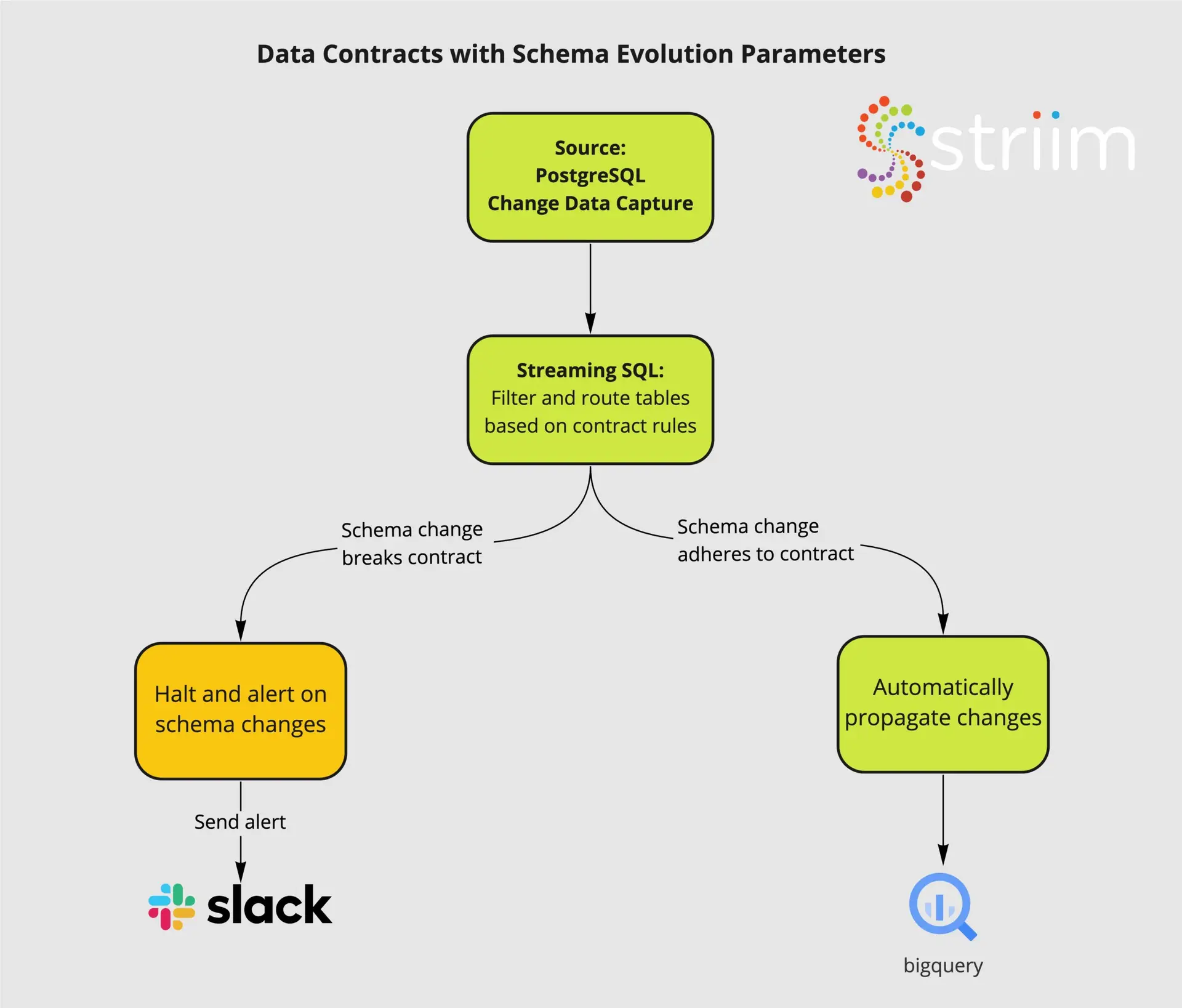
Data Contracts
- Capture raw changes from your database with low impact CDC
- Set parameters for Schema Evolution based on internal data contracts
- Propagate compliant schema changes to consumers on an independent, table specific basis
- Alert directly to Slack and other tools when schema contracts are broken
Schematic Architecture to support Data Mesh Pattern
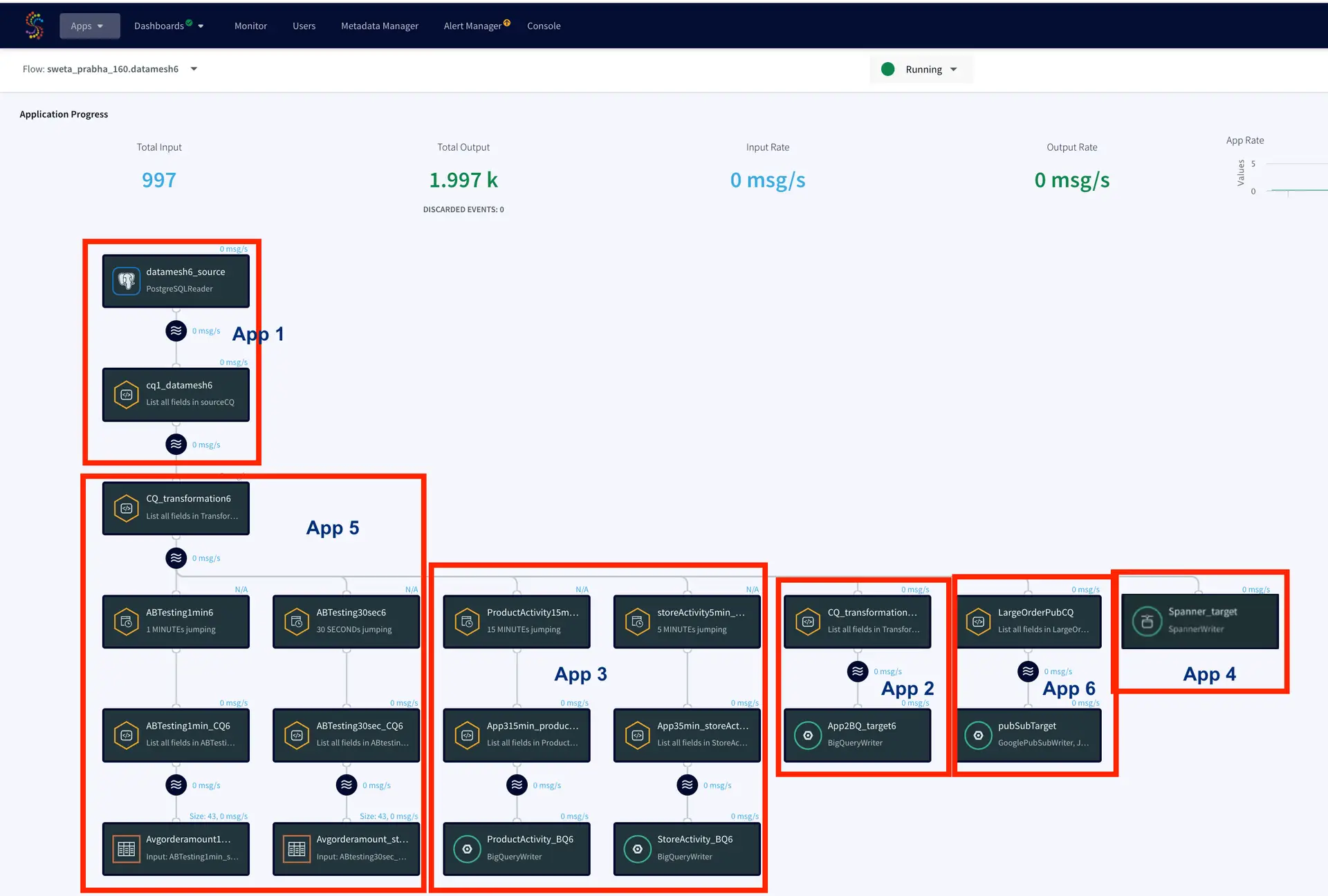
The data mesh shown in the next sections has six apps that is fed data from the same source through kafka persisted stream
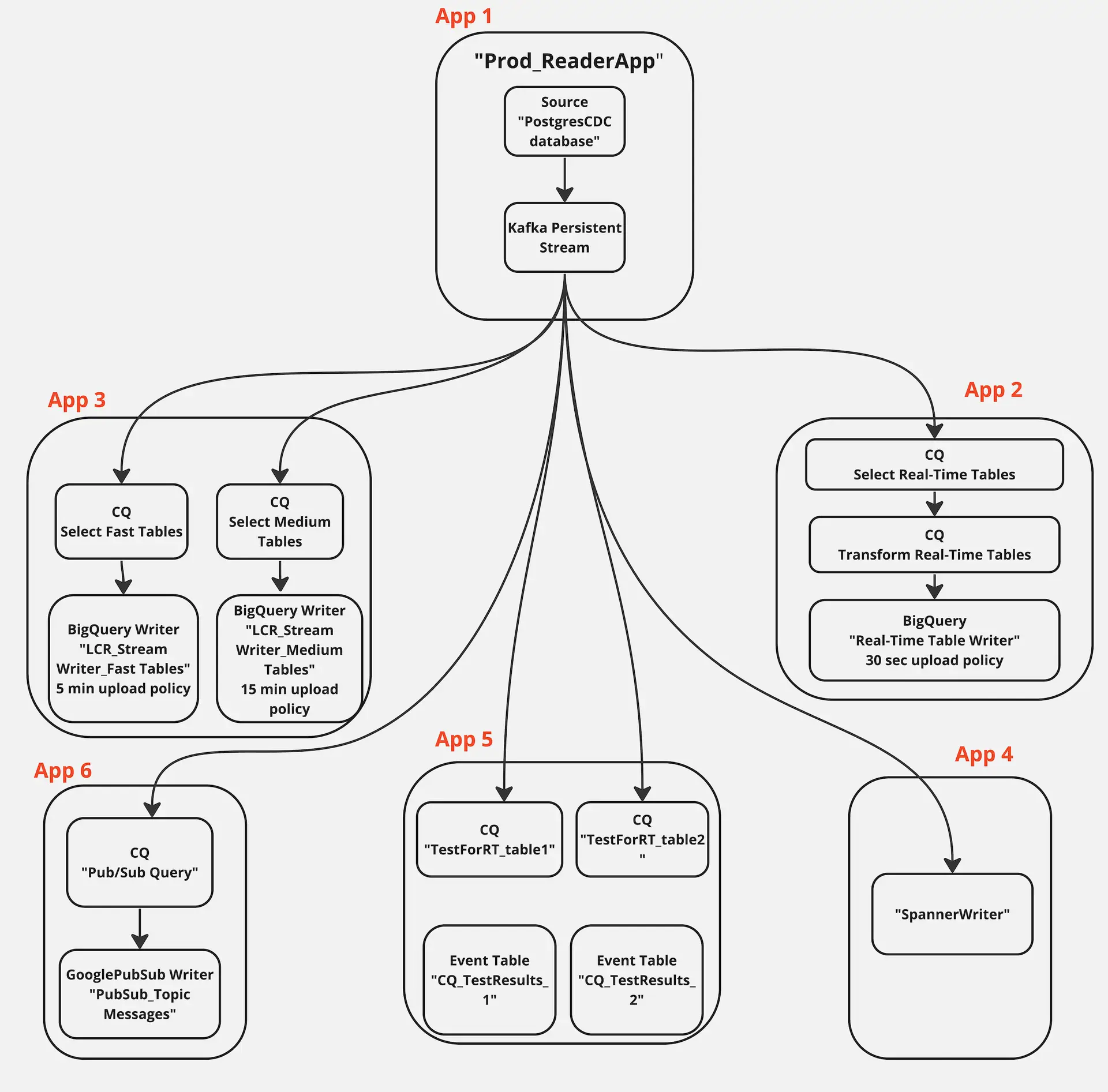
App1: Production Database Reader
This application reads LCR data from a Postgres database and streams into a kafka persisted stream
App2: Real-Time BigQuery Writer
This application transforms data in-flight and writes to a BigQuery data warehouse with 30 secs SLA. The team needs the real-time transformed data for inventory planning.
App3: Near Real-Time BigQuery Writer
This application reads fast table with 5 min SLA and medium/near real-time tables with 15 min SLA and write into BigQuery tables with the respective upload policy
App4: Cloud Database Replication
This application replicate the incoming LCR data into a Google Spanner Database in real time
App5: A/B Testing Query Logic
This application compares data from two different version of CQ to find the best data that can be ingested to a model that forecasts average order amount
App6: Pub/Sub
This application records all the order values larger than $500 and writes it to an existing topic in Google cloud Pub/Sub
Core Striim Components
PostgreSQL CDC: PostgreSQL Reader uses the wal2json plugin to read PostgreSQL change data. 1.x releases of wal2jon can not read transactions larger than 1 GB.
Stream: A stream passes one component’s output to one or more other components. For example, a simple flow that only writes to a file might have this sequence
Continuous Query : Striim Continuous queries are are continually running SQL queries that act on real-time data and may be used to filter, aggregate, join, enrich, and transform events.
Window: A window bounds real-time data by time, event count or both. A window is required for an application to aggregate or perform calculations on data, populate the dashboard, or send alerts when conditions deviate from normal parameters.
Event Table: An event table is similar to a cache, except it is populated by an input stream instead of by an external file or database. CQs can both INSERT INTO and SELECT FROM an event table.
BigQueryWriter: Striim’s BigQueryWriter writes the data from various supported sources into Google’s BigQuery data warehouse to support real time data warehousing and reporting.
Google Pub/Sub Writer: Google Pub/Sub Writer writes to an existing topic in Google Cloud Pub/Sub.
Spanner Writer: Spanner Writer writes to one or more tables in Google Cloud Spanner.
Launch Striim Cloud on Google Cloud
The first step is to launch Striim Cloud on Google Cloud. Striim Cloud is a fully managed service that runs on Google Cloud and can be procured through the Google Cloud Marketplace with tiered pricing. Follow this link to leverage Striim’s free trial for creating your own data-mesh. You can find the full TQL file (pipeline code) of this app in our github repo.
App 1: Production Database Reader
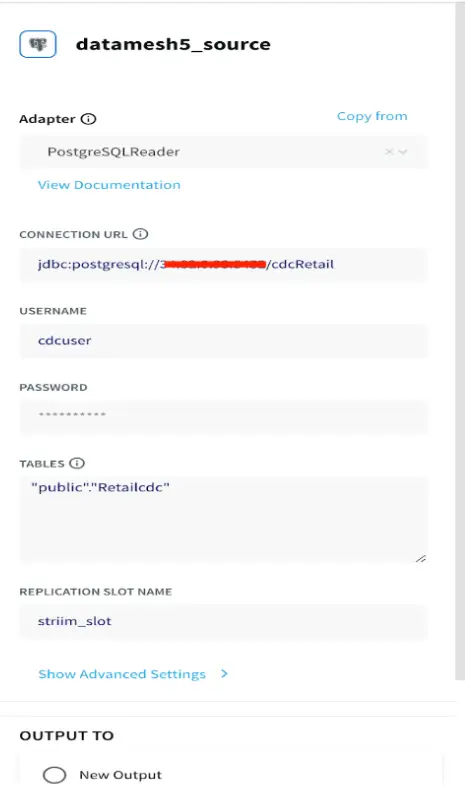
The first app reads the logical change streams from the production database into a ‘persistent stream’ that persists for 7 days. In this use case real-time Retail data is stored and is streamed from a Postgres database. The data consists real-time data of store id, skus and order details at different geographical locations.
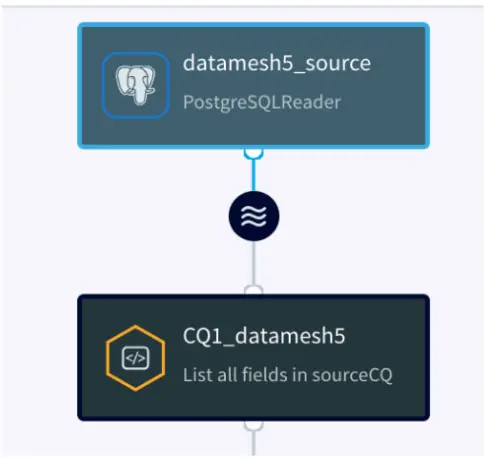
Source Reader
Please follow this recipe to learn about how to set up a replication slot and user for a Postgres database that reads Change Data Capture in real-time.
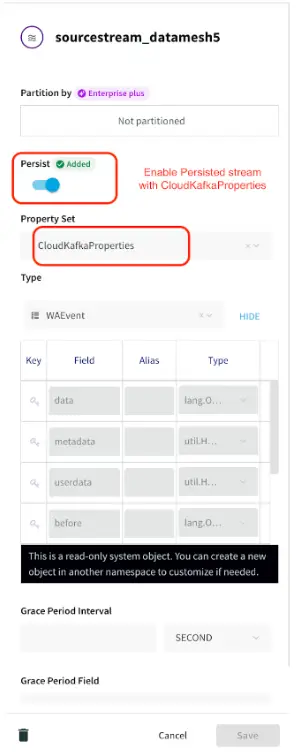
Persistent Stream:
Striim natively integrates Apache Kafka, a high throughput, low-latency, massively scalable message broker. Using this feature developers can perform multiple experiments with historical data by writing new queries against a persisted stream. For a detailed description of this feature follow this link.
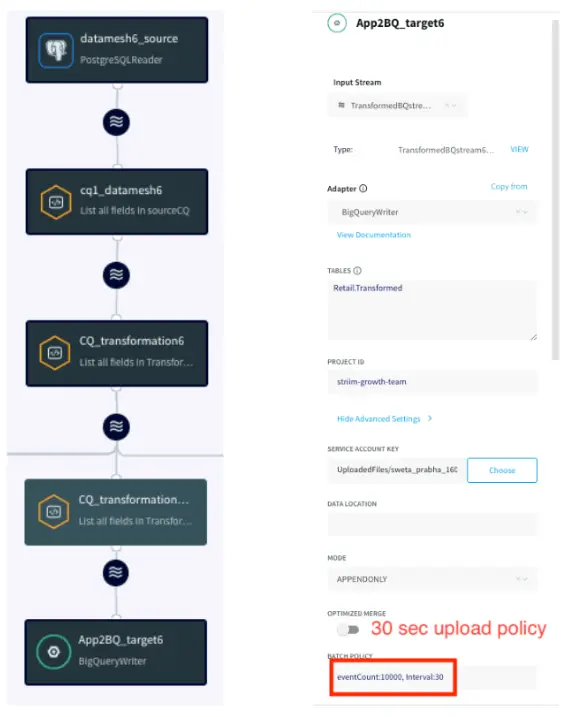
App 2: Real Time BigQuery Writer
In this application, the team needs inventory updates from each state in real time. The team takes care of the transportation of various different skus and does the inventory planning for each state to meet the forecasted demand. The application has a strict policy where real-time data must be available in BigQuery within 30 seconds. A Continuous Query transforms the data in-flight for analytics-ready operations rather than transforming in the warehouse.
The data is read from Kafka persisted stream, transformed in-flight and streamed to BigQuery target tables. To know more about how to set up a BigQuery target for Striim application, please follow this recipe.
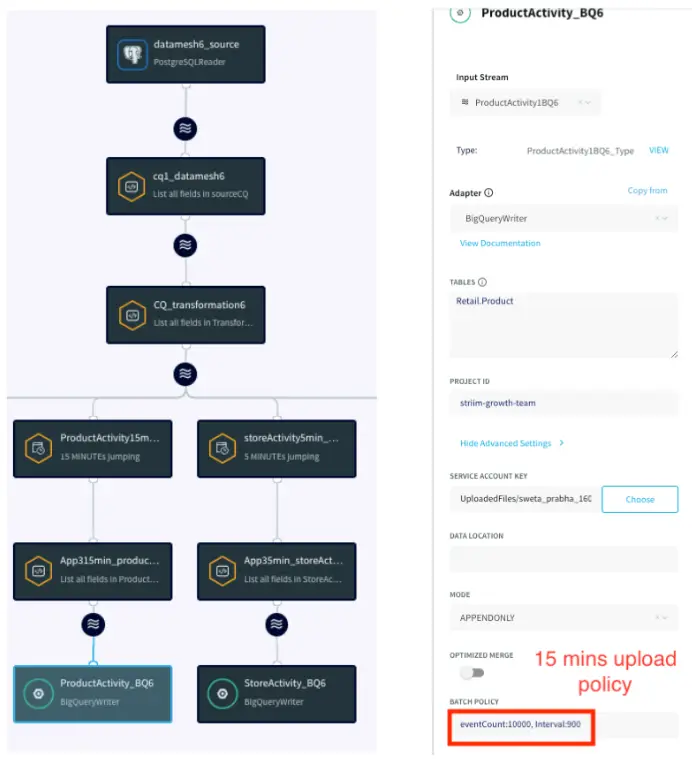
App 3: Near Real-Time BigQuery Writer
In app 3 fast tables are selected from LCR (Logical Change Record) streams with 5 minute upload policy and medium/near-real time SLA tables are selected and written to BigQuery within 15 minutes upload policy. In this use case the Store activity data such as store id, order amount in each store and number of orders in each store are updated within 5 minutes whereas Product Activity such as number of orders for each sku are updated every 15 minutes on BigQuery table. This helps the relevant team analyze the store sales and product status that in turn is used for inventory and transportation planning.
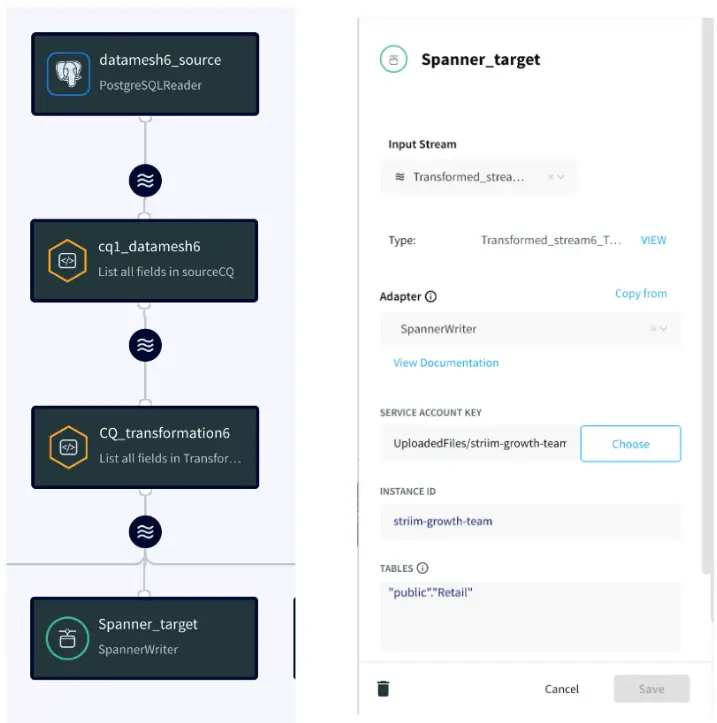
App 4: Cloud Database Replication
For this app, the team needs real-time business data to be replicated to Spanner on GCP. The CDC data is read from Kafka persisted stream and replicated to Google Cloud Spanner.
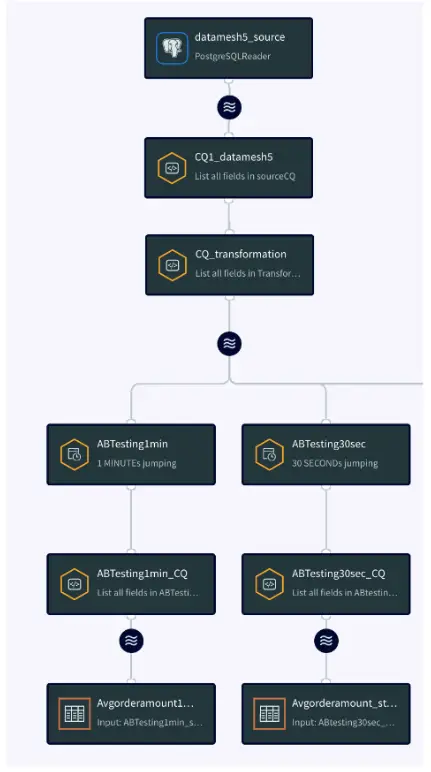
App 5: A/B Testing CQ Logic
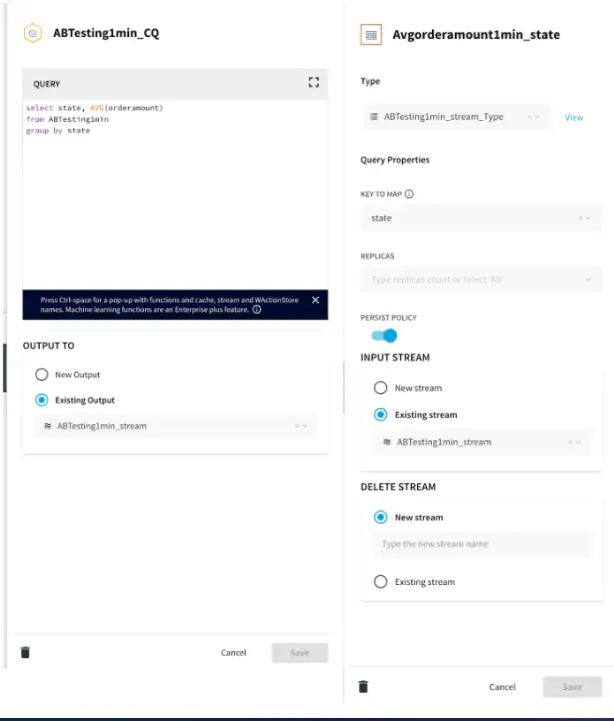
In this app, the team performs an experiment on stream with two different SLAs. The idea is to compare the average order amount of each state obtained from a 30 seconds window stream and 1 minute window stream for forecasting average order amount. The forecasting model is applied on each data stream to find out the best SLA for forecasting average order amount.The updated data is stored in an event table which can be read by the analytics team for A/B testing.
Continuous Query and Event Table
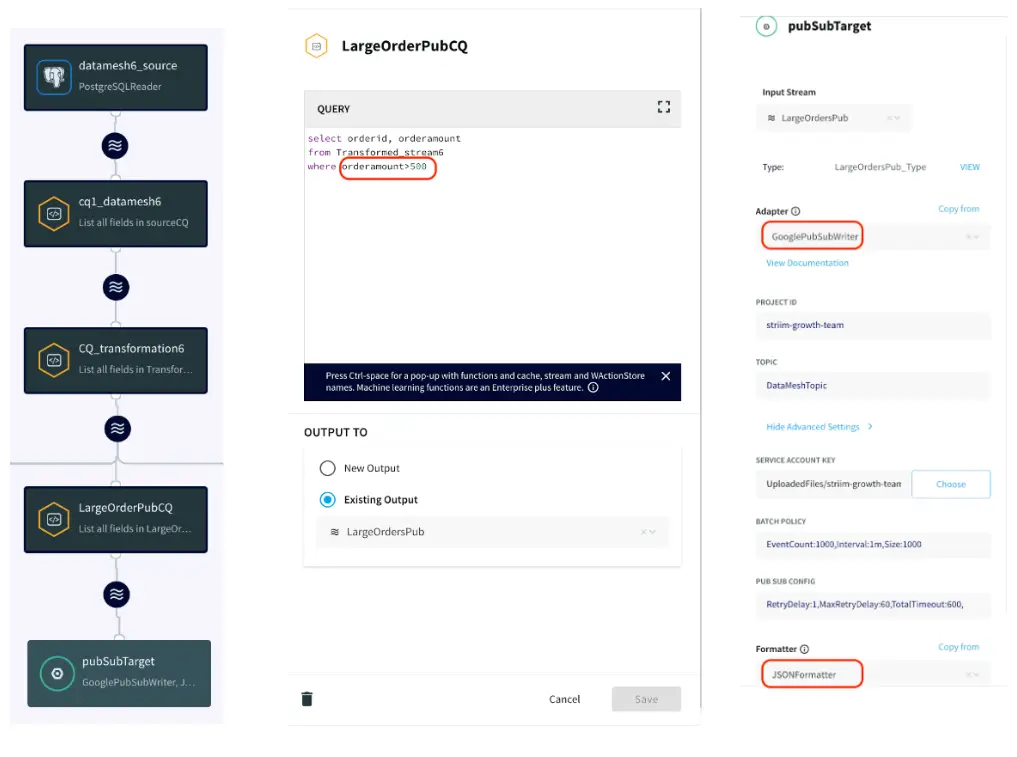
App 6: Google Pub/Sub Messaging App
In this app, the user wants to get a notification when a high value order is placed. The data is transformed in-flight using Continuous Query and all the orders greater than $500 are streamed into a google pub/sub topic which can be further subscribed by various teams.
Continuous Query and Pub/Sub Target Configuration
The topic is configured in Google Pub/Sub and the subscribers can pull the messages to see each new entry.
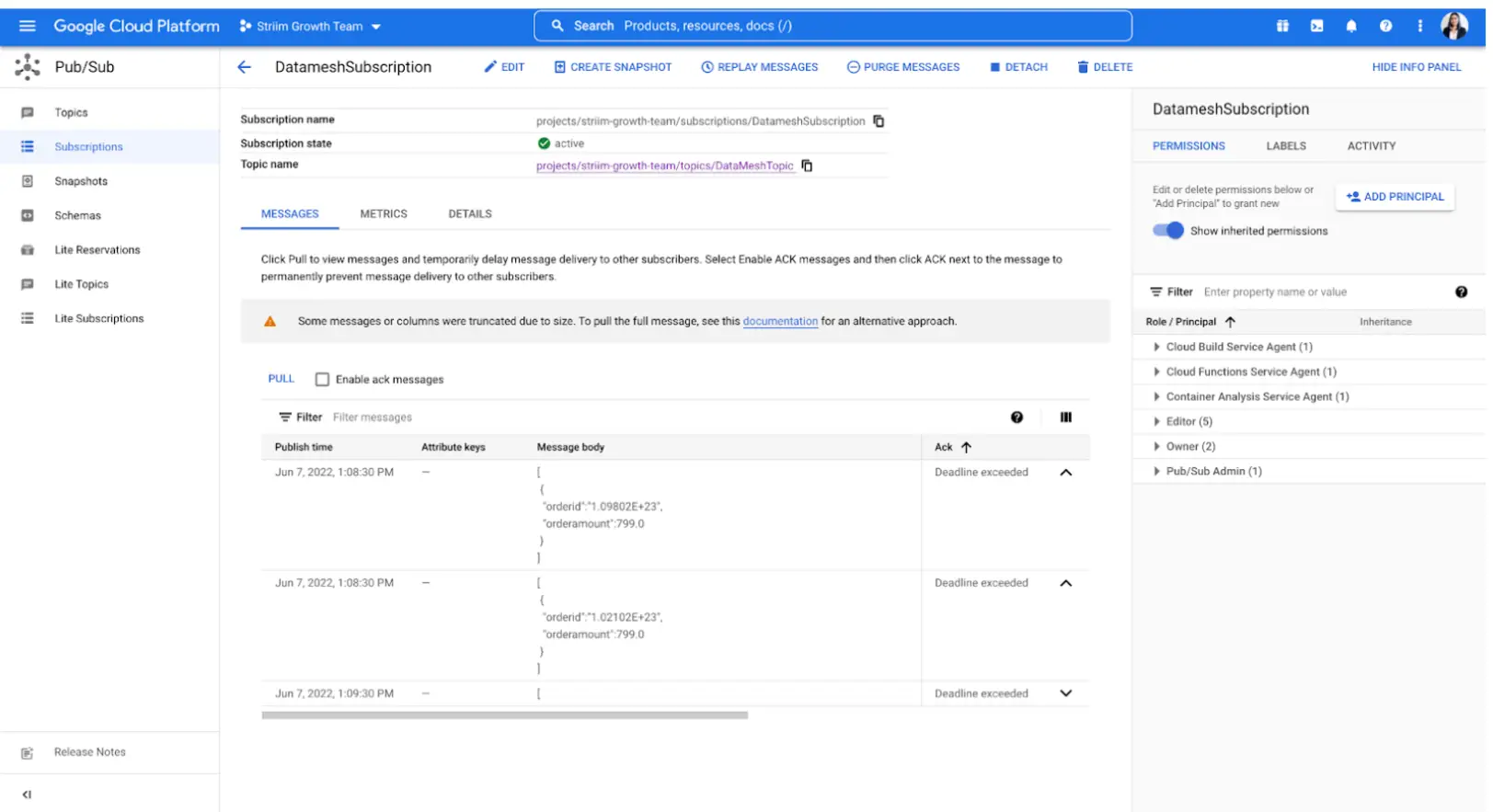
Running the Striim Pipelines
The following image shows the entire data mesh architecture designed using Striim as the streaming tool that replicated data to various targets with SLAs defined for each application.

Striim
Striim’s unified data integration and streaming platform connects clouds, data and applications.
PostgreSQL
PostgreSQL is an open-source relational database management system.

Google BigQuery
BigQuery is a serverless, highly scalable multicloud data warehouse.

Google Cloud Pub/Sub
Google Cloud Pub/Sub is designed to provide reliable, many-to-many, asynchronous messaging between applications.

Google Cloud Spanner
Spanner is a distributed, globally scalable SQL database service