If your modern applications run on MongoDB, you’re sitting on a goldmine of operational data. As a leading NoSQL database, MongoDB is an unparalleled platform for handling the rich, semi-structured, high-velocity data generated by web apps, microservices, and IoT devices.
But operational data is only half the equation. To turn those raw application events into predictive models, executive dashboards, and agentic AI, that data needs to land in a modern data lakehouse. That is where Databricks comes in.
The challenge is getting data from MongoDB into Databricks without breaking your architecture, ballooning your compute costs, or serving your data science teams stale information.
For modern use cases—like dynamic pricing, in-the-moment fraud detection, or real-time customer personalization—a nightly batch export isn’t fast enough. To power effective AI and actionable analytics, you need to ingest MongoDB data into Databricks in real time.
If you’re a data leader or architect tasked with connecting these two powerful platforms, you likely have some immediate questions: Should we use native Spark connectors or a third-party CDC tool? How do we handle MongoDB’s schema drift when writing to structured Delta tables? How do we scale this without creating a maintenance nightmare?
This guide will answer those questions. We’ll break down exactly how to architect a reliable, low-latency pipeline between MongoDB and Databricks.
What you’ll learn in this article:
- A comprehensive trade-offs matrix comparing batch, native connectors, and streaming methods.
- A selection flowchart to help you choose the right integration path for your architecture.
- A POC checklist for evaluating pipeline solutions.
- A step-by-step rollout plan for taking your MongoDB-to-Databricks pipeline into production.
Why Move Data from MongoDB to Databricks?
MongoDB is the operational engine of the modern enterprise. It excels at capturing the high-volume, flexible document data your applications generate: from e-commerce transactions and user sessions to IoT telemetry and microservice logs.
Yet MongoDB is optimized for transactional (OLTP) workloads, not heavy analytical processing. If you want to run complex aggregations across years of historical data, train machine learning models, or build agentic AI systems, you need a unified lakehouse architecture. Databricks provides exactly that. By pairing MongoDB’s rich operational data with Databricks’ advanced analytics and AI capabilities, you bridge the gap between where data is created and where it becomes intelligent.
When you ingest MongoDB data into Databricks continuously, you unlock critical business outcomes:
- Faster Decision-Making: Live operational data feeds real-time executive dashboards, allowing leaders to pivot strategies based on what is happening right now, not what happened yesterday.
- Reduced Risk: Security and fraud models can analyze transactions and detect anomalies in the moment, flagging suspicious activity before the damage is done.
- Improved Customer Satisfaction: Fresh data powers hyper-personalized experiences, in-the-moment recommendation engines, and dynamic pricing that responds to live user behavior.
- More Efficient Operations: Supply chain and logistics teams can optimize routing, inventory, and resource allocation based on up-to-the-minute telemetry.
The Metrics That Matter To actually achieve these outcomes, “fast enough” isn’t a strategy. Your integration pipeline needs to hit specific, measurable targets. When evaluating your MongoDB to Databricks architecture, aim for the following SLAs:
- Latency & Freshness SLA: Sub-second to low-single-digit seconds from a MongoDB commit to visibility in a Databricks Delta table.
- Model Feature Lag: Under 5 seconds for real-time inference workloads (crucial for fraud detection and dynamic pricing).
- Dashboard Staleness: Near-zero, ensuring operational reporting reflects the current, trusted state of the business.
- Cost per GB Ingested: Optimized to minimize compute overhead on your source MongoDB cluster while avoiding unnecessary Databricks SQL warehouse costs for minor updates.
Common Use Cases for MongoDB to Databricks Integration
When you successfully stream MongoDB data into Databricks, you move beyond a static repository towards an active, decision-ready layer of your AI architecture.
Here is how data teams are leveraging this integration in production today:
Feeding Feature Stores for Machine Learning Models
Machine learning models are hungry for fresh, relevant context. For dynamic pricing models or recommendation engines, historical batch data isn’t enough; the model needs to know what the user is doing right now. By streaming MongoDB application events directly into Databricks Feature Store, data scientists can ensure their real-time inference models are always calculating probabilities based on the freshest possible behavioral context.
Real-Time Fraud Detection and Anomaly Detection
In the financial and e-commerce sectors, milliseconds matter. If a fraudulent transaction is committed to a MongoDB database, it needs to be analyzed immediately. By mirroring MongoDB changes into Databricks in real time, security models can evaluate transactions against historical baselines on the fly, triggering alerts or blocking actions before the user session ends.
Customer Personalization and Recommendation Engines
Modern consumers expect hyper-personalized experiences. If a user adds an item to their cart (recorded in MongoDB), the application should instantly recommend complementary products. By routing that cart update through Databricks, where complex recommendation algorithms reside, businesses can serve tailored content and offers while the customer is still active on the site, directly driving revenue.
Operational Reporting and Dashboards
Executive dashboards shouldn’t wait hours or days for updates. Supply chain managers, logistics coordinators, and financial officers need a single source of truth that reflects the current reality of the business. Streaming MongoDB operational data into Databricks SQL allows teams to query massive datasets with sub-second latency, ensuring that BI tools like Tableau or PowerBI always display up-to-the-minute metrics.
Methods for Moving MongoDB Data into Databricks
There is no single “right” way to connect MongoDB and Databricks; the best method depends entirely on your SLA requirements, budget, and engineering bandwidth.
Broadly speaking, teams choose from three architectural patterns. Here is a quick summary of how they stack up:
Integration Method |
Speed / Data Freshness |
Pipeline Complexity |
Scalability |
Infrastructure Cost |
AI/ML Readiness |
| Batch / File-Based | Low (Hours/Days) | Low | Medium | High (Compute spikes) | Poor |
| Native Spark Connectors | Medium (Minutes) | Medium | Low (Impacts source DB) | Medium | Fair |
| Streaming CDC | High (Sub-second) | High (if DIY) / Low (with managed platform) | High | Low (Continuous, optimized) | Excellent |
Let’s break down how each of these methods works in practice.
Batch Exports and File-Based Ingestion
This is the traditional, manual approach to data integration. A scheduled job (often a cron job or an orchestration tool like Airflow) runs a script to export MongoDB collections into flat files—typically JSON or CSV formats. These files are then uploaded to cloud object storage (like AWS S3, Azure Data Lake, or Google Cloud Storage), where Databricks can ingest them.
- The Pros: This approach is conceptually simple and requires very little initial engineering effort.
- The Cons: Batched jobs are notoriously slow. By the time your data lands in Databricks, it is already stale. Furthermore, running massive query exports puts heavy, periodic strain on your MongoDB operational database.
It’s worth noting that Databricks Auto Loader can partially ease the pain of file-based ingestion by automatically detecting new files and handling schema evolution as the files arrive. However, Auto Loader can only process files after they are exported; your data freshness remains entirely bound by your batch schedule.
Native Spark/MongoDB Connectors
For teams already heavily invested in the Databricks ecosystem, a common approach is to use the official MongoDB Spark Connector. This allows a Databricks cluster to connect directly to your MongoDB instance and read collections straight into Spark DataFrames.
- The Pros: It provides direct access to the source data and natively handles MongoDB’s semi-structured BSON/JSON formats.
- The Cons: This method is not optimized for continuous, real-time updates. Polling a live database for changes requires running frequent, heavy Spark jobs. Worse, aggressive polling can directly degrade the performance of your production MongoDB cluster, leading to slow application response times for your end users.
- The Verdict: It requires careful cluster tuning and significant maintenance overhead to manage incremental loads effectively at scale.
Streaming Approaches and Change Data Capture (CDC)
If your goal is to power real-time AI, ML, or operational analytics, Change Data Capture (CDC) is the gold standard. Instead of querying the database for data, CDC methods passively tap into MongoDB’s oplog (operations log) or change streams. They capture every insert, update, and delete exactly as it happens and stream those events continuously into Databricks.
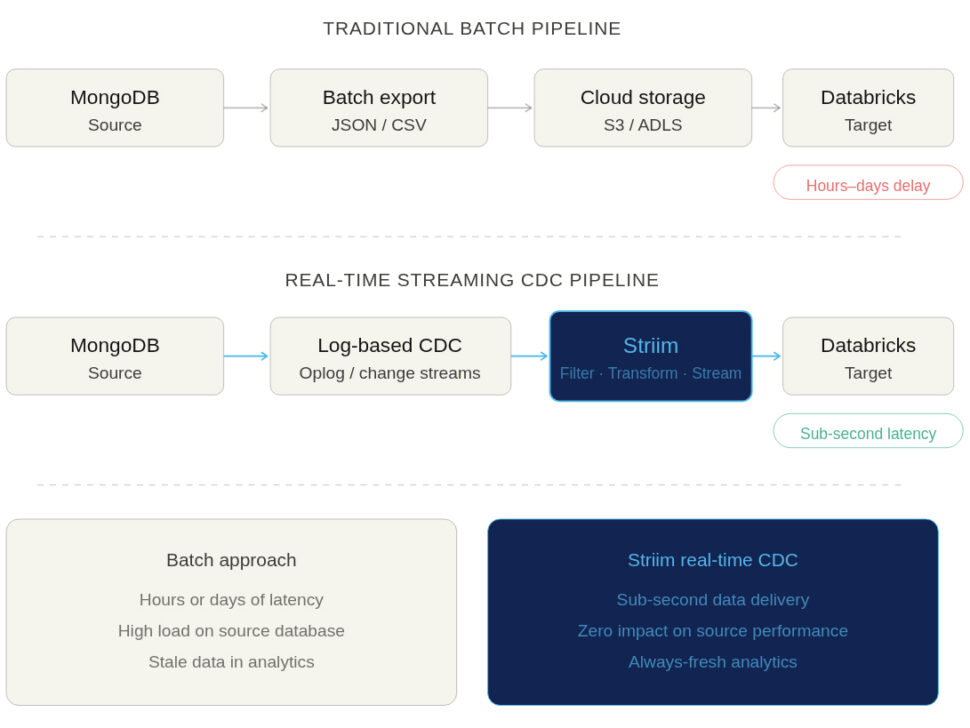
- Why it matters for AI/ML: Predictive models and real-time dashboards degrade rapidly if their underlying data isn’t fresh. Streaming CDC ensures that Databricks always reflects the exact, current state of your operational applications.
- The Complexity Warning: While the architectural concept is elegant, building a CDC pipeline yourself is incredibly complex. Not all CDC tools or open-source frameworks gracefully handle MongoDB’s schema drift, maintain strict event ordering, or execute the necessary retries if a network failure occurs. Doing this reliably requires enterprise-grade stream processing.
Challenges of Integrating MongoDB with Databricks
Connecting an operational NoSQL database to an analytical Lakehouse represents a paradigm shift in how data is structured and processed. While pulling a small, one-off snapshot might seem trivial, the underlying challenges are severely magnified when you scale up to millions of daily events.
Before building your pipeline, your data engineering team must be prepared to tackle the following hurdles.
Latency and Stale Data in Batch Pipelines
The most immediate challenge is the inherent delay in traditional ETL. Delays between a MongoDB update and its visibility in Databricks actively undermine the effectiveness of your downstream analytics and ML workloads. If an e-commerce platform relies on a nightly batch load to update its recommendation engine, the model will suggest products based on yesterday’s browsing session—completely missing the user’s current intent. For high-stakes use cases like fraud detection, a multi-hour delay renders the data practically useless.
Handling Schema Drift and Complex JSON Structures
MongoDB’s greatest strength for developers—its flexible, schema-less document model—is often a data engineer’s biggest headache. Applications can add new fields, change data types, or deeply nest JSON arrays at will, without ever running a database migration. However, when landing this data into Databricks, you are moving it into structured Delta tables. If your integration pipeline cannot automatically adapt to evolving document structures (schema drift), your downstream pipelines will break, requiring manual intervention and causing significant downtime.
Ensuring Data Consistency and Integrity at Scale
Moving data from Point A to Point B is easy. Moving it exactly once, in the correct order, while processing thousands of transactions per second, is incredibly difficult. Network partitions, brief database outages, or cluster restarts are inevitable in distributed systems. If your pipeline cannot guarantee exactly-once processing (E1P), you risk creating duplicate events or missing critical updates entirely. In financial reporting or inventory management, a single dropped or duplicated event can break the integrity of the entire dataset.
Managing Infrastructure and Operational Overhead
Many teams attempt to solve the streaming challenge by stitching together open-source tools, for example, deploying Debezium for CDC, Apache Kafka for the message broker, and Spark Structured Streaming to land the data. The operational overhead of this DIY approach is massive. Data engineers end up spending their cycles maintaining connectors, scaling clusters, and troubleshooting complex failures rather than building valuable data products.
Challenge Area |
The Operational Reality |
| Connector Maintenance | Open-source connectors frequently break when MongoDB or Databricks release version updates. |
| Cluster Scaling | Managing Kafka and Spark clusters requires dedicated DevOps resources to monitor memory, CPU, and partition rebalancing. |
| Observability | Tracking exactly where an event failed (was it in the CDC layer, the broker, or the writer?) requires building custom monitoring dashboards. |
| Error Recovery | Restarting a failed streaming job without duplicating data requires complex checkpointing mechanisms that are notoriously hard to configure. |
Best Practices for Powering Databricks with Live MongoDB Data
Building a resilient, real-time pipeline between MongoDB and Databricks is entirely achievable. However, the most successful enterprise teams don’t reinvent the wheel; they rely on architectural lessons from the trenches.
While you can technically build these best practices into a custom pipeline, doing so requires significant engineering effort. That is why leading organizations turn to enterprise-grade platforms like Striim to bake these capabilities directly into their infrastructure.
Here are some best practices to ensure a production-ready integration.
Start With An Initial Snapshot, Then Stream Changes
To build an accurate analytical model in Databricks, you cannot just start streaming today’s changes; you need the historical baseline. The best practice is to perform an initial full load (a snapshot) of your MongoDB collections, and then seamlessly transition into capturing continuous changes (CDC).
Coordinating this manually is difficult. If you start CDC too early, you create duplicates; if you start it too late, you miss events. Platforms like Striim automate this end-to-end. Striim handles the initial snapshot and automatically switches to CDC exactly where the snapshot left off, ensuring your Databricks environment has a complete, gap-free, and duplicate-free history.
Transform And Enrich Data In Motion For Databricks Readiness
MongoDB stores data in flexible BSON/JSON documents, but Databricks performs best when querying highly structured, columnar formats like Parquet via Delta tables. Pre-formatting this data before it lands in Databricks reduces your cloud compute costs and drastically simplifies the work for your downstream analytics engineers.
While you can achieve this with custom Spark code running in Databricks, performing transformations mid-flight is much more efficient. Striim offers built-in stream processing (using Streaming SQL), allowing you to filter out PII, flatten nested JSON arrays, and enrich records in real time, so the data lands in Databricks perfectly structured and ready for immediate querying.
Monitor Pipelines For Latency, Lag, And Data Quality
Observability is non-negotiable. When you are feeding live data to an AI agent or a fraud detection model, you must know immediately if the pipeline lags or if data quality drops. Data teams need comprehensive dashboards and alerting to ensure their pipelines are keeping up with business SLAs.
Building this level of monitoring from scratch across multiple open-source tools is a heavy lift. Striim provides end-to-end visibility out of the box. Data teams can monitor throughput, quickly detect lag, identify schema drift, and catch pipeline failures before they impact downstream analytics.
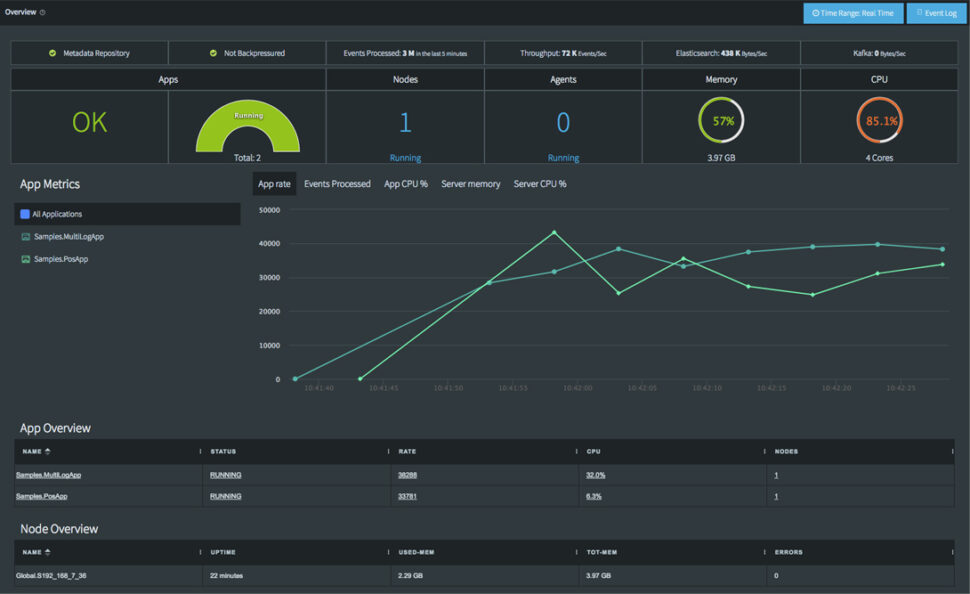
Optimize Delta Table Writes To Avoid Small-File Issues
One of the biggest pitfalls of streaming data into a lakehouse is the “small file problem.” If you write every single MongoDB change to Databricks as an individual file, it will severely degrade query performance and bloat your storage metadata.
To ensure optimal performance, take a strategic approach to batching and partitioning your writes into Databricks. These optimizations are incredibly complex to tune manually in DIY pipelines. Striim handles write optimization automatically, smartly batching micro-transactions into efficiently sized Parquet files for Delta Lake, helping your team avoid costly performance bottlenecks without lifting a finger.
Simplify MongoDB to Databricks Integration with Striim
Striim is the critical bridge between MongoDB’s rich operational data and the Databricks Lakehouse. It ensures that your analytics and AI/ML workloads run on live, trusted, and production-ready data, rather than stale batch exports.
While DIY methods and native connectors exist, they often force you to choose between data freshness, cluster performance, and engineering overhead. Striim uniquely combines real-time Change Data Capture (CDC), in-flight transformation, and enterprise reliability into a single, unified platform. Built to handle massive scale—processing over 100 billion events daily for leading enterprises—Striim turns complex streaming architecture into a seamless, managed experience.
With Striim, data teams can leverage:
- Real-time Change Data Capture (CDC): Passively read from MongoDB oplogs or change streams with zero impact on source database performance.
- Built-in Stream Processing: Use SQL to filter, enrich, and format data (e.g., flattening complex JSON to Parquet) before it ever lands in Databricks.
- Exactly-Once Processing (E1P): Guarantee data consistency in Databricks without duplicates or dropped records.
- Automated Snapshot + CDC: Execute a seamless full historical load that instantly transitions into continuous replication.
- End-to-End Observability: Out-of-the-box dashboards to monitor throughput, latency, and pipeline health.
- Fault Tolerance: Automated checkpointing allows your pipelines to recover seamlessly from network failures.
- Secure Connectivity: Safely integrate both MongoDB Atlas and self-hosted/on-prem deployments.
- Optimized Delta Lake Writes: Automatically batch and partition writes to Databricks to ensure maximum query performance and scalable storage.
Ready to stop managing pipelines and start building AI? Try Striim for free or book a demo with our engineering team today.
FAQs
What is the best way to keep MongoDB data in sync with Databricks in real time?
The most effective method is log-based Change Data Capture (CDC). Instead of running heavy batch queries that degrade database performance, CDC passively reads MongoDB’s oplog or change streams. This allows platforms like Striim to capture inserts, updates, and deletes continuously, syncing them to Databricks with sub-second latency.
How do you handle schema drift when moving data from MongoDB to Databricks?
MongoDB’s flexible document model means fields can change without warning, which often breaks structured Databricks Delta tables. To handle this, your pipeline must detect changes in motion. Enterprise streaming platforms automatically identify schema drift mid-flight and elegantly evolve the target Delta table schema without requiring pipeline downtime or manual engineering intervention.
Why is streaming integration better than batch exports for AI and machine learning use cases?
AI and ML models rely on fresh context to make accurate predictions. If an e-commerce dynamic pricing model is fed via a nightly batch export, it will price items based on yesterday’s demand, losing revenue. Streaming integration ensures that Databricks Feature Stores are updated in milliseconds, allowing models to infer intent and execute decisions based on what a user is doing right now.
How do I choose between native connectors and third-party platforms for MongoDB to Databricks integration?
Native Spark connectors are useful for occasional, developer-led ad-hoc queries or small batch loads. However, if you poll them frequently for real-time updates, you risk severely straining your MongoDB cluster. Third-party CDC platforms like Striim are purpose-built for continuous, low-impact streaming at enterprise scale, offering built-in observability and automated recovery that native connectors lack.
Can Striim integrate both MongoDB Atlas and on-prem MongoDB with Databricks?
Yes. Striim provides secure, native connectivity for both fully managed MongoDB Atlas environments and self-hosted or on-premises MongoDB deployments. This ensures that no matter where your operational data lives, it can be securely unified into your Databricks Lakehouse without creating infrastructure silos.
What are the costs and ROI benefits of using a platform like Striim for MongoDB to Databricks pipelines?
Striim dramatically reduces compute overhead by eliminating heavy batch polling on MongoDB and optimizing writes to avoid Databricks SQL warehouse spikes. The true ROI, however, comes from engineering velocity. By eliminating the need to build, maintain, and troubleshoot complex Kafka/Spark streaming architectures, data engineers can refocus their time on building revenue-generating AI products.
How do you ensure data quality when streaming from MongoDB to Databricks?
Data quality must be enforced before the data lands in your lakehouse. Using in-flight transformations, you can validate data types, filter out malformed events, and mask PII in real time. Furthermore, utilizing a platform that guarantees exactly-once processing (E1P) ensures that network hiccups don’t result in duplicated or dropped records in Databricks.
Can MongoDB to Databricks pipelines support both historical and real-time data?
Yes, a production-grade pipeline should handle both seamlessly. The best practice is to execute an automated snapshot (a full load of historical MongoDB data) and then immediately transition into continuous CDC. Striim automates this hand-off, ensuring Databricks starts with a complete baseline and stays perfectly synchronized moving forward.
What security considerations are important when integrating MongoDB and Databricks?
When moving operational data, protecting Personally Identifiable Information (PII) is paramount. Data should never be exposed in transit. Using stream processing, teams can detect and redact sensitive customer fields (like credit card numbers or SSNs) mid-flight, ensuring that your Databricks environment remains compliant with HIPAA, PCI, and GDPR regulations.
How does Striim compare to DIY pipelines built with Spark or Kafka for MongoDB to Databricks integration?
Building a DIY pipeline requires stitching together and maintaining multiple distributed systems (e.g., Debezium, Kafka, ZooKeeper, and Spark). This creates a fragile architecture that is difficult to monitor and scale. Striim replaces this complexity with a single, fully managed platform that offers sub-second latency, drag-and-drop transformations, and out-of-the-box observability—drastically lowering total cost of ownership.


