










Continuing on from Part 1 of this two-part blog series on operationalizing machine learning through streaming integration, I will now discuss how you can use streaming data for adaptive machine learning model serving.
3.2. Adaptive model serving
In a real world operational system, data evolution is very common. For example, a firewall re-configuration or a new service launch can easily change the behavior of network flows. Therefore, an offline trained and fine-tuned model may not keep serving well in an operational system. A seemingly simple method is to repeatedly update the model with a given time interval. However, it is non-trivial to determine the model update frequency for an arbitrary operational system. A more effective way is to update the model on-demand via adaptive machine learning model serving, i.e., retrain the model when there is a data pattern change detected. Accordingly, we perform this task by splitting it into two sub-tasks, i.e. detect data pattern change (Fig. 4 a-e), and retrain model (Fig. 4 f-l).
3.2.1 Detect data pattern change
When there is a pattern change in the network data stream, the offline-trained anomaly detection model will no longer fit the data, resulting in a sudden increase in the number of detected anomalies. To detect such a change of the time series of network anomalies, we perform the following steps:
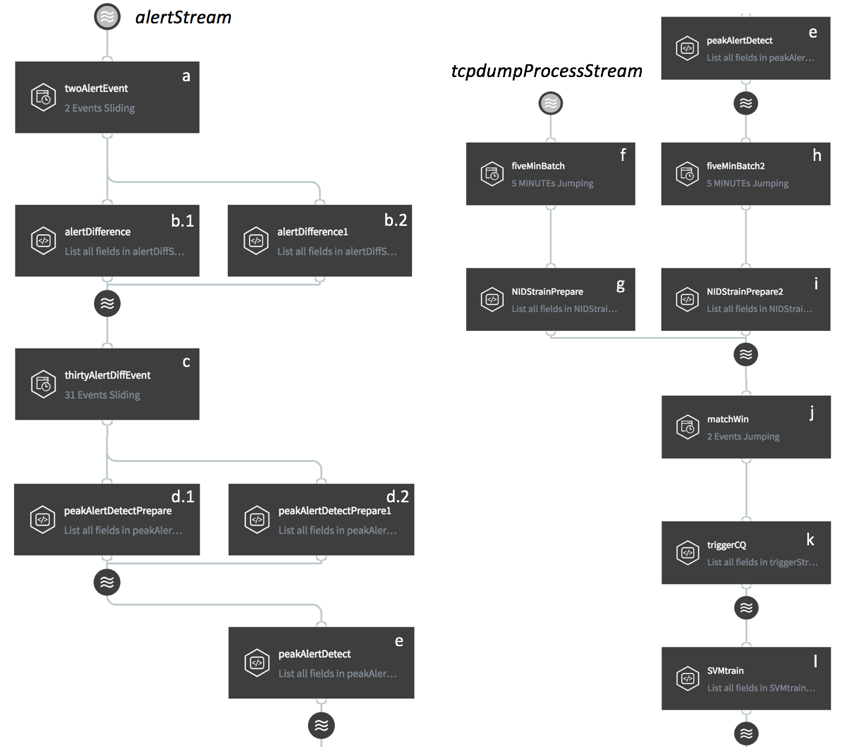
- Difference time series (Fig. 4-a, b);
We first difference the time series of network anomalies, so that we can eliminate the trend factor and format the problem as a time series peak detection problem. Specifically, we leverage an event bounded sliding window to keep two events (Fig. 4 a), and then deduct the numerical values of the first event from the second event within a CQ (Fig. 4 b.1). Since the initial output of the 2-event sliding window only bounds one event, we use an additional CQ (Fig. 4 b.2) to create the first value of the differenced time series.
- Detect time series peaks (Fig. 4- c, d, e);
We use z-score as the peak detection metric, i.e., if the z-score of the current event is larger than a threshold, we identify it as a peak. In particular, we constrain peak detection on the most recent events by utilize a 31-event sliding window (Fig. 4 c) to guarantee the algorithm robustness. If the z-score of the 31stevent is larger than 5 (5 times of standard deviation from the mean of the first 30 events), we report this event as a peak (Fig. 4 e). Similar to Fig. 4 b.2, Fig. 4 d.2 is used to prepare the first 30 inputs for the peak detection algorithm.
3.2.2 Retrain model
In order to prepare for adaptive machine learning model serving and retraining of the model, we utilize a jumping window (Fig. 4 f) to aggregate the new training data, i.e., pre-processed network data flows. In parallel, we utilize a second jumping window (Fig. 4 h) with the same size to aggregate the data pattern change signals. Then, we utilize two separate CQs (Fig. 4 g, i) to query aggregated training data and aggregated change signals respectively and insert into the same stream. Furthermore, we apply a two-event jumping window (Fig. 4 j) on this stream in order to correlate the two parallel processes. Since the data pattern change detection process involves more computations than the new training data preparation process, we can set a 30-second timeout to sync them. After we have prepared the new training data, and gathered the information of data pattern change, we can cancel or trigger model retraining accordingly (Fig. 4 k, l). Namely, if there is a data change signal, trigger the retraining, otherwise cancel it. In particular, retraining is done by first writing a java function to perform training process and then wrapping it into a jar, similar to model serving.
3.3 Monitoring and alerting
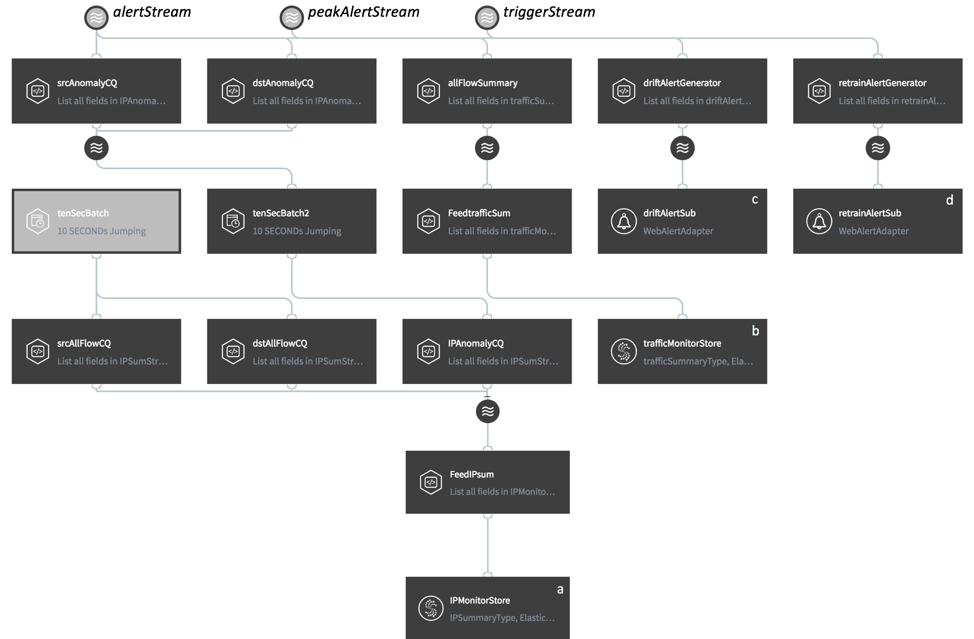
Monitoring and alerting are important for network administrations to intuitively observe what’s happening in the system and make efficient decisions accordingly. Striim supports sophisticated alerting components and visualization tools to conduct real-time monitoring and alerting. This last application is built to 1) monitor traffic (both normal and abnormal) sources and destinations (Fig. 5 a); 2) monitor the number of network flows and anomalies every 10 seconds (Fig. 5 b); 3) alert on data pattern change (Fig. 5 c); 4) alert on retraining (Fig. 5 d). Specifically, a and b are stored in Striim “wactionstores”, which store the results in memory for monitoring purposes. Wactionstores can be further queried in dashboard to visualize data, as shown in Fig. 6.
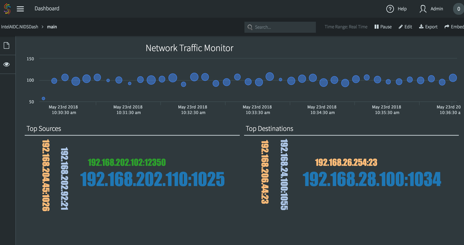
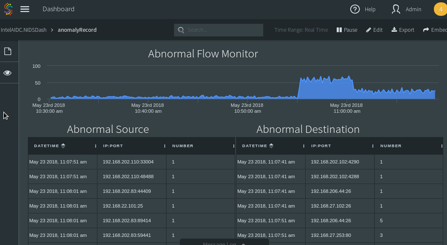
4. Discussion and Key Takeaways
We have introduced Striim and its capabilities in operationalizing machine learning, enabling adaptive machine learning model serving, through a use case of network anomaly detection. Here are some key takeaways of this post.
- Streaming integration paves the way to ML operationalization
- Striim provides reliable and efficient streaming integration solutions and supports fast-track ML operationalization
- Striim filters, enriches, and prepares streaming data
- Striim lands data continuously for adaptive machine learning model training
- Striim supports continuous model serving on data streams
- Striim handles model lifecycles with advanced automation
- Striim visualizes the real-time data and predictions, and alerts on issues
Operationalizing machine learning is a complicated topic. It is non-trivial to utilize existing techniques to accomplish full automation, including automatic A/B testing, automatic model optimization, automatic feature selection, etc. We believe Striim’s streaming integration with intelligence architecture is essential to facilitate a full automation of ML operationalization.
Please feel free to visit our product page to learn more about the features of streaming integration that can support operationalizing machine learning, or download a fully loaded evaluation copy of Striim and see how easy it is to leverage streaming data to update your models.




