Companies need to analyze large volumes of datasets, leading to an increase in data producers and consumers within their IT infrastructures. These companies collect data from production applications and B2B SaaS tools (e.g., Mailchimp). This data makes its way into a data repository, like a data warehouse (e.g., Redshift), and is shown to users via a dashboard for decision-making.
This entire data ecosystem can be wobbly at times due to a number of assumptions. The dashboard users may assume that data is being transformed the same way as when the service was initially launched. Similarly, an engineer might change something in the schema of the source system. Although it might not affect production, it might break something in other cases.
Data contracts tackle this uncertainty and end assumptions by creating a formal agreement. This agreement contains a schema that describes and documents data, which determines who can expose data from your service, who can consume your data, and how you can manage your data.
What are data contracts?
A data contract is a formal agreement between the users of a source system and the data engineering team that is extracting data for a data pipeline. This data is loaded into a data repository — such as a data warehouse — where it can be transformed for end users.
As per James Densmore in Data Pipelines Pocket Reference, the contract must include a number of things, such as:
- What data are you extracting?
- What method are you using to extract data (e.g., change data capture)?
- At what frequency are you ingesting data?
- Who are the points of contact for the source system and ingestion?
You can write a data contract in a text document. However, it’s better to use a configuration file to standardize it. For example, if you are ingesting data from a table in Postgres, your data contract could look like the following in JSON format:
“{
ingestion_jobid: "customers_postgres",
source_host: "ABC_host.com",
source_db: "bank",
source_table: "customers",
ingestion_type: "full",
ingestion_frequency_minutes: "15",
source_owner: "developmentteam@ABC.com",
ingestion_owner: "datateam@ABC.com"
};”How to implement data contracts
When your architecture becomes distributed or large enough, it’s increasingly difficult to track changes, and that’s where a data contract brings value to the table.
When your applications access data from each other, it can cause high coupling, i.e., applications are highly interdependent on each other. If you make any changes in the data structure, such as dropping a table from the database, it can affect the applications that are ingesting or using data from it. Therefore, you need data contracts to implement versioning to track and handle these changes.
To ensure your data contracts fulfill their purpose, you must:
- Enforce data contracts at the data producer level. You need someone on the data producer side to manage data contracts. That’s because you don’t know how many target environments can be used to ingest data from your operational systems. Maybe, you first load data into a data warehouse and later go on to load data into a data lake.
- Cover schemas in data contracts. On a technical level, data contracts handle schemas of entities and events. They also prevent changes that are not backward-compatible, such as dropping a column.
- Cover semantics in data contracts. If you alter the underlying meaning of the data being generated, it should break the contract. For instance, if your entity has distance as a numeric field, and you start collecting distance in kilometers instead of miles, this alteration is a breaking change. This means that your contract should include metadata about your schema, which you can use to describe your data and add value constraints for certain fields (e.g., temperature).
- Ensure data contracts don’t affect iteration speed for software developers. Provide developers with familiar tools to define and implement data contracts and add them to your CI/CD pipeline. Implementing data contracts can minimize tech debt, which can positively impact iteration speed.
In their recent article, Chad Sanderson and Adrian Kreuziger shared an example of a CDC-based implementation of data contracts. According to them, a data contract implementation consists of the following components, as depicted below:
- Defining data contracts as code using open-source projects (e.g. Apache Avro) to serialize and deserialize structured data.
- Data contract enforcement using integration tests to verify that the data contract is correctly implemented, and ensuring schema compatibility so that changes in the producers won’t break downstream consumers. In their example, they use Docker compose to spin up a test instance of their database, a CDC pipeline (using Debezium), Kafka, and the Confluent Schema Registry.
- Data contract fulfillment using stream processing jobs (using KSQL, for example) to process CDC events and output a schema that matches the previously-defined data contract.
- Data contract monitoring to catch changes in the semantics of your data.
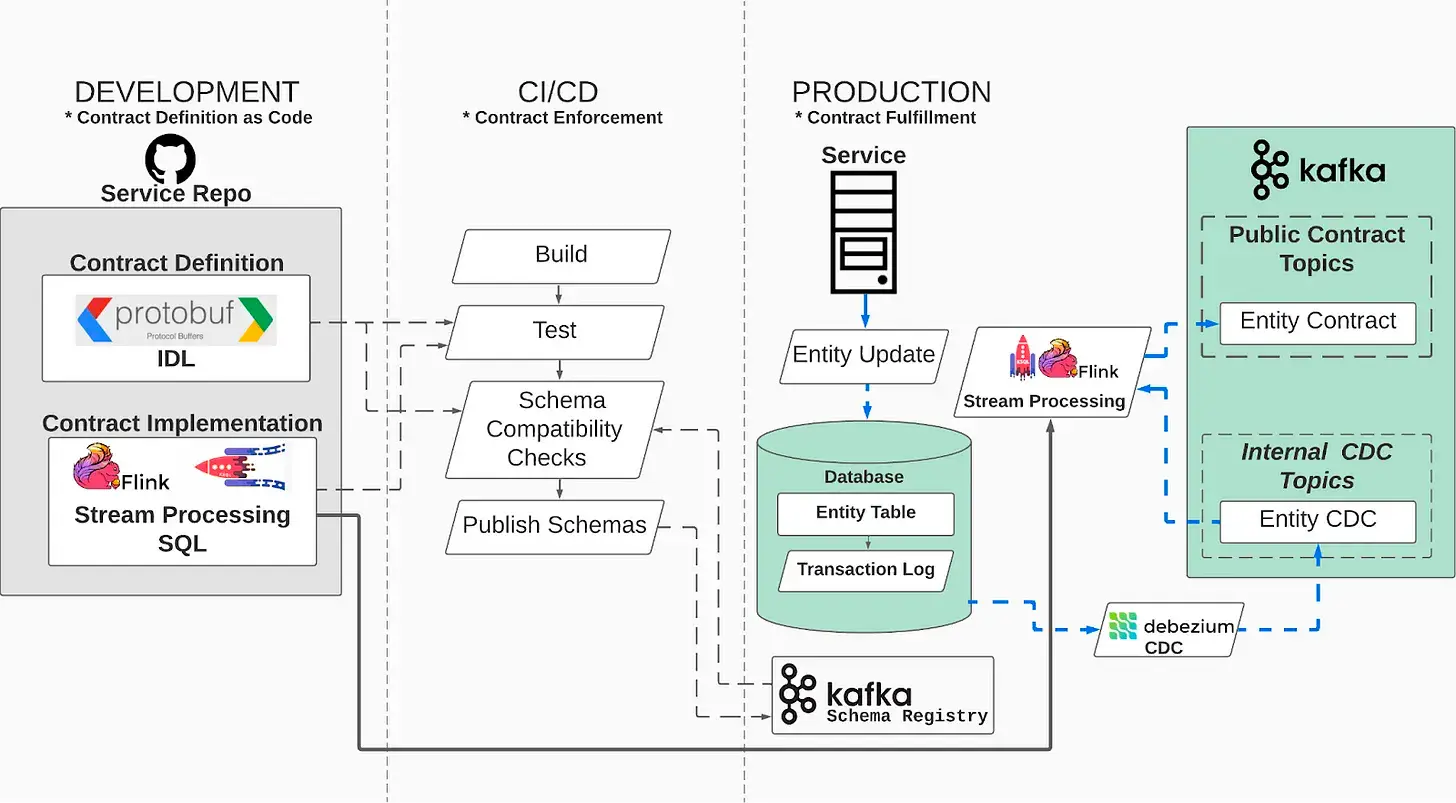
Data contract use cases
Data contracts can be useful in different stages, such as production and development, by acting as a validation tool, as well as supporting your data assets like data catalogs to improve data quality.
Assess how data behaves on the fly
During production, you can use data contracts as a data validation tool to see how data needs to behave in real time. For example, let’s say your application is collecting data for equipment in a manufacturing plant. Your data contract says that the pressure for your equipment should not exceed the specified limit. You can monitor the data in the table and send out a warning if the pressure is getting too high.
Avoid breaking changes
During software development, you can use data contracts to avoid breaking changes that can cause any of your components to fail since data contracts can validate the latest version of data.
Improve discoverability and data understanding
Like data contracts, data catalogs accumulate and show various types of information about data assets. However, data catalogs only define the data, whereas data contracts define the data and specify how your data should look. Moreover, data catalogs are made for humans, whereas data contracts are made for computers. Data contracts can be used with data catalogs by acting as a reliable source of information for the latter to help people discover and understand data through additional context (e.g., tags).
Striim helps you manage breaking changes
Striim Cloud enables you to launch fully-managed streaming Change Data Capture pipelines, greatly simplifying and streamlining data contract implementation and management. With Striim, you can easily define, enforce, fulfil, and monitor your data contracts, without having to wrangle with various open-source tools.
For example, using Striim, you can set parameters for Schema Evolution based on internal data contracts. This allows you to pass schema changes to data consumers on an independent table-specific basis. If your data contract is broken, you can use Striim to automate sending alerts on Slack.. Consider the workflow in this following diagram:
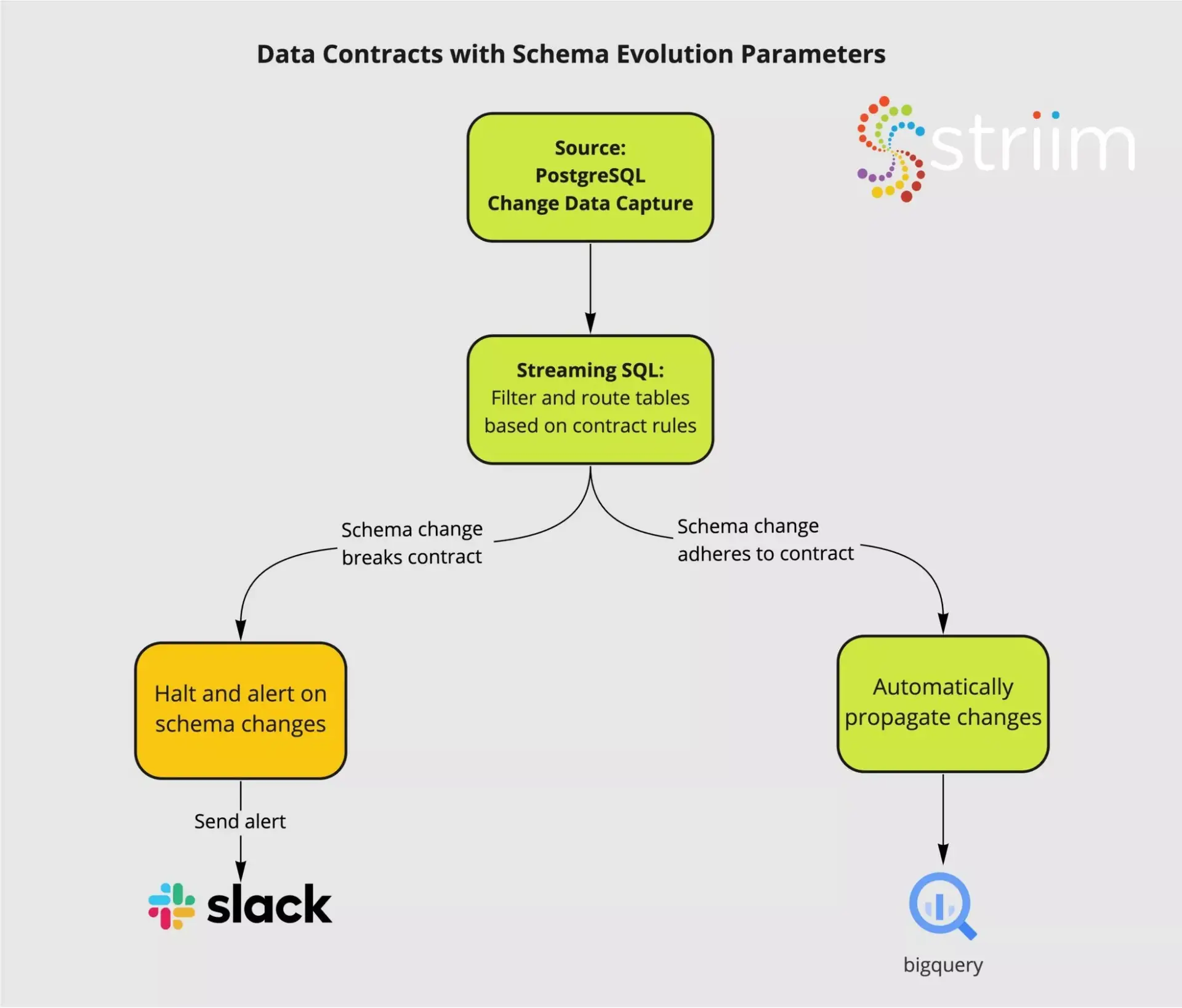
You can use Striim to move data from a database (PostgreSQL) to a data warehouse (BigQuery). Striim is using Streaming SQL to filter tables in your PostgreSQL based on data contracts. If a schema change breaks your contract, Striim will stop the application and send you an alert through Slack, allowing your engineers to stop the changes in your source schema. If the schema change is in line with your contract, Striim will automatically propagate all the changes in your BigQuery.
Learn more about how Striim helps you manage data contracts here.


