Why Matching Is a Math Problem, Not an Approximation Problem
In the previous post, we drew a hard line: data validation means proving two datasets represent the same truth: not approximating it, not sampling it, not eyeballing it. If you accept that definition, a question follows immediately.
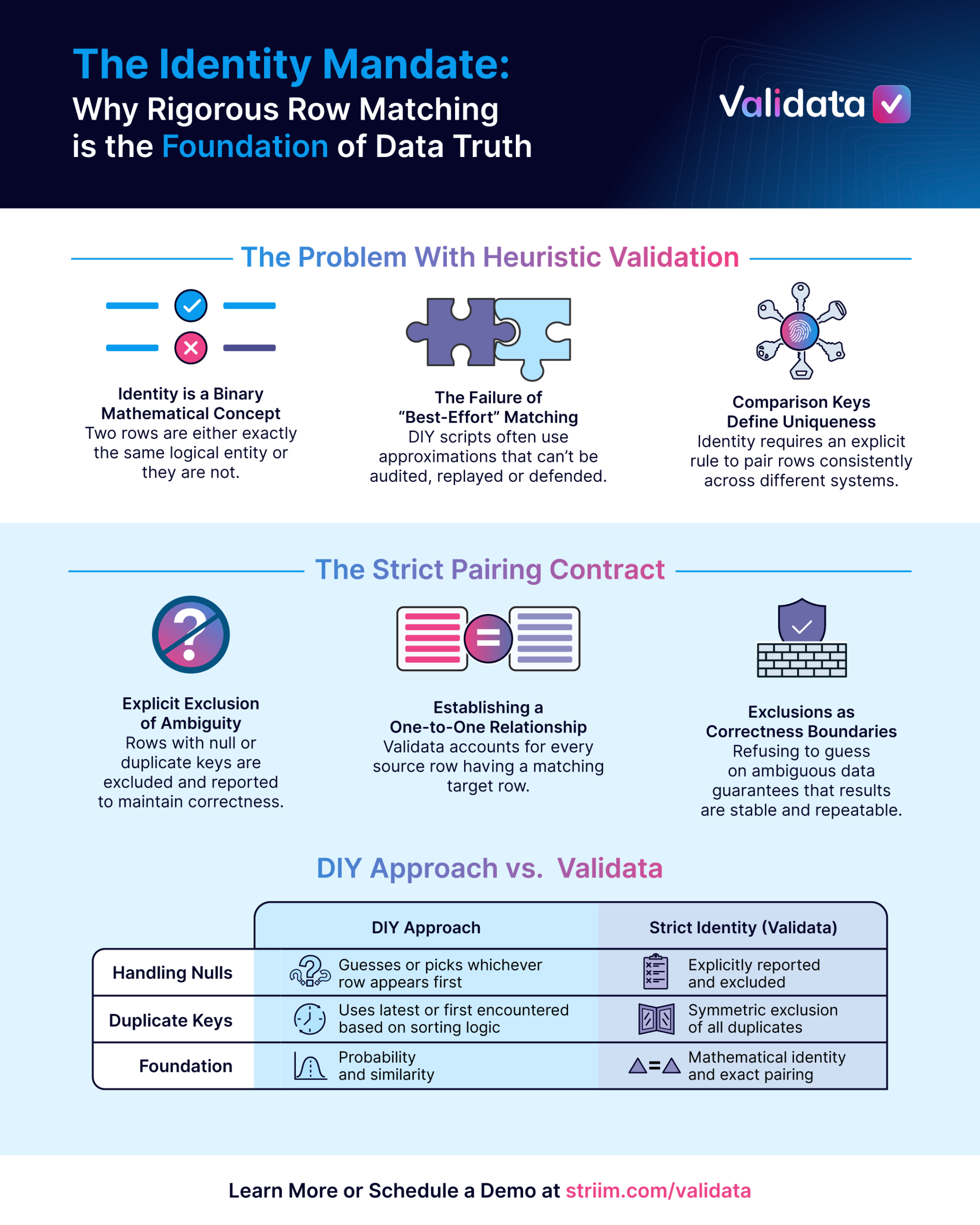
How do you decide which rows are supposed to match? It sounds like plumbing. It isn’t. It’s the most consequential decision in the entire validation pipeline, and it is the place where more DIY scripts, legacy tools, and well-intentioned data quality frameworks quietly collapse. Not with an error. With a wrong answer that looks right.
This post is about why row matching is an identity problem, which is a mathematical one. We discuss what that means for how a validation engine must behave.
The Question Underneath the Question
When you validate two datasets, you’re implicitly claiming that a row in the source and a row in the target represent the same real-world entity. The same customer. The same transaction. The same event.
That claim is either true or it isn’t.
It’s not a matter of probability. It is not a matter of similarity scores, fuzzy keys, or “close enough.” It is about identity. And identity, in the mathematical sense, is binary. Two things are either the same thing or they are not. There is no partial credit, no confidence interval, and no approximation that preserves correctness over time.
Once you accept that framing, the requirements follow with uncomfortable precision:
- Row pairing must be one-to-one. One source row maps to exactly one target row, and vice versa.
- Row pairing must be repeatable. Run the validation at 2 PM or 2 AM, get the same pairs.
- Row pairing must be explainable. You must be able to point at a rule and say: this is why these rows were paired.
- When pairing is ambiguous, the correct response is not to guess. It is to refuse.
This is the mental model. Everything else is a consequence of it.
The Comparison Key isn’t Metadata. It’s a Contract.
You can’t determine identity without an explicit rule that defines it.
In Validata, that rule is called the Comparison Key. And it is worth being precise about what that means, because the word ‘key’ carries a lot of baggage from the relational database world.
A Comparison Key is not a primary key constraint enforced by your database. It is not a hint to the engine about what might be unique. It is the formal declaration of what makes a row uniquely identifiable for the purposes of this validation. It can be a single column or a composite of multiple columns. It does not need to be enforced by the underlying system.
This matters enormously in modern data architecture. If you are validating data in BigQuery, Snowflake, Redshift, or a data lake, you already know: primary key constraints are either unenforced or nonexistent. The engine will not protect you from duplicates. The schema will not tell you what uniquely identifies a row. That responsibility falls entirely on you, the owner of the data..
Validata intelligently automaps the source columns to the target columns. You can review and modify the column mappings, and choose which columns to include in the comparison. Validata only compares the columns that are selected and compares them according to the mapping in the validation configuration. If needed, you must also select the comparison key that specifies the columns that Validata must use to compare the tables.
Why? Because a system that does not know what identity is cannot prove equivalence. If you don’t tell Validata what makes a row unique, Validata can’t pair rows consistently. Comparisons become dependent on the order in which they execute. Results change based on query execution plans. The validation is no longer a proof. It is a random sample dressed up as a firm result.
When Identity Breaks Down: Nulls
Once you define the Comparison Key, the next challenge is what to do when identity is incomplete. Null values in key columns introduce a specific kind of ambiguity. It has no clean resolution. A null is not a value. It is the absence of a value. And critically, two nulls do not share identity. They share uncertainty.
Consider what happens if a validation engine attempts to match rows where the key is null. It immediately faces an unsolvable problem: which null in the source corresponds to which null in the target? There is no answer that does not rely on execution order, the details of your implementation, or a completely arbitrary choice.
You couldn’t really distinguish between signal and noise.
Therefore, Validata excludes rows with null values in any Comparison Key column. This is not a silent drop. These rows are explicitly counted, reported, and surfaced in the run results. Validata does not pretend that identity exists where it does not. It acknowledges the gap and tells you exactly how large the gap is.
For you as a data engineer, architect or AI/ML engineer, there is a very direct message. Null keys in your source or target are themselves an indication of the quality of your data. So Validata surfaces that information correctly and clearly.
When Identity Breaks Down: Duplicates
Duplicate keys introduce a related but different challenge.
When the same Comparison Key value appears more than once on either side, it violates the one-to-one pairing rule. You are now in a one-to-many or many-to-many relationship. Pairing requires a tiebreaker. And any tiebreaker, like the latest timestamp, first row, or alphabetical sort on a non-key column, is just a wild guess.
You can’t audit a wild guess. You can’t replay a guess bounded by a set of clear rules.. Imagine a data incident when someone asks why 3,000 rows were reported as in-sync when they weren’t.
Could you defend that after the fact? You couldn’t! Hence, Validata excludes all rows associated with a duplicate key on either side. The exclusion is symmetrical. That is, if a key appears twice in the source, we exclude both source rows, and the corresponding target row (if it exists).
This feels aggressive until you think about the alternative. If Validata kept one of the duplicate rows by some internal rule, the result would depend on that rule. Change the rule, change the result. That is not validation.
That is a black box that produces numbers. The correct behavior is to exclude the rows. It is the only behavior that preserves the strong evidence: every comparison Validata makes is between rows that have been clearly identified as representing the same entity.
The Pairing Contract
Before any column-level comparison occurs — before Validata checks whether order_total in the source equals order_total in the target, it satisfies a strict pairing contract.
Here’s the sequence:
- You declare the Comparison Key. The validation operator explicitly defines which column or combination of columns establishes row identity.
- We exclude Null key rows. Any row in the source or target where a key column is null is removed from the comparison set and counted in the exclusion report.
- We exclude Duplicate key rows.. Any key value that appears more than once on either side results in all associated rows being excluded from the comparison set, symmetrically.
- What remains is a clean set. Every source row has no more than one matching target row. Every target row has no more than one matching source row. The pairing is clear, stable, deterministic, and explainable.
Only at this point does Validata proceed with the comparison.
Let’s say this contract cannot be satisfied. For example, if you see no comparable rows after exclusions, then Validata does not guess or give you a partial result. We don’t do half-measures. Validata just stops and tells you why.
Why This Matters for Everything Downstream
At this point, I think you can agree that every other capability in a validation engine depends on the foundation we’ve just discussed.
Metrics, such as percentages in-sync, rows out-of-sync, mismatch counts, etc., only mean anything if the rows being counted were correctly paired. A 99.8% in-sync rate on incorrectly paired rows is just noise.
Reconciliation scripts, such as the INSERT, UPDATE, DELETE statements Validata generates to bring the target back in sync, are only safe to run if you have clear-cut identity. If you run a reconciliation script containing an UPDATE statement against an incorrectly paired row, what you get is corrupted data. There is no recovery story for that. Performance optimizations, such as vector-based comparison, parallel execution, incremental validation are meaningless if you have already compromised correctness at the pairing step. You have optimized the wrong thing.
Repeatability is the ability to run a validation at any time and get a consistent result. Repeatability requires that pairing is deterministic. Non-deterministic pairing gets you results that change without any change in the underlying data. That makes debugging impossible. You don’t build trust in your data in that way. The pairing contract is not a feature. It is the load-bearing wall.
Practical Implications for Your Stack
If you’rebuilding or evaluating a validation pipeline, the pairing model has direct operational consequences for you. Declare your keys intentionally. Don’t assume the engine will figure out identity from your schema. Define it explicitly, and define it at the logical level. In other words, what makes a particular row a unique entity, not just what column happens to have mostly-unique values.
You must treat exclusions as signals. Null key rows and duplicate key rows are not validation failures to be minimized. They are signals about the quality of your data. High exclusion rates in a given table tell you something is wrong upstream, and that information is more valuable than a cleaner-looking in-sync percentage.
You should understand what your current tooling or scripts are doing. Most homegrown validation scripts do not have an explicit pairing contract. They might pair rows by position, by sort order, or by a best-guess at what the key is. If you have never checked what happens when your script encounters a duplicate key, now is the time.
You must design your validation for repeatability and auditability from the start. If you can’t trace your validation results back to specific row pairings, how will you defend them in incident reviews? Every validation result that Validata produces can be traced to the exact rows that it compared, the exact key that paired them, and the exact columns where they diverged.
Exact Validation vs. Guess-based Validation
This is the defining split in the landscape of data validation scripts and tools. Most validation tools treat row matching as a best-effort problem. When identity is unclear, they make a choice, quietly, internally and then proceed. The results look reasonable most of the time. The failures surface as silent data corruption, not loud errors.
With exact validation, we treat row matching as a hard requirement. When identity is unclear, Validata refuses to proceed and tells you exactly why. The results are probably correct for the rows that were compared.
And the results are clearly bounded for the rows that were not. Validata is built on the second model. Not because the first model is never useful, but because the first model cannot really prove anything. And if you cannot prove it, you have not validated it: you’ve only estimated it.
What Comes Next
This post established the foundation: we must now acknowledge that row identity is an exact problem, and the Comparison Key defines it. In essence, correctness requires refusing to compare rows whose identity is ambiguous.
In the next post, we’ll go deeper into the validation engine itself. With Validata, you get multiple validation methods such as Vector Validation, Fast Record Validation, Full Record Validation, Interval Validation, and more.
That raises an obvious question: if there are multiple methods, does “correct” mean different things depending on which one you use? The answer is no. And understanding why is the key to understanding how to choose the right method for your specific architecture.


