










In this Whiteboard Wednesday video, Steve Wilkes, founder and CTO of Striim, takes a look at Streaming Data Integration – what it is, what it is used for, and most importantly, what is needed set it up and manage it. Read on, or watch the 10-minute video:
Like all enterprises, you have a lot of data sources that generate data – databases, machine logs, or other files that are being produced in your systems. You may also have messaging systems sensors or IoT sensors generating data. This data, generated all of the time, may not be in the format you need it or where you need it. This limits your ability to get value from it or make decision using it.
In terms of moving it somewhere else, maybe you want to put it into cloud storage or other types of storage. Maybe you want to put it into different databases or different data warehouses. Maybe want to put it onto messaging systems to build applications for analytics and reporting that will enable analysts, data scientists, decision makers, and your customers can get value out of it. Streaming data integration is about being able to collect data in real time from the systems that are generating it, and moving it to where it needs to be to get value out of it.
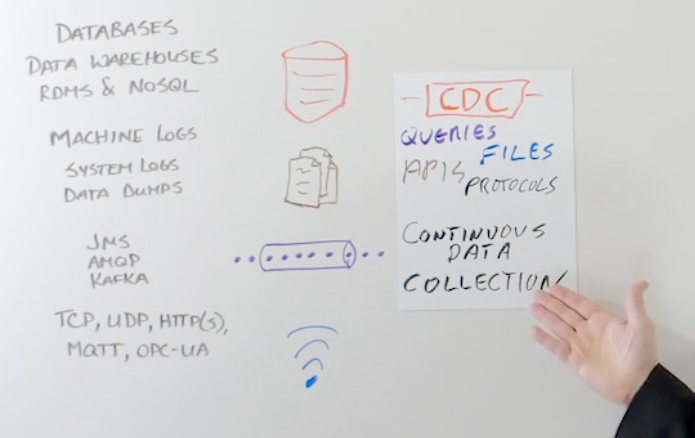
Data Collection
Continuous data collection means being able to get the data in real time. Each type of data source requires a different way of collecting the data. Databases are quite often associated with records of what has happened in the past. Running queries against a database can provide bulk responses of historical data. In order capture real time data – that is, the data as it’s being generated – you need to use a technology called change data capture or CDC.
CDC will allow you to collect the inserts, updates and deletes that are happening in the database in real time as they’re being generated. Similarly, you need specific technologies to get the data you want from other sources of data such as files or messaging systems. In the case of files, you may need to be able to tail the file, read at the end of the file, or maybe collect multiple files across multiple systems in parallel. Once you’ve got that data, you need to be able deliver it to the target systems.
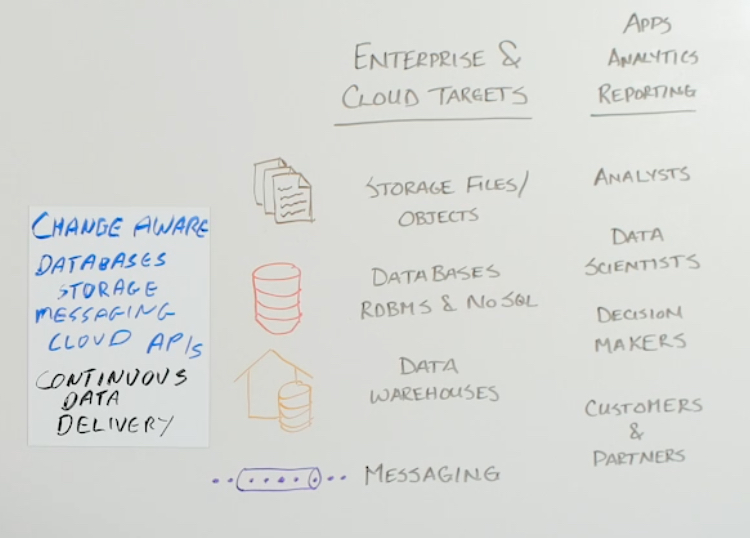
Data Delivery
Data delivery depends on the type of target system. If you are using database change data capture on the source side, the delivery process also needs to be change aware so an insert or an update or a delete is being managed correctly in the target system. For example, if you are synchronizing an on-premise database with a cloud database, then you need to initially load the data, but you also need to apply change to it in order to keep it synchronized. The delivery process needs to understand that, instead of just inserting all the events into the database, it treats an insert as an insert, an update as an update, and delete as a delete. This needs to be applied in a heterogeneous fashion.
You also need to be able to work with lots of different APIs. Again, just as you need to be able to work with databases, with storage, and with messaging, you also need to be able to support different cloud systems. The security mechanisms used by the different cloud vendors are all different, so you need to be able to manage that.
Data Movement
Streaming data integration needs to continuously to move the data that’s being collected into the appropriate target. It may be required to collect data from multiple sources, combine them together and push them out to a single target, or take data from a single source and move it and deliver it continuously to multiple targets.
Data movement has to be smart. It has to be able to move data between processes, between nodes, in a clustered environment. It has to be able to move data from on-premise to cloud, or from cloud to on-premise, or across different networks and even across different clouds. Also, this data movement has to be at really high speeds and low latency. You need to be able to deliver the data from one place to another really quickly.
In a lot of use cases, you’re not just dealing with the raw data. If you’re doing a database replication, then you can collect change on one side and apply that change exactly as is to the target. But in a lot of cases you want to manipulate the data in some way. The format, structure, or content of the data you collect may not be enough, it may not be correct, or it may not be sufficient for where you want to put it, you may need to do some kind of stream processing.
 Data Processing
Data Processing
Data processing is about being able to take the data that’s on the data stream and manipulate it. You may want to filter it. Maybe everything you collect doesn’t need to be written to everything you deliver to. Maybe only a subset is written to storage; maybe only a subset goes into messaging. You need to be able to filter that data and choose what goes where.
You also need to be able to transform it, to give it the structure that you want, and to apply functions to it in order to make it look like you need.
You also need to worry about security. Maybe you need to mask some of the data, obfuscate it in some way. If you’re doing cloud analytics and you have Personally Identifiable Information (PII) coming from your sources, then it’s probably a good idea to anonymize that data before you put it into the cloud for analytics. Being able to do that as the data streams to a target is really important.
Maybe you need to be able to encrypt the data or combine data together. You can take data from multiple sources and combine it into a single data stream that you then apply into a target. Maybe you need to aggregate or summarize the data before you write it into a data warehouse. Maybe it doesn’t contain enough information by itself. Maybe you need to denormalize it or enrich it before it is delivered somewhere else. For streaming integration platforms, you need to be able to do all of these different types of processing on the data in order to get it in the form that you want before you deliver it.
Data Insights
You also need to be able to get insights on the data, to see how the data’s flowing, whether there are any issues in the data flow, maybe even investigate the data itself if there are any issues. This can be done ad hoc, but from an operational perspective, it’s also important that you get alerts if anything is failing or if there is an unusual volume of data coming from one particular place. There suddenly could be an unusual volume coming from your audit table, or maybe there isn’t sufficient volume and it’s fallen behind what you’d expect for that time of day. Being able to get alerts on the data flows themselves can be really, really important.
 Enterprise-Grade Integration
Enterprise-Grade Integration
You can play about with streaming data integration components in the lab. But if you’re going to put things into production, streaming data integration needs to be enterprise-grade. Everything needs to be able to scale. Typically, you’re talking about large volumes of data being generated continuously for streaming integration. You need to be able to deal with scalability and adding additional scale over time.
You are probably looking at a cluster distributed environment where you can add new nodes into that environment as you need to in order to be able to handle scale. Of course, for mission-critical platforms for mission-critical data flows, it needs to be reliable.
You need to be able to say, if I collect data, if data is generated on this source side, then I have to be able to guarantee that it makes it into my targets. If I am replicating a database that’s on-premise into a data warehouse that is in the cloud, I need to make sure that every single operation makes it from one end to the other, and that I can investigate that and validate that that has actually happened.
For streaming data integration to be enterprise grade and work with mission-critical applications, you need to be able to ensure that it is reliable. At a minimum, there should be at-least-once processing, and that everything that’s generated on the source makes it to the target. In certain cases, you need “exactly once processing.” This means that not only does it make it to the target, but you are guaranteed that even in the cases of failure, it only ever makes it the target once.
Security is important. We’ve talked about data security in terms of being able to mask and encrypt data as it flows. As things are moving across networks, all of that data should be encrypted so that people can’t tap into the network flow. From a security perspective, you need to be able to lock down who has access to what in the system that is doing all of these things. If you’re generating a data stream on-premise and it has personally identifiable information in it, you need to be able to lock down which employees can access that data stream, even through the streaming platform. Being able to do authentication and authorization within the streaming platform itself is also essential.
In summary, streaming data integration is about continually collecting data from enterprise and cloud sources, being able to process that data while it’s moving, delivering it into any target that you want, whether it’s on-premise or cloud, being able to get insights into how it’s moving, and do all of this in a enterprise-grade way that is scalable, reliable, and secure.
To learn more about streaming data integration, please visit our Real-time Data Integration solution page, schedule a demo with a Striim expert, or download the Striim platform to get started.




