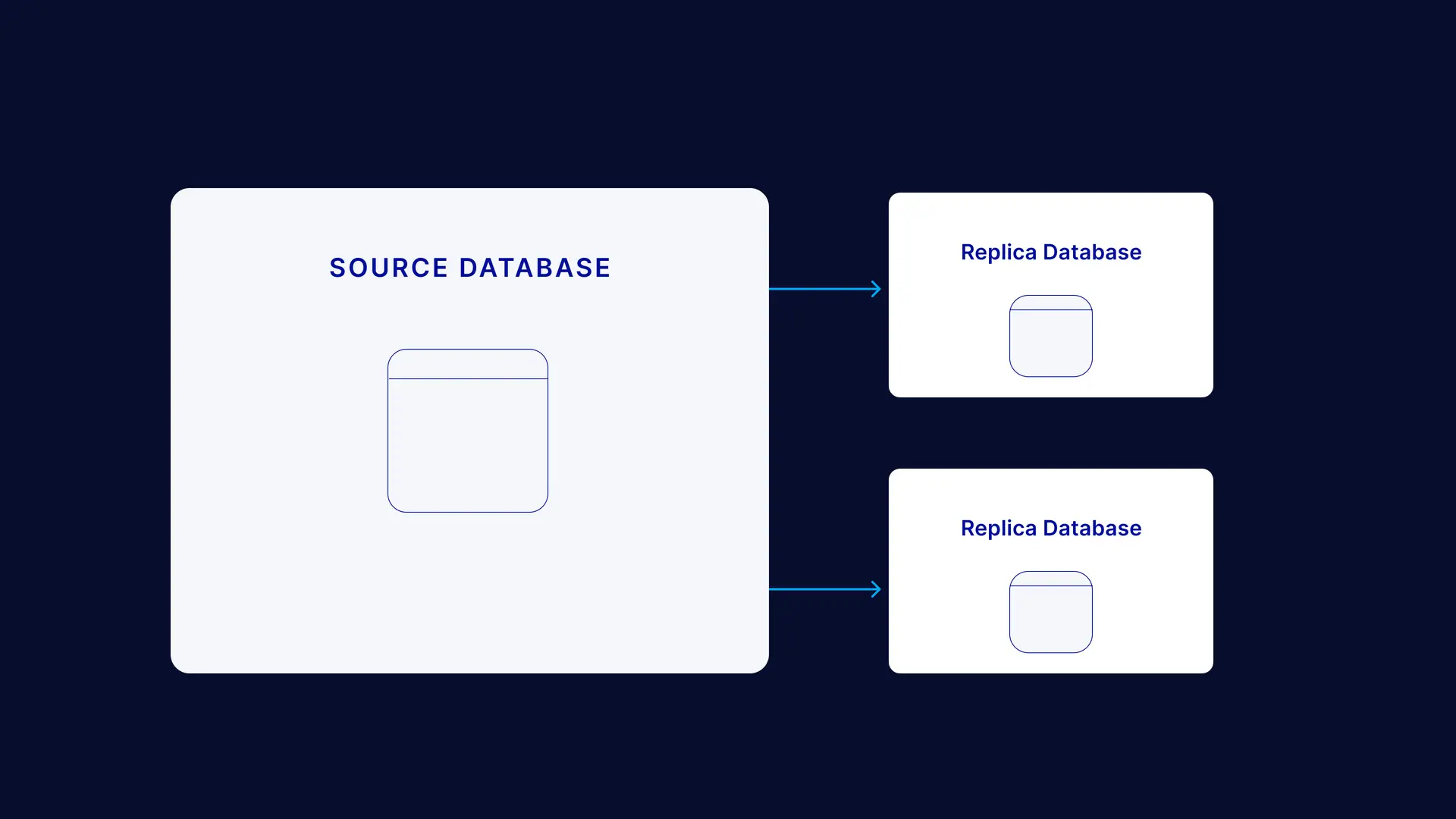
Transactional replication begins with a snapshot of the source database. Subsequent changes to the source are replicated in the replica as they occur in near real-time and in the same order as the source. Thus, updates to the replica usually happen as a response to a change in the source.
Replicas in transactional replication are typically read-only, although they can also be updated. Therefore, transactional replication is mainly found in server-server environments, for instance, multi-region/zone databases.
There are a few other MySQL replication types, but one feature is common to all, including those discussed above. Each replication typically starts with an initial sync with the source database. After that, they branch out to their respective processes and use cases.
The Power of Leveraging Your MySQL Replicas
We’ve established the importance and advantages of replicating your databases, but keeping up with changes or corruption to the database can be a struggle for a lot of production teams. To top that, you need to know how your data is ingested and delivered and, more importantly, ensure this process of ingestion and delivery is continuous.
With Striim, you can easily see and understand the state of your data workflow at any given time. Whether your server is on-premise, cloud-based or hybrid, you can still create data flows and have control over how your data is gathered, processed, and delivered. We’re ready when you are.



{kind=link}