
Introduction
Data helps companies take the guesswork out of decision-making. Teams can use data-driven evidence to decide which products to build, features to add, and growth initiatives to pursue. And such insights-driven businesses grow at an annual rate of over 30%.
But there’s a difference between being merely data-aware and insights-driven. Discovering insights requires finding a way to analyze data in near real time, which is where cloud data warehouses play a vital role. As scalable repositories of data, warehouses allow businesses to find insights by storing and analyzing huge amounts of structured and semi-structured data.
And running a data warehouse is more than a technical initiative. It’s vital to the overall business strategy and can inform an array of future product, marketing, and engineering decisions.
But choosing a cloud data warehouse provider can be challenging. Users have to evaluate costs, performance, the ability to handle real-time workloads, and other parameters to decide which vendor best fits their needs.
To help with these efforts, we analyze four cloud data warehouses: Amazon Redshift, Google BigQuery, Azure Synapse Analytics, and Snowflake. We cover the pros and cons of each of these options and dive into the factors you’ll need to consider when choosing a cloud data warehouse.
What is a data warehouse and when should I use one?
A data warehouse is a system that brings data from various sources to a central repository and prepares it for quick retrieval. Data warehouses usually contain structured and semi-structured data pulled from transactional systems, operational databases, and other sources. Engineers and analysts use this data for business intelligence and various other purposes.
Data warehouses can be implemented on-premise, in the cloud, or as a mix of both. The on-premise approach requires having physical servers, which makes scaling more expensive and challenging as users have to buy more hardware. Storing data online is less expensive, and scaling is nearly automated.
When to use a data warehouse.
A data warehouse can be used for various tasks. You can use it to store historical data in a unified environment that acts as a single source of truth. Users from an entire organization can then rely on that repository for day-to-day tasks.
Data warehouses can also unify and then analyze data streams from the web, customer relationship management (CRM), mobile, and other apps. Today’s companies use an ever-growing number of software tools. Pulling data from multiple sources, transforming it into consumable formats, and storing it in a warehouse is vital for making sense of data.
And with valuable data stored in warehouses, you can go beyond traditional analytics tools and query data with SQL to discover deep business insights.
For instance, companies use Google Analytics (GA) to learn how customers engage with their apps or websites. But the depth of insights users can discover is limited by the properties of GA. A better way would be to connect GA with a data warehouse that already stores data from platforms such as Salesforce, Zendesk, Stripe, and others. With all your data stored in one place, it’s much easier to analyze it, compare different variables, and produce insightful data visualizations.
Can’t I just use a database?
Conventional wisdom says you can probably use a OLTP database such as PostgreSQL unless you have terabytes or petabytes of complex data sets. However, cloud computing has made data warehousing cost effective for even smaller data volumes. For instance, BigQuery is free for the first terabyte of query processing. Also the total-cost-of-ownership of serverless cloud data warehouses makes analytics simple. Not to mention there is an expansive ecosystem for data integration, data observability, and business intelligence on top of popular cloud data warehousing tools that can accelerate your analytical operations.
Popular cloud data warehouses
Many of today’s new cloud data warehouses are built using solutions from major vendors such as Amazon Redshift, Google BigQuery, Microsoft Azure Synapse Analytics, and Snowflake.
Major vendors differ in costs or technical details, but they also share some common traits. Their cloud data warehouses are highly reliable. While outages or failures might happen, data replication and other reliability features ensure your data is backed up and can be quickly retrieved.
Amazon, Google, Microsoft, and Snowflake also offer highly scalable cloud data warehouses. Their solutions use massively parallel processing (MPP), a storage structure that handles multiple operations simultaneously, to rapidly scale up or down storage and compute resources. And data is stored in columnar format to achieve better compression and querying.
Compared to on-premise data warehouses, cloud alternatives are more scalable, faster, go live in minutes, and are always up to date.
Data warehouses at-a-glance: Snowflake vs Redshift vs BigQuery vs Azure
| Snowflake | Redshift | BigQuery | Azure | |
| Administration & Management | Simple provisioning. Need to select a cloud provider and virtual warehouse size. | Must select correct instance size and configure and scale nodes manually. Requires AWS expertise. | Completely serverless — provisioning is automatic. | Offers both serverless and dedicated options. |
| Scalability | Users can scale storage and compute independently, Snowflake automatically adds/removes nodes. | Decoupled storage and compute with RA3 nodes. | Storage and compute scale independently. Scaling is handled automatically by BigQuery. | Serverless option scales automatically. For the dedicated option, additional storage must be added manually. |
| Analytics Ecosystem | Analytics ecosystem is wholly based on Snowflake platform (e.g. Snowpark) and partners on Snowflake Partner Connect. | Business intelligence with AWS Quicksight and roster of analytics platforms. | Google workplace (simple Google Sheets upload) and Google Cloud. Business intelligence with Looker. | Azure ecosystem for analytics including PowerBI for business intelligence and CosmosDB for NoSQL. |
| Integrations Ecosystem | Data integration via partners on Snowflake Partner Connect. | Data Integration with AppFlow and DMS along with partners on AWS Marketplace | Native data integration via Cloud Fusion. | Integration supported with Azure Data Factory |
| Ingestion of Streaming Data | Yes, with an added service. For continuous data ingestion, Snowflake offers Snowpipe. Snowpipe loads data within minutes after it’s added to a staging file.
Alternative methods:
|
No, does not offer built-in capability for ingestion of data streams.
Options for ingesting streaming data:
|
Yes. Users can write code that calls the streaming API and inserts one record at a time.
Alternative methods:
|
Yes, users can use the Apache Spark streaming functionality in Azure Synapse to ingest streaming data.
Alternative methods:
|
| Data Backup and Recovery | Yes | |||
| Columnar Architecture | Yes | |||
| Massively Parallel Processing (MPP) | Yes | |||
| Pricing | On-demand pricing or pre-purchase storage capacity at a discount. Compute time is billed separately. | On-demand pricing depending on cluster configuration. Can purchase reserved nodes at a discount. | Choose between on-demand or discounted flat rate pricing for analysis. Pay for both active and long-term storage. | On-demand pricing or option to pre-purchase reserved storage at a discount. |
| Website | Snowflake | Redshift | BigQuery | Azure |
Snowflake
Snowflake is a cloud data warehouse that runs on top of the Google Cloud, Microsoft Azure, and AWS cloud infrastructure. As the service doesn’t run on its own cloud but uses major public cloud vendors, it’s easier for it to move data across clouds and regions.
Snowflake supports a nearly unlimited number of concurrent users and can be run with almost zero maintenance or administration. Updating metadata, vacuuming, and many other menial maintenance tasks are automated. Scaling is automatic as well, with per-second pricing.
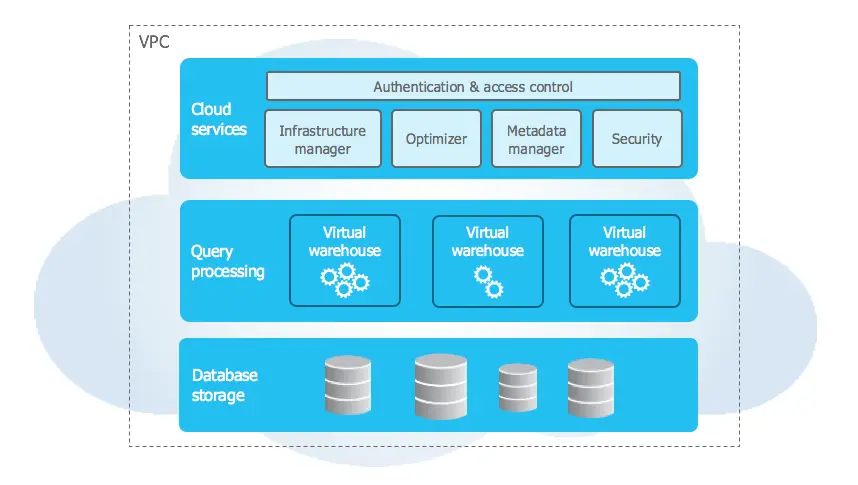
Users can also query semi-structured data with SQL or other BI and ML tools. Snowflake also offers native support for document store formats such as XML, JSON, Avro, and others. And its hybrid architecture is divided into three distinct layers: cloud services layer, compute layer, and storage layer.
Snowflake is growing in popularity and has a number of major customers, including Rakuten. The Japanese ecommerce group uses Snowflake to scale its data resources. The company’s cash back and shopping reward program, called Rakuten Rewards, was using ever-growing amounts of CPU and memory. Demand exceeded the capability of the existing data warehouse.
Rakuten then introduced Snowflake and set up specialized warehouses for individual teams. Workloads from different business units were isolated into different warehouses to prevent them from disrupting each other. This approach was possible because Snowflake separates storage and compute layers. As a result, Rakuten has decreased costs, improved data processing efficiency, and gained more visibility into its data ops. Mark Stange-Tregear, vice president of analytics at Rakuten, says that “I know how much I’m paying to supply the sales team with reports, and I can see how much we are spending to extract data for financial analysis.”
Amazon Redshift
Amazon Redshift is a cloud data warehouse service offered by Amazon. The service handles datasets of various sizes ranging from a few gigabytes to a petabyte or more.
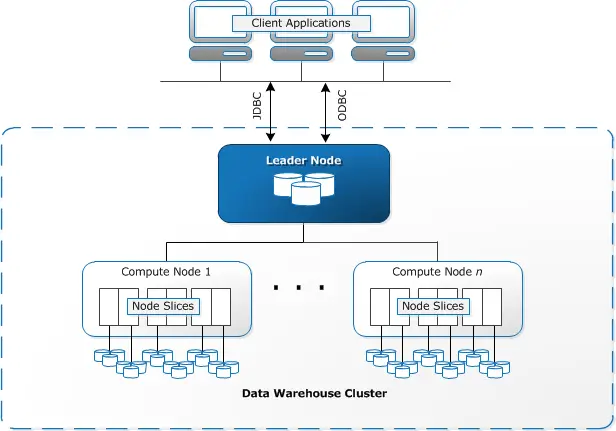
Users initially launch a set of nodes and provision them, after which they upload data and carry out an analysis. Part of a broader Amazon Web Services (AWS) ecosystem, the Redshift data warehousing service offers various features. For instance, users can export data to and from their data lake and integrate with other platforms such as Salesforce, Google Analytics, Facebook Ads, Slack, Jira, Splunk, and Marketo. The warehouse service achieves high performance and efficient storage using columnar storage, data compression, and zone maps.
Redshift boasts tens of thousands of customers, including Pfizer, Equinox, Comcast, and others. In 2020, Amazon also started working with Pizza Hut. The restaurant chain uses Redshift to consolidate data produced by its stores in Asia-Pacific. This data warehouse allows teams to quickly access petabytes of data, run queries, and produce visualizations. Business intelligence reports are now produced in minutes instead of hours. “Within two months, we could see whether the region was hitting sales targets and performance goals with green and red indicators,” says Pin Yiing Kwok, digital experience manager at Pizza Hut Asia-Pacific. “We could also drill down on any potential issues and identify what needed troubleshooting.”
Google BigQuery
BigQuery is a serverless multi-cloud data warehouse offered by Google. The service can rapidly analyze terabytes to petabytes of data.
Unlike Redshift, BigQuery doesn’t require upfront provisioning and automates various back-end operations such as data replication or scaling of compute resources. It encrypts data at rest and in transit automatically.
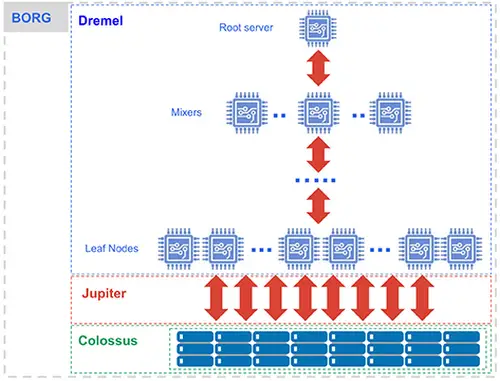
The BigQuery architecture consists of several components. Borg is the overall compute part, while Colossus is the distributed storage. The execution engine is called Dremel, and Jupiter is the network.
BigQuery connects well with other Google Cloud products. Toyota Canada, for instance, has built Build & Price, an online comparison tool that allows site visitors to customize vehicles and get instant quotes. This first-party data is collected by Google Analytics 360 and extracted into BigQuery. The warehousing service then applies machine learning (ML) models on visitors’ data and assigns a propensity score to each individual based on their likelihood of making a purchase. The predictions are refreshed every eight hours.
Toyota’s team then pulls these predictions back into Analytics 360. The team creates 10 audiences using propensity scores and runs personalized ads to each group in a bid to move them down the sales funnel.
BigQuery is also used by many other well-known customers such as Dow Jones, Twitter, The Home Depot, and UPS.
Azure Synapse Analytics
Azure Synapse Analytics is a cloud-based data warehouse offered by Microsoft. The service brings together data warehousing, data integration, and big data analytics through a single user interface (UI).
Users can ingest data from almost 100 native connectors by building ETL/ELT processes in a code-free environment. Users also benefit from integrated artificial intelligence (AI) and business intelligence tools, including Azure Machine Learning, Azure Cognitive Services, and Power BI. Intelligence tools can easily be applied across diverse data sets, including those in Dynamics 365, Office 365, and SaaS products.
Users can analyze data using provisioned or serverless on-demand resources. And from T-SQL and Python to Scala and .NET, you can use various languages in Azure Synapse Analytics.

Microsoft’s cloud data warehousing service boasts many customers, including Walgreens. The retail and wholesale pharmacy giant has migrated its inventory management data into Azure Synapse. Instead of on-premise data warehouses, the company is now using the cloud to enable its supply chain analysts to query data and create visualizations using tools such as Microsoft Power BI.
An intuitive drag-and-drop interface makes working with data easy. Costs went down as well. Anne Cruz, an IT manager for supply chain and merchandising at Walgreens, says that “Azure was a third of the cost compared to setting up a new data warehouse appliance on-prem.” And instead of waiting until 1 p.m. to get a previous day’s data report, users have information ready by 9 a.m. every weekday.
Factors to consider when selecting a cloud data warehouse
Major cloud data warehouses share some similarities but also have major differences. Deciding on which warehousing service to use is never an easy task. Consider the following factors when analyzing platforms to use to ensure your team is set for success.
Use cases
A company’s unique circumstances and the use case are critical factors for evaluating data warehousing providers. For instance, businesses that work with JSON may prefer Snowflake as it offers native support for this format. And smaller organizations without a dedicated data administrator might avoid Redshift as it requires regular monitoring and configuration. Services with a plug-and-play setup may be a better fit in this case.
Support for real time workloads
Many companies need to analyze data as soon as it’s generated. For example, some companies may need to detect fraud or security issues in real time, while others may need to process large volumes of streaming IoT data for anomaly detection. In these cases, it’s important to evaluate how different cloud data warehouses handle the ingestion of streaming data.
BigQuery offers a streaming API that users can call with a few lines of code. Azure offers several options for real-time data ingestion, including the built-in Apache Spark streaming functionality. Snowflake offers Snowpipe as an add-on to enable real-time ingestion, while RedShift requires the use of Kinesis Firehose for streaming data ingestion. A real-time data integration solution like Striim provides scalable, enterprise-grade streaming data ingestion for all four of these data warehouses.
Security
Each cloud data warehouse provider takes security seriously. But there are technical differences that users should be aware of when deciding on which vendors to use. For instance, encryption is handled differently: BigQuery encrypts data in transit and at rest by default, while this feature needs to be explicitly enabled in Redshift.
Billing
Vendors calculate costs in different ways. Companies need to know how much data they expect to integrate, store, and analyze each month to estimate costs. Based on these inputs, IT teams can then choose a cloud data warehouse vendor with the most suitable pricing method.
Redshift offers on-demand pricing that varies according to the type and number of nodes in your cluster. Additional capabilities, such as concurrency scaling and managed storage, are billed separately. BigQuery offers separate on-demand and discounted flat rate pricing for storage and analysis. Additional operations, including streaming inserts, incur additional costs.
Azure Synapse uses a Data Warehouse Unit (DWU), a bundle of technical cost factors, to price compute resources. Users are separately charged for storage. And Snowflake uses credits to charge users based on how many virtual warehouses they use and for how long. Storage is billed separately on a terabyte-per-month basis.
Ecosystem
It’s also important to consider in which ecosystems your existing apps and data reside. For example, businesses whose data is already in Google Cloud could get an additional performance boost by using BigQuery or Snowflake on Google Cloud. Data transfer paths will be better optimized since they share the same infrastructure. And data won’t have to move across the public Internet.
Data types
Businesses work with structured, semi-structured, and unstructured data. Most data warehouses usually support the first two data types. Depending on their needs, IT teams should ensure that the vendor they opt for offers the best infrastructure for storing and querying relevant types of data.
Scaling
Another factor to consider when choosing a cloud data warehouse vendor is how the service scales for storage and performance. Redshift requires users to manually add more nodes to ramp up storage and computing power resources. But Snowflake has an auto-scale function that dynamically adds or removes nodes.
Maintenance
Depending on company size and data needs, day-to-day management of data warehouses can be mostly automated or done manually. Small teams may prefer self-optimizing offered by BigQuery or Snowflake. But maintaining data warehouses manually offers more flexibility and greater control, allowing teams to better optimize their data assets. This level of control is offered by Redshift and several other vendors.
Up your data game
From Redshift and BigQuery to Azure and Snowflake, teams can use a variety of cloud data warehouses. But finding the service that best fits company needs is a challenging task. Teams have to consider various parameters, technical specs, and pricing models to make the final decision.
These efforts will eventually pay off. Cloud data warehouses enable product, marketing, sales, and many other departments to up their data game and discover vital insights. And less guesswork and more data-driven evidence will pave the way toward achieving and maintaining a competitive edge.
Schedule a demo and we’ll give you a personalized walkthrough or try Striim at production-scale for free! Small data volumes or hoping to get hands on quickly? At Striim we also offer a free developer version.


