Real-time data analytics is proving to be the next big wave in Big data and Cloud computing and in a computing context, there’s an increasing demand to derive insights from data just milliseconds after it is available or captured from various sources.
NoSQL databases have become widely adopted by companies over the years due to their versatility in handling vast amounts of structured and unstructured streaming data with the added benefit to scale quickly with large amounts of data at high user loads.
Why MongoDB?
MongoDB has become a prominent powerhouse among NoSQL databases and is widely embraced among many modern data architectures. With its ability to handle evolving data schemas and store data in JSON-like format which allows us to map to native objects supported by most modern programming languages.
MongoDB has the ability to scale both vertically and horizontally which makes it a prime choice when it comes to integrating large amounts of data from diverse sources, delivering data in high-performance applications, and interpreting complex data structures that evolve with the user’s needs ranging from hybrid to multi-cloud applications.
Why Parquet?
Storage matters! I/O costs really hurt and with more multi-cloud distributed compute clusters being adopted, we would need to consider both the disk I/O along with the network I/O. In a Big data use case, these little costs accrue both in terms of compute and storage costs.
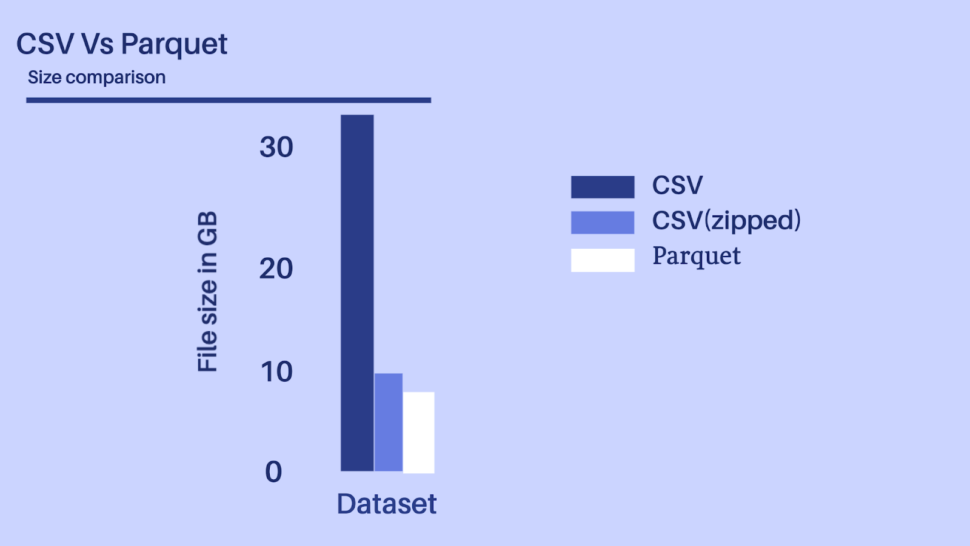
Considering the above-depicted scenario, let’s presume we have a dataset with 100+ fields of different datatypes, it would be unwise to ingest a 30+ GB file even by using a distributed processing system like Spark or Flink.
Parquet data format is more efficient when dealing with large data files and goes hand in hand with Spark which allows it to read directly from a Spark data frame while preserving the schema. At the same time, Parquet can handle complex nested data structures and also supports limited Schema evolution to accommodate changes in data like adding new columns or merging schemas that aren’t compatible.
Is Delta Lake the new Data Lake?
Databricks leverage Delta lake which helps accelerates the velocity at which high-quality data can be stored in the data lake and in parallel, provide teams with leverage to insights from data in a secure and scalable cloud service.
Key highlights among its features include
- Leveraging spark distributed processing power to handle metadata for Petabyte scale tables.
- Act interchangeably as a batch table, streaming source, and data sink.
- Schema change handling that prevents insertion of bad records during ingestion.
- Data versioning allows rollbacks, builds historical audit trails, and facilitates rebuildable machine-learning experiments.
- Optimize upserts and delete operations that allow for complex use cases like change-data-capture (CDC), slowly changing dimension (SCD), streaming upserts, and so on.
Core Striim Components

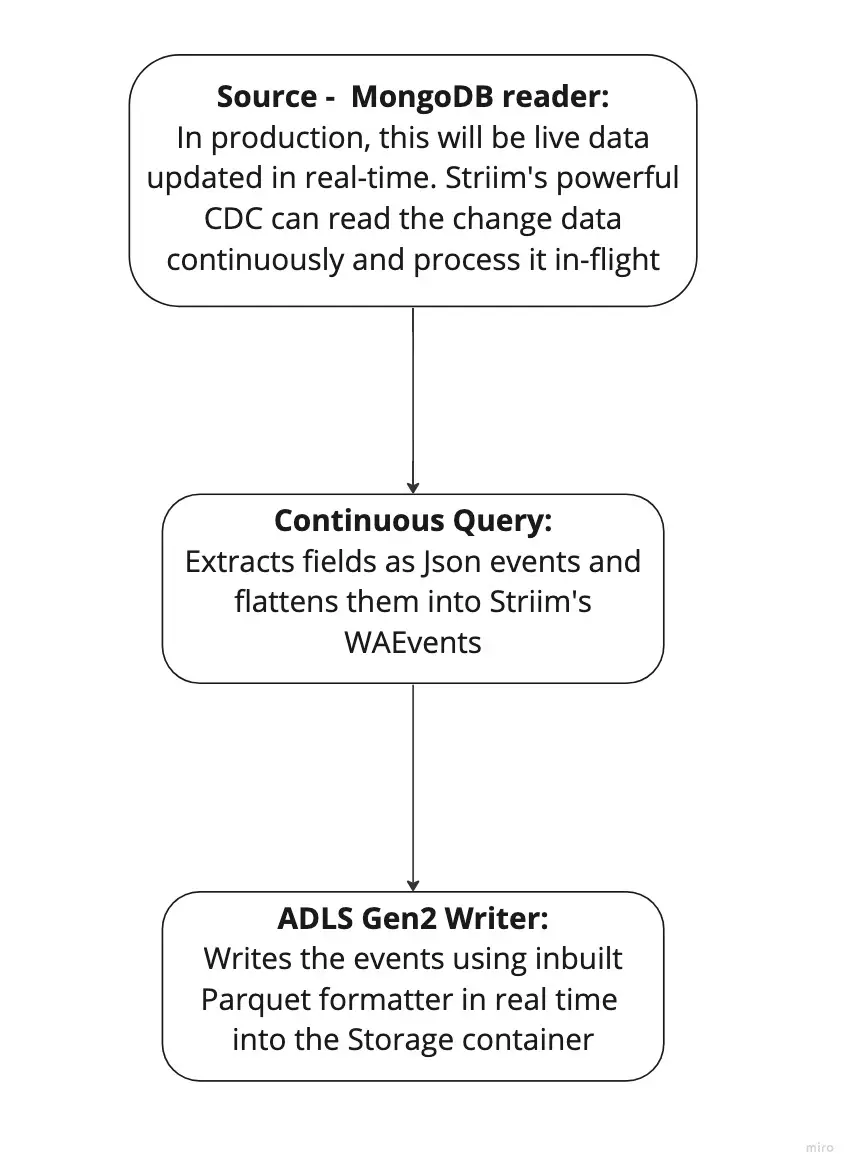
MongoDB reader: MongoDBReader reads data from the Replica Set Oplog, so to use it you must be running a replica set. In InitialLoad mode, the user specified in MongoDBReader’s Username property must have read access to all databases containing the specified collections. In Incremental mode, the user must have read access to the local database and the oplog.rs collection.
 Continuous Query: Striim Continuous Queries are continually running SQL queries that act on real-time data and may be used to filter, aggregate, join, enrich, and transform events.
Continuous Query: Striim Continuous Queries are continually running SQL queries that act on real-time data and may be used to filter, aggregate, join, enrich, and transform events.
 ADLS Gen2 Writer: Writes to files in an Azure Data Lake Storage Gen2 file system. When setting up the Gen2 storage account, set the Storage account kind to StorageV2 and enable the Hierarchical namespace.
ADLS Gen2 Writer: Writes to files in an Azure Data Lake Storage Gen2 file system. When setting up the Gen2 storage account, set the Storage account kind to StorageV2 and enable the Hierarchical namespace.
 Stream: A stream passes one component’s output to one or more other components. For example, a simple flow that only writes to a file might have this sequence.
Stream: A stream passes one component’s output to one or more other components. For example, a simple flow that only writes to a file might have this sequence.
Dashboard: A Striim dashboard gives you a visual representation of data read and written by a Striim application.
WAEvent: The output data type for sources that use change data capture readers is WAEvent.
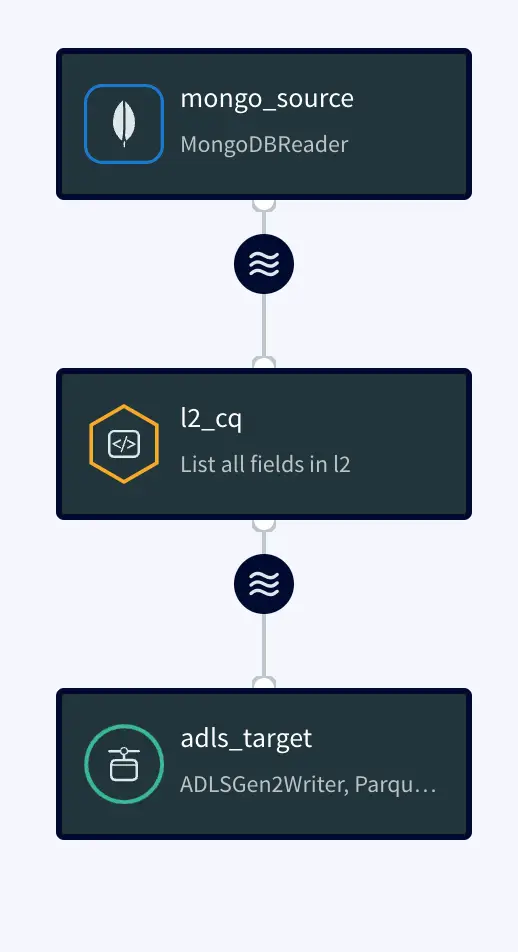
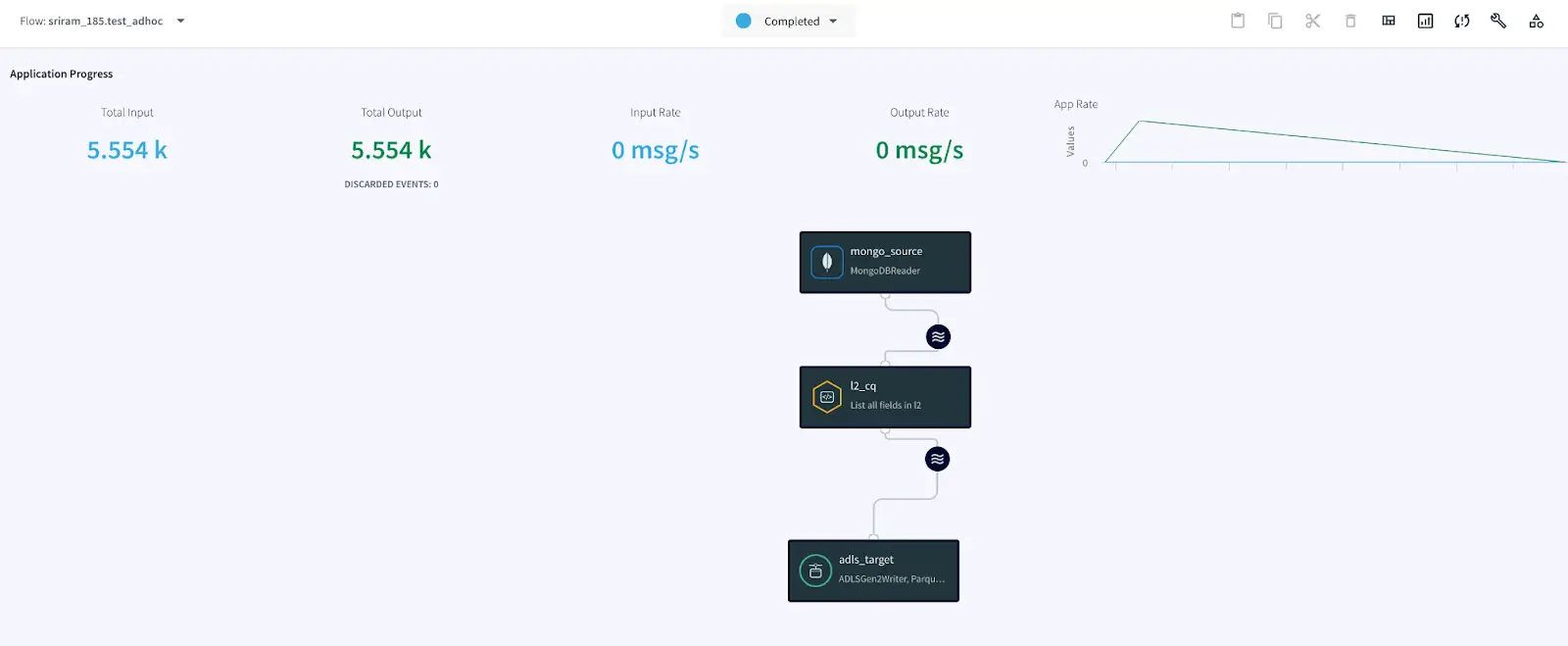
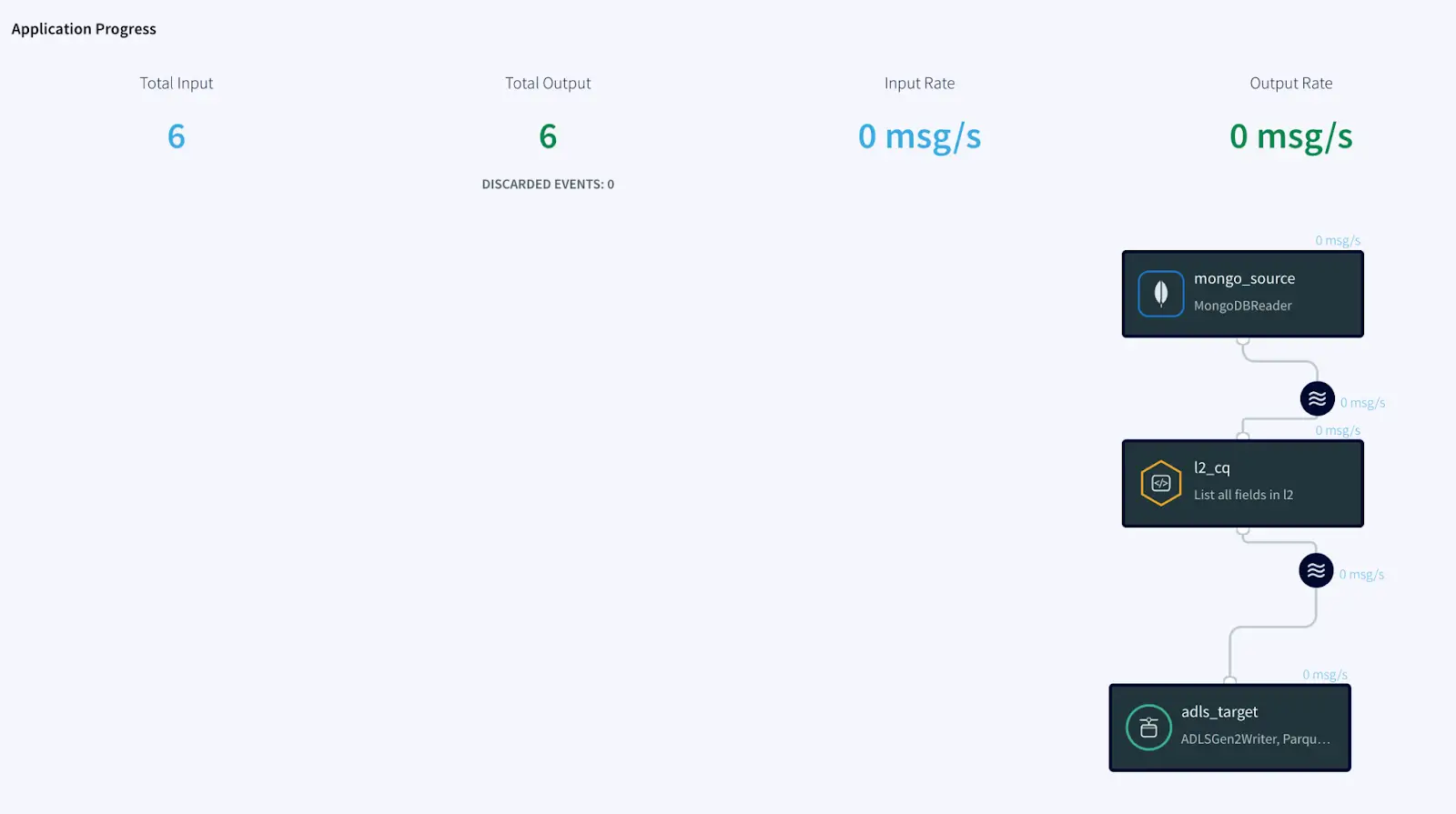
Simplified diagram of the Striim App
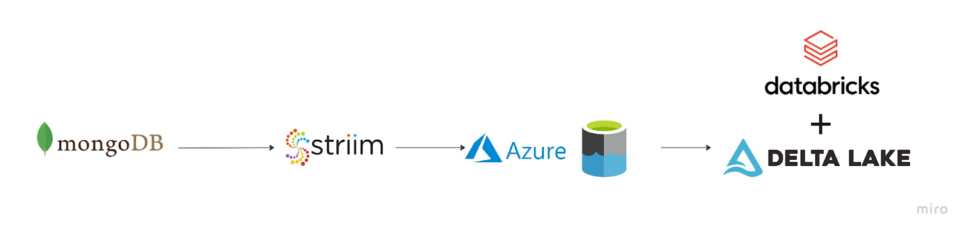
The Striim app in this recipe showcases how we can stream the CDC data from MongoDB as Json events and convert them into Parquet files before placing them into Azure’s ADLS Gen2 storage account. The same Striim app can be used to perform historical or initial loads and seamlessly convert into an incremental application once the historical data is captured.
We use the Continous Query to extract the fields from the JSON events and convert them into Parquet files using the Parquet formatter built into ADLS Gen2 writer. Once the data lands, Databricks provides us the option to convert these parquet files into a Delta table in-place.
In a production setting, Striim’s Change Data Capture allows for real-time insights from MongoDB into Databricks Delta tables.
Feel free to sign up for a Free trial of Striim here
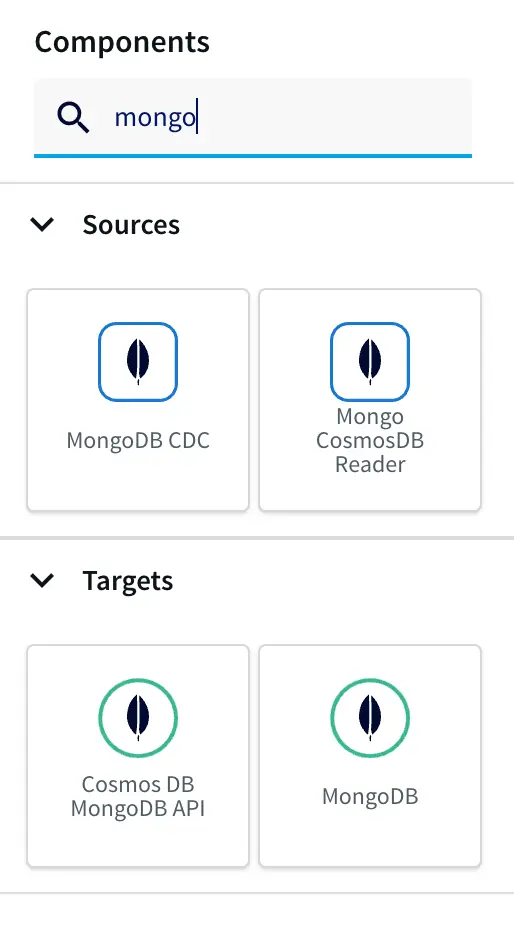
- Click on Start from scratch or use the built-in wizard by using keywords to the data source and sink in the search bar. Drag and drop the MongoDB CDC reader from Sources and enter the connection parameters for the MongoDB database cluster.
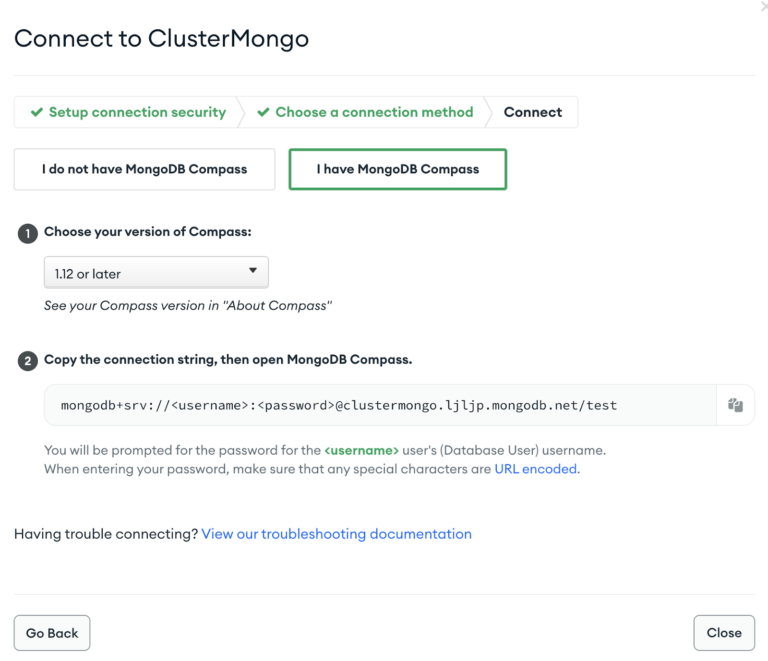
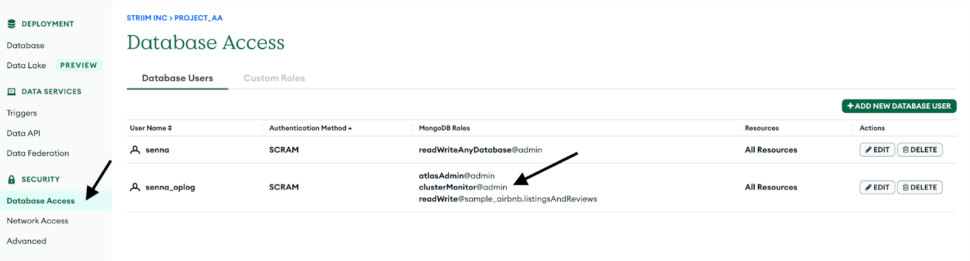
Enter the other connection URL from above along with the username, and password of the database user which has ClusterMonitor role which was created as part of Step 1. Select the type of ingestion as Initial or Incremental and Auth type as default or SCRAMSHA1.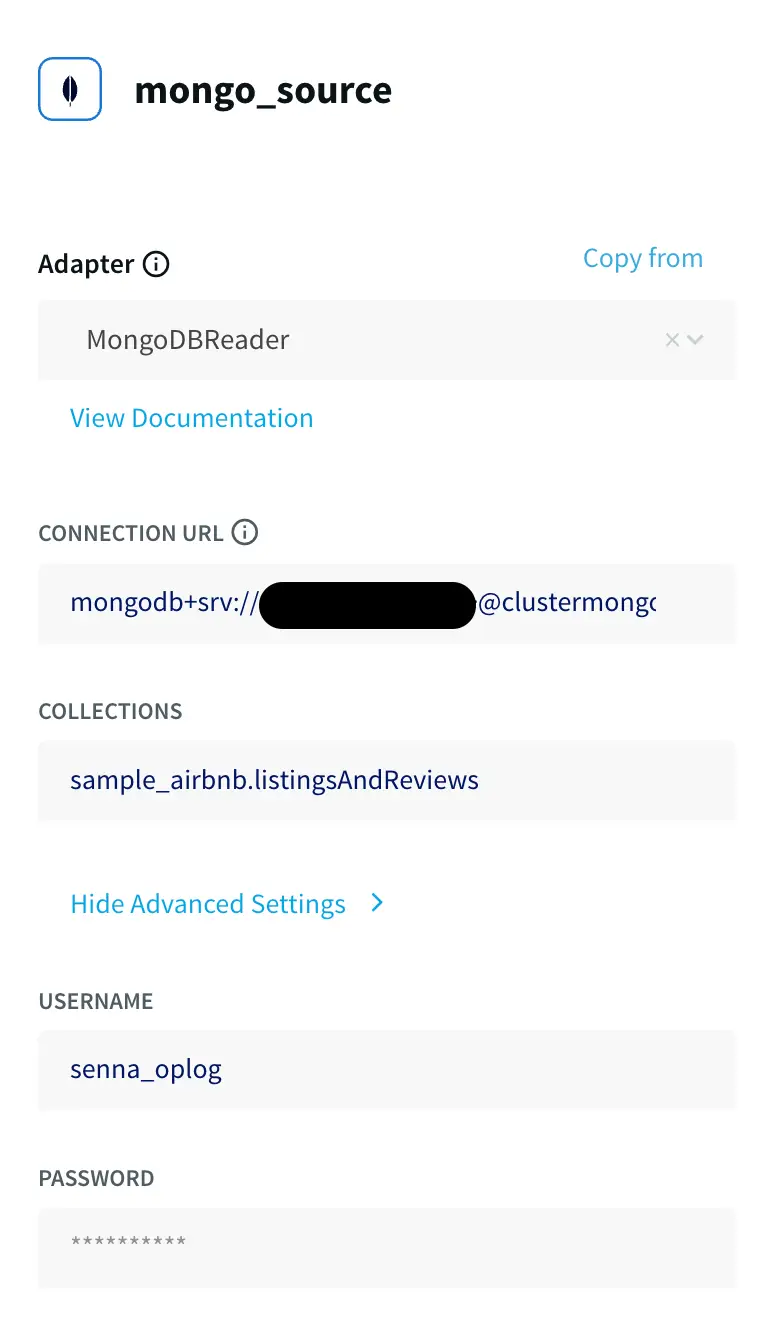
Note:
If the Striim app is configured to run Initial mode as ingestion first, do turn on the option for Quiesce on IL Completion. Set to True to automatically quiesce the application after all data has been read.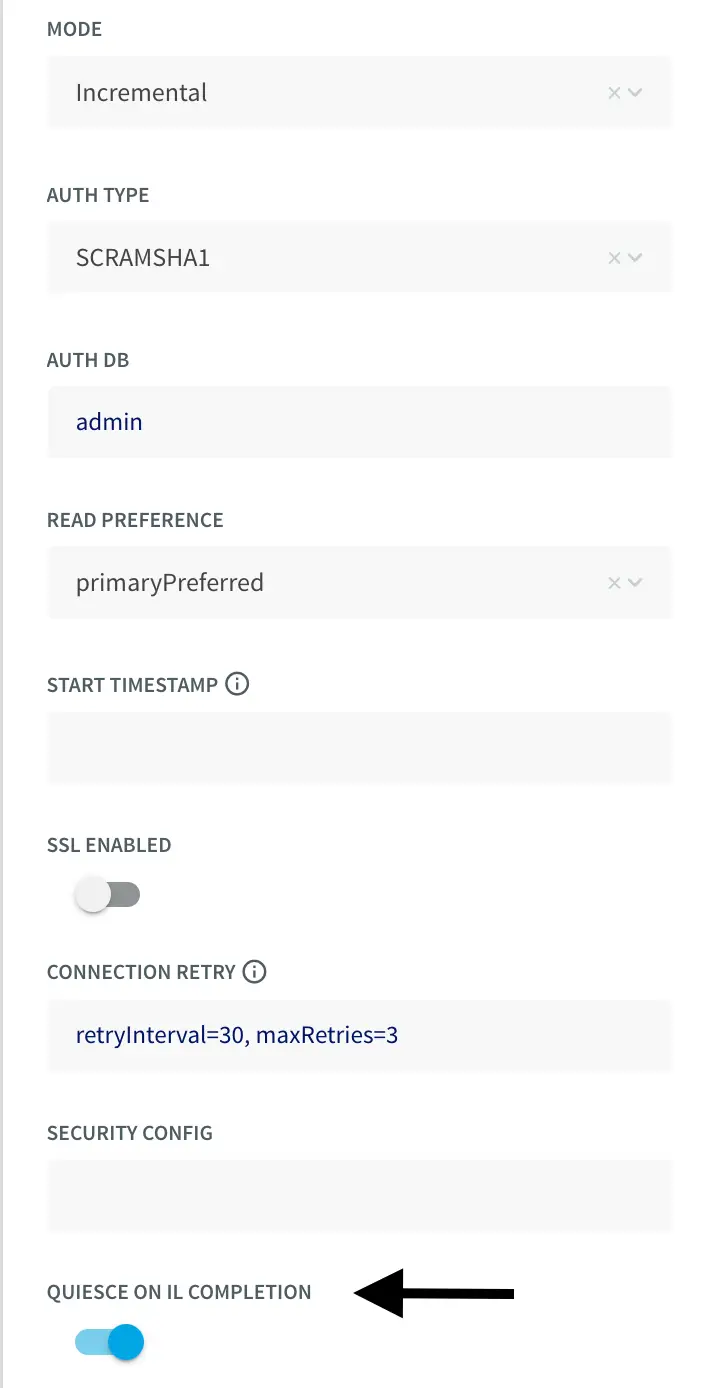
Step 3: Configure a Continous SQL Query to parse JSON events from MongoDB
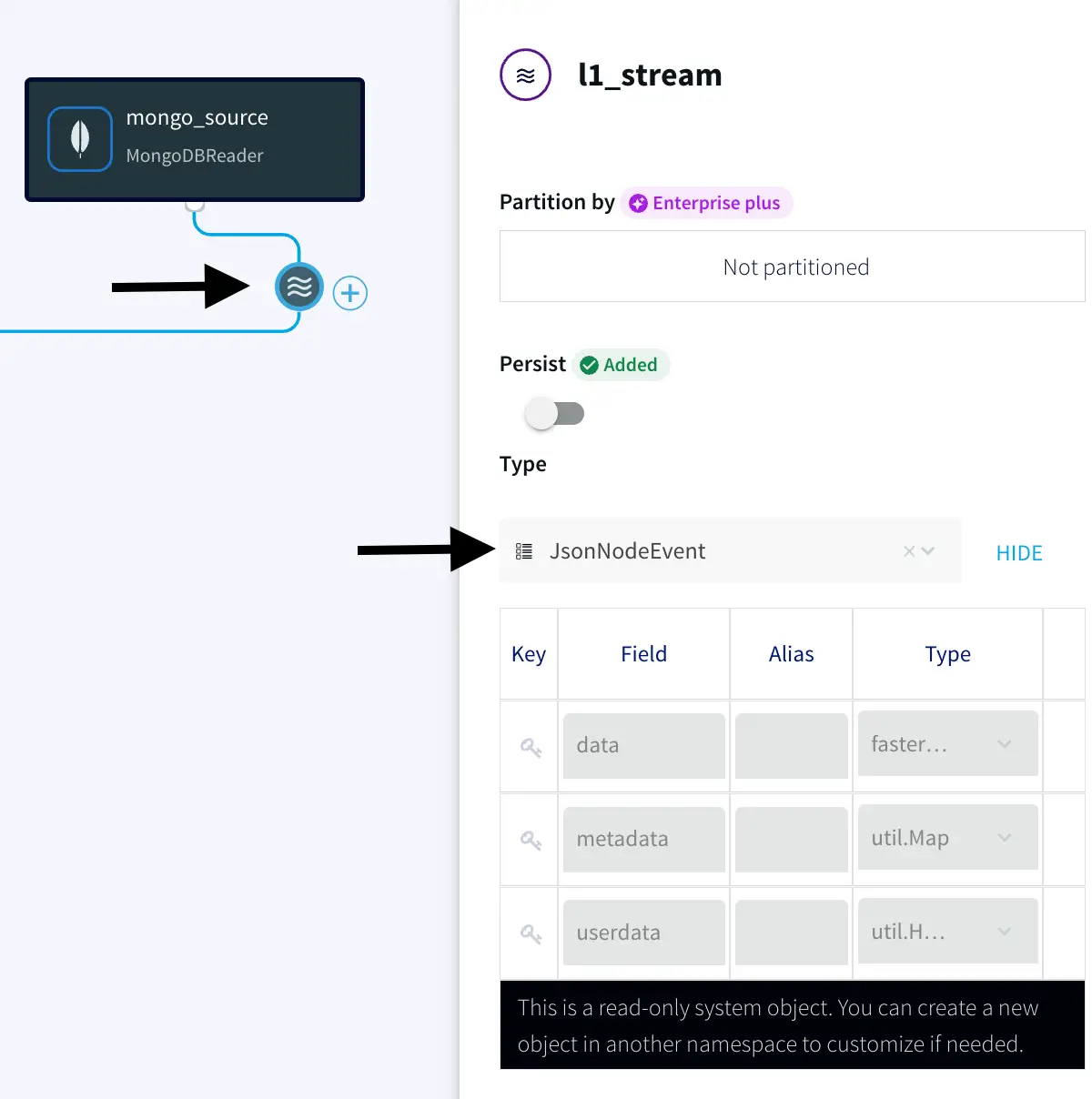
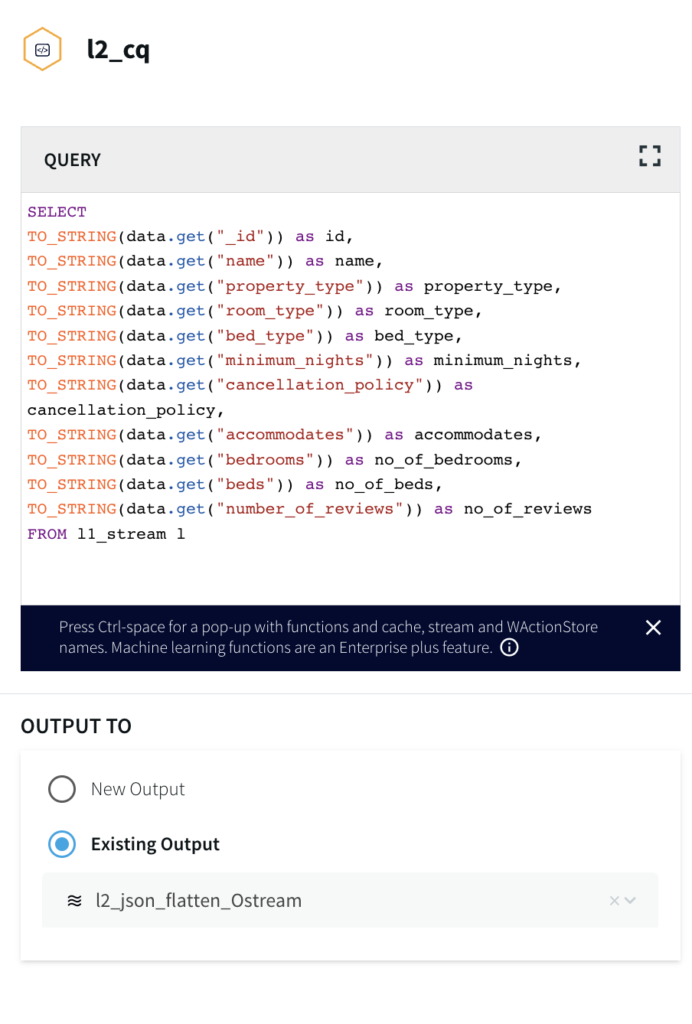
For more information on Continuous Queries refer to the following documentation and for using Multiple CQs for complex criteria.
2. Make sure the values under the Type have been picked up by the Striim app.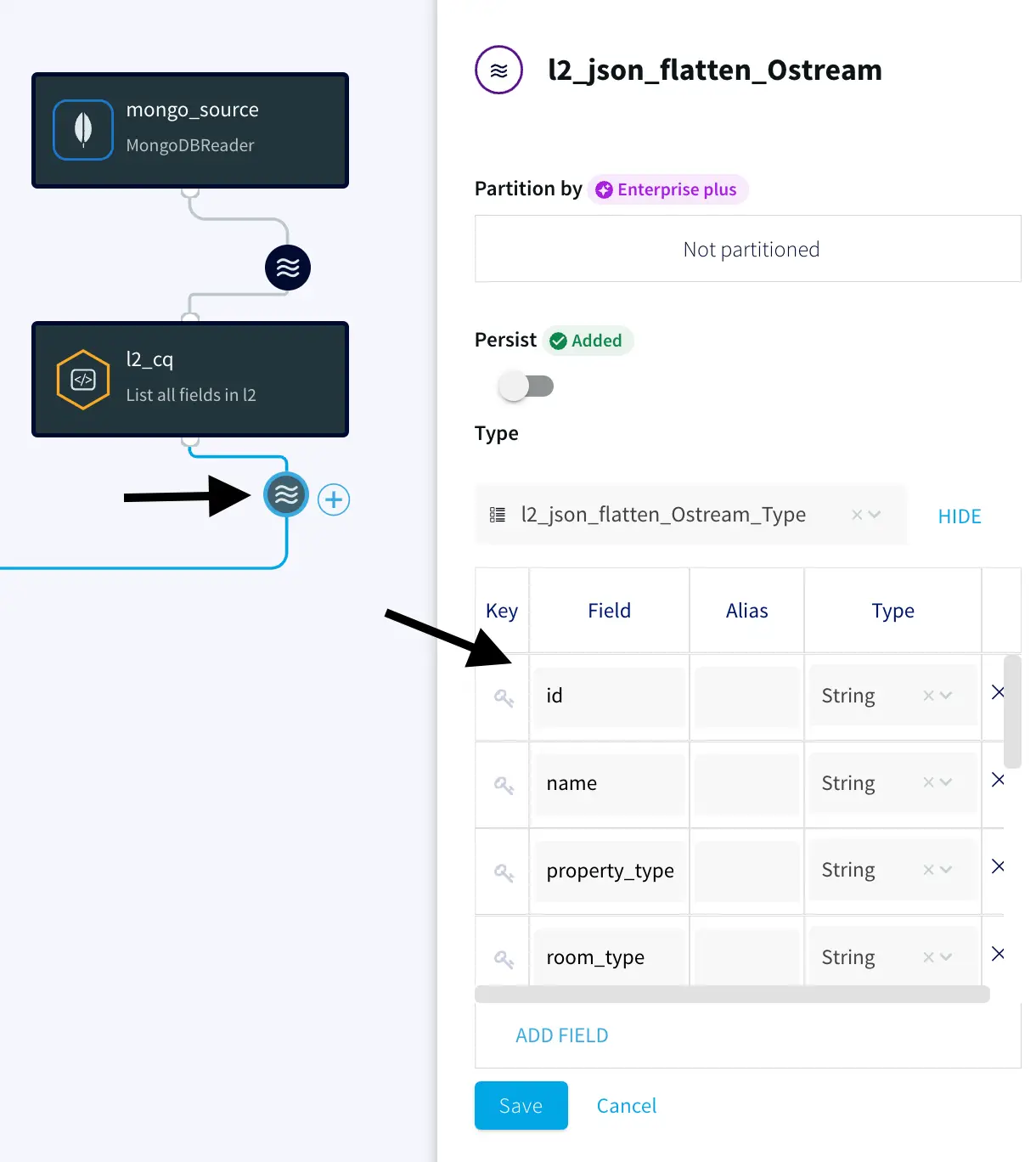
Step 4: Configure the ADLS Gen2 as a Data Sink
- Navigate to the Azure portal and create a new ADLS Gen2 and make sure to set the Storage account kind to StorageV2 and enable the Hierarchical namespace.
- Inside the Striim App, Search for the Azure Data Lake Store Gen2 under Targets and select the input stream from above.

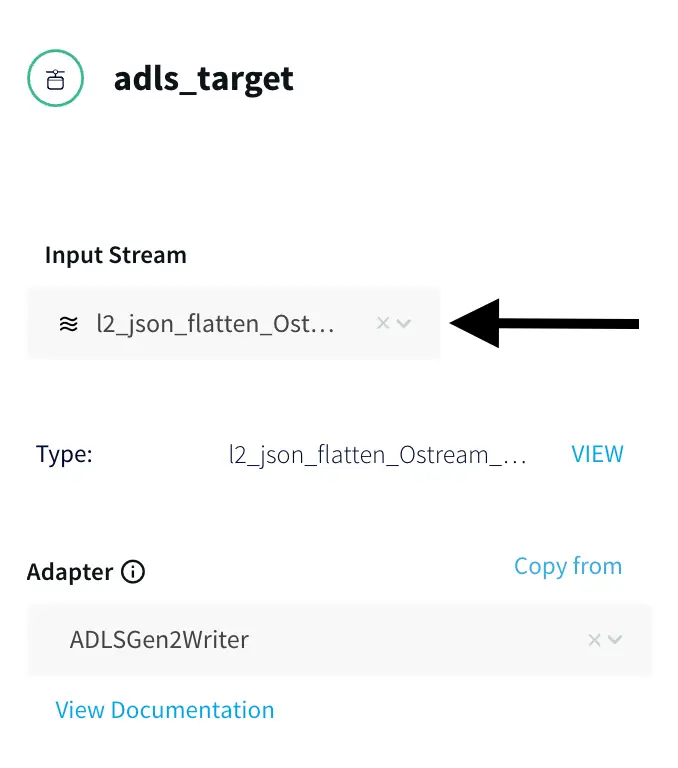
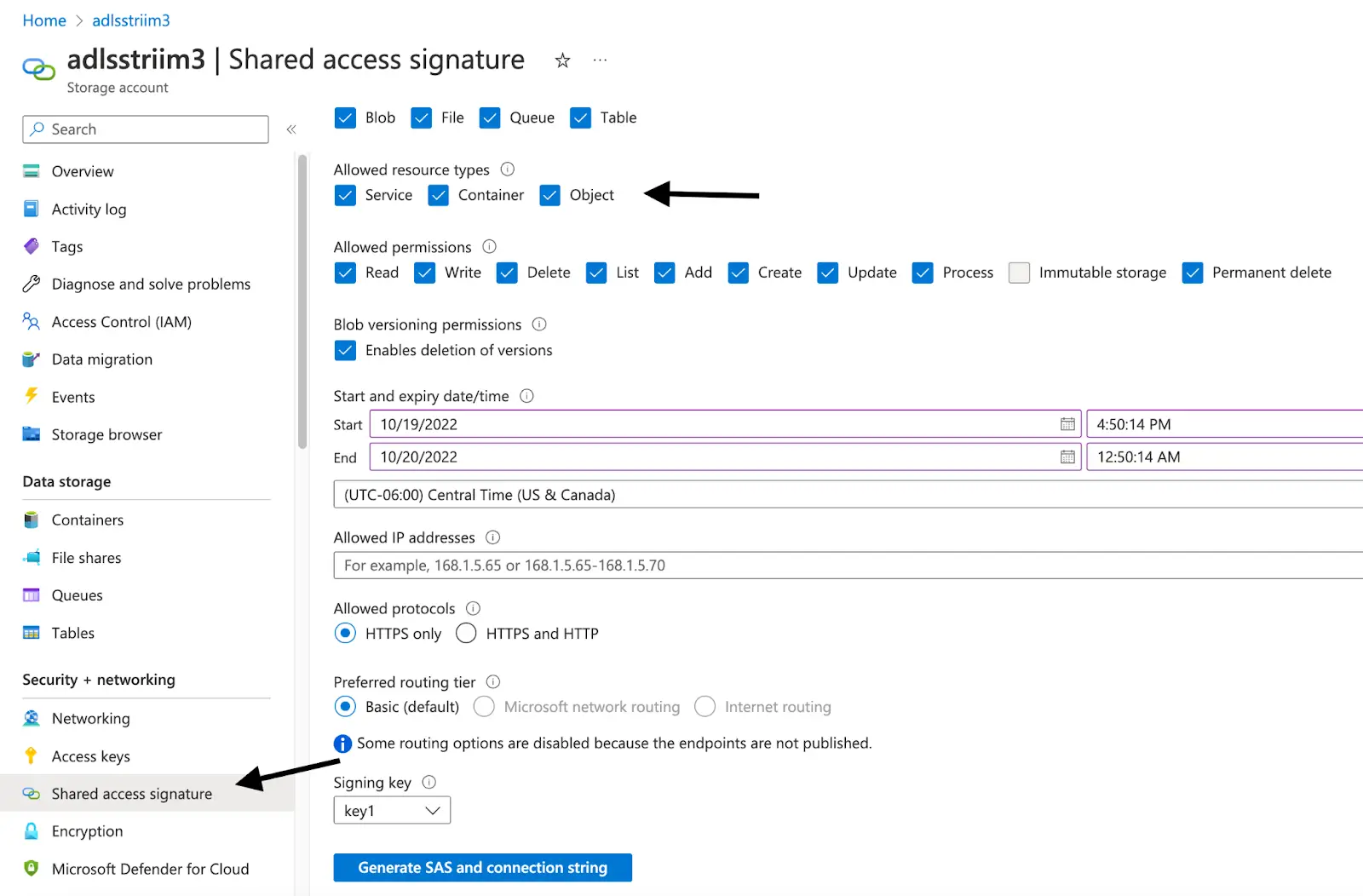
Note:
Once the SAS key is generated, Remove the ? from the beginning of the SAS token before adding it into the Striim App. Refer to the ADLS Gen2 Writer documentation here.
For example,
?sv=2021-06-08&ss=bfqt&srt=o&sp=upyx&se=2022-10-16T07:40:04Z&st=2022-10-13T23:40:04Z&spr=https&sig=LTcawqa0yU2NF8gZJBuog%3D
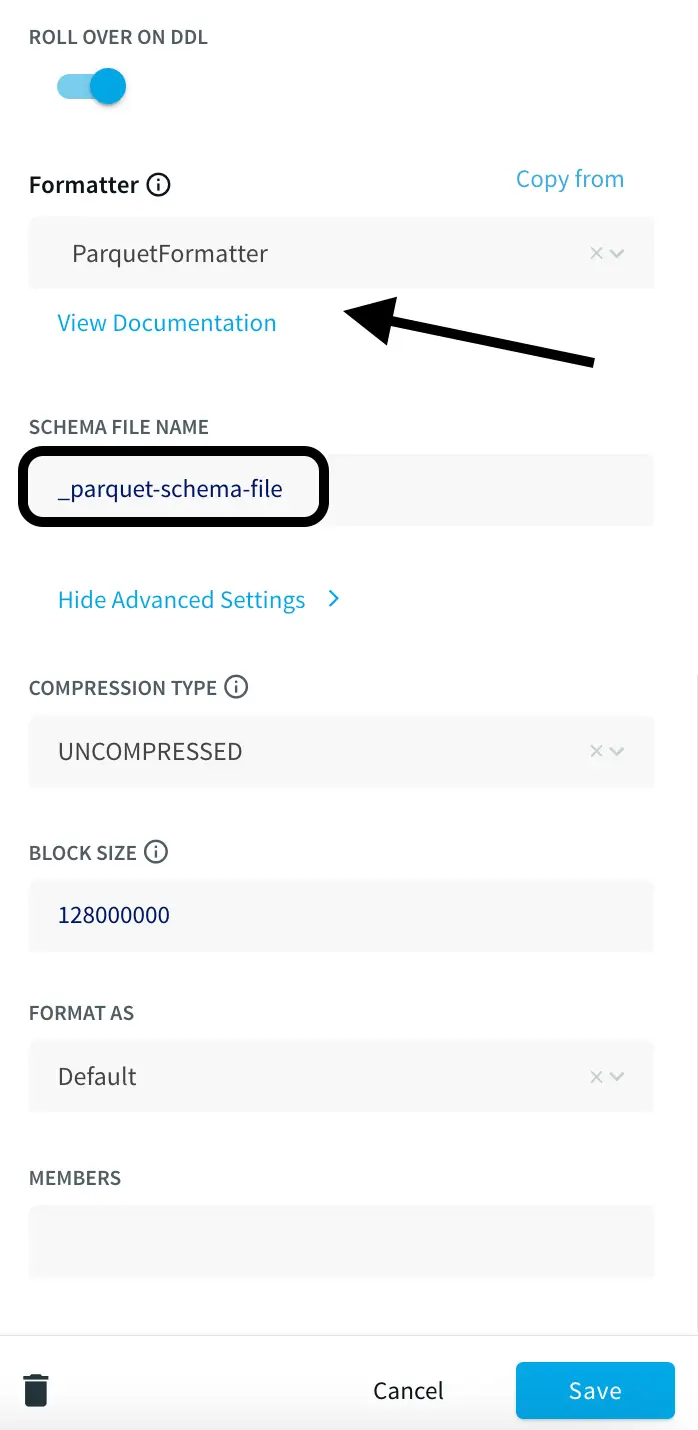
- Add the mandatory fields like Filesystem name, File name, and directory (if any), and also enable Roll Over on DDL which has a default value of True. This allows the events to roll over to a new file when a DDL event is received. Set to False to keep writing to the same file.

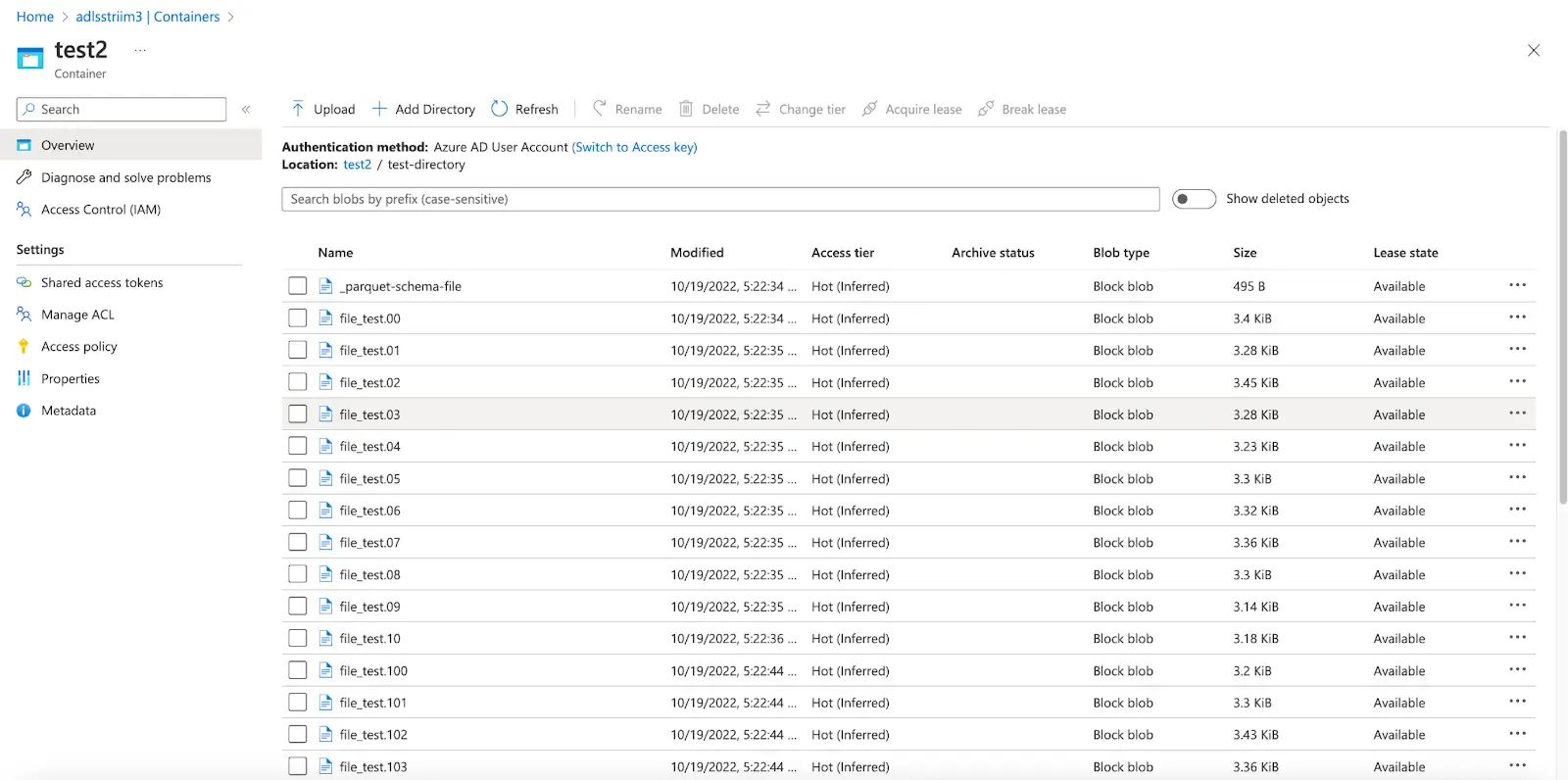
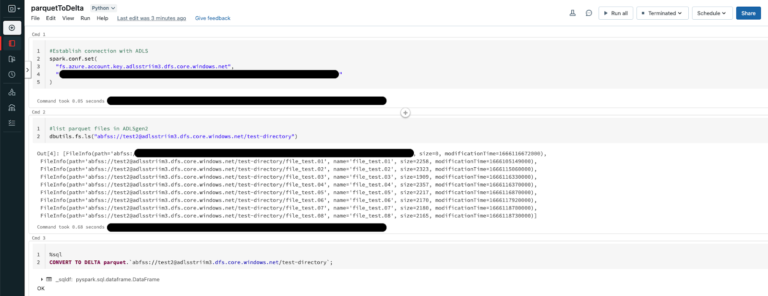
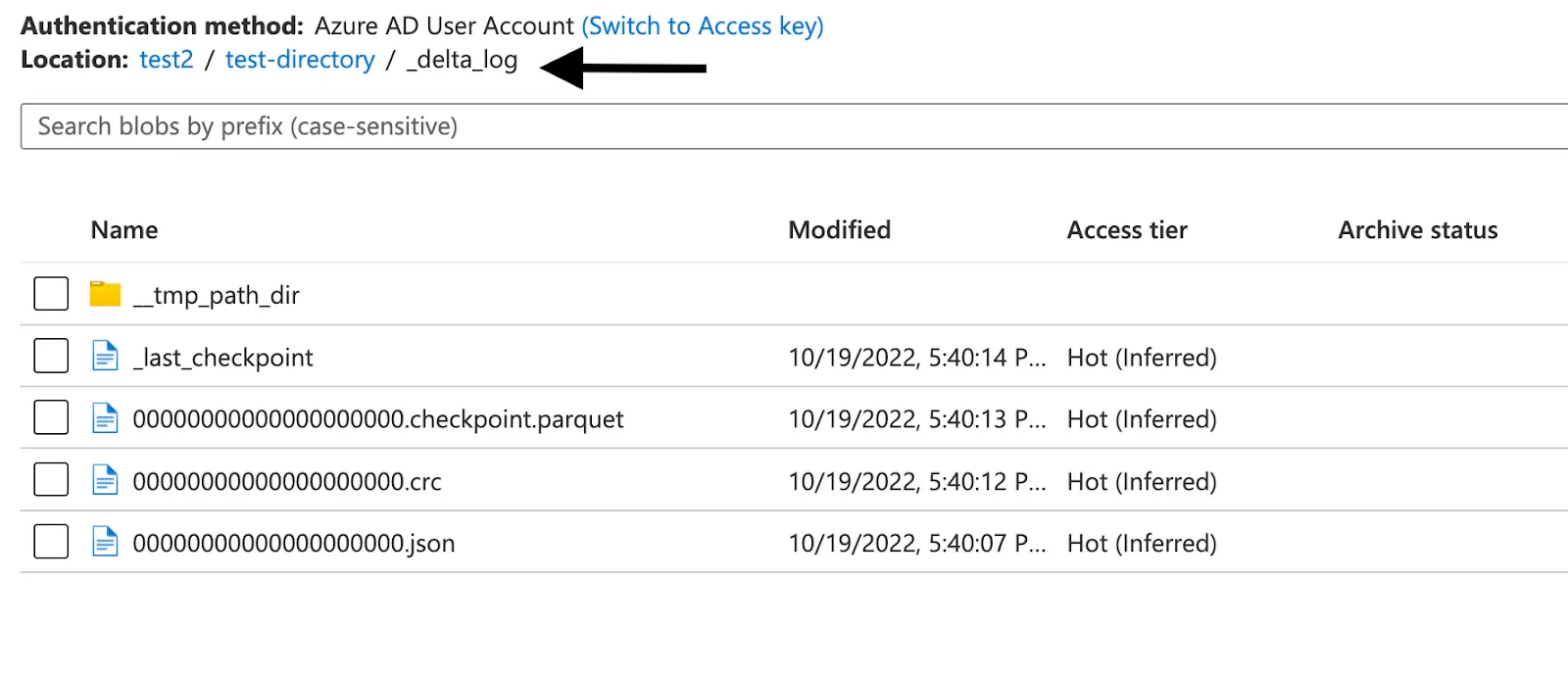
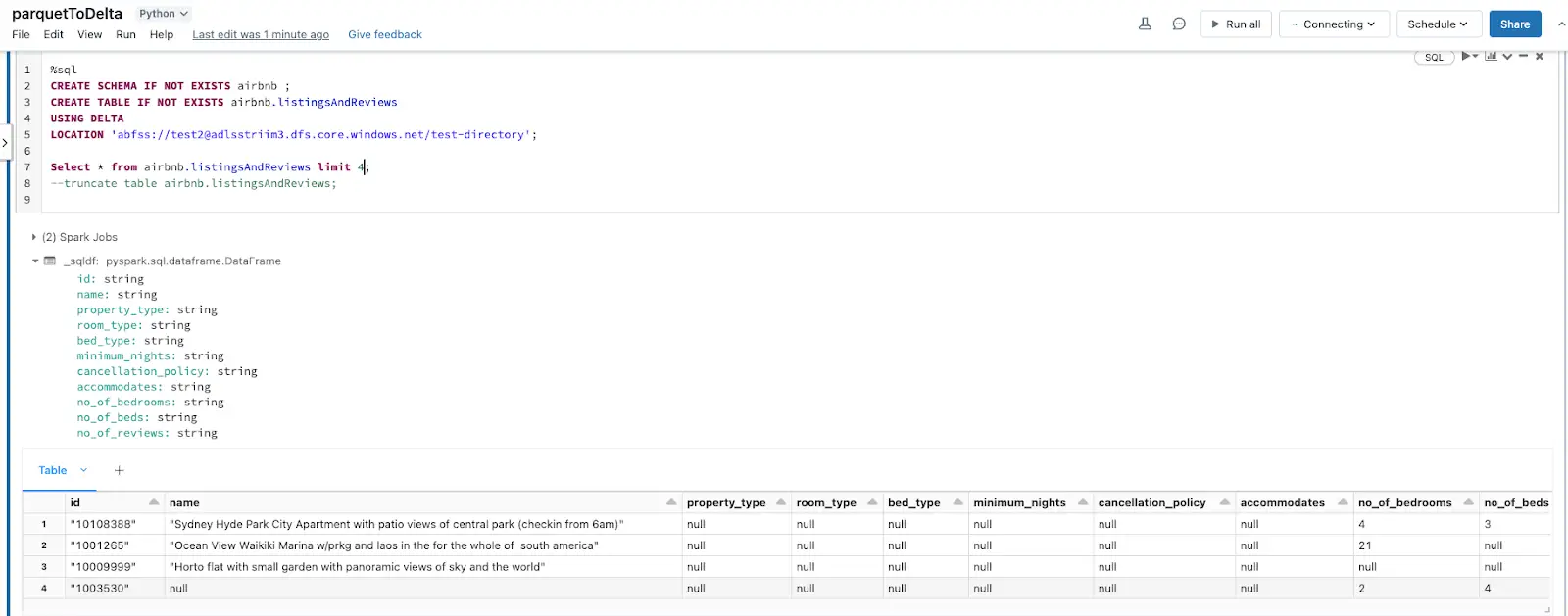
Once the _delta_log is created, any new Parquet file landing in the storage container will be picked up by the Delta table allowing for near real-time analytics.
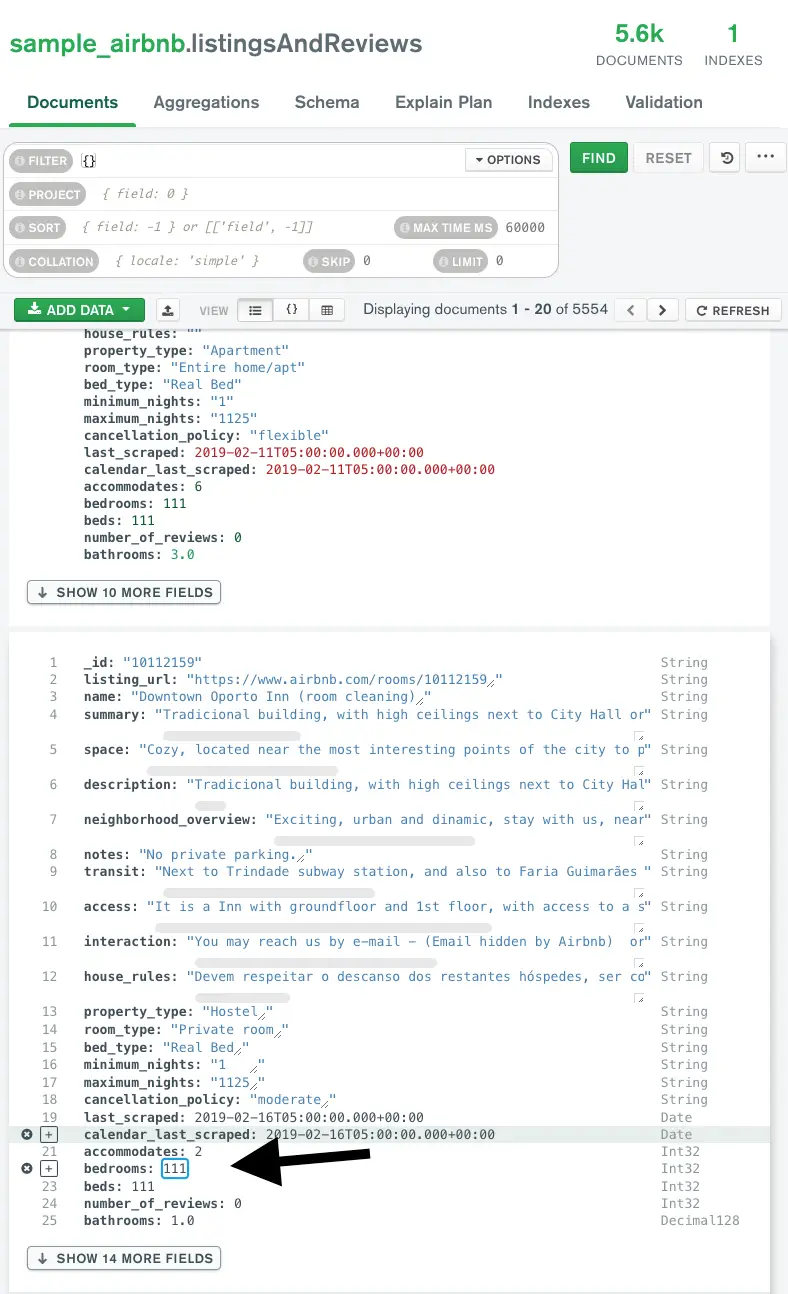
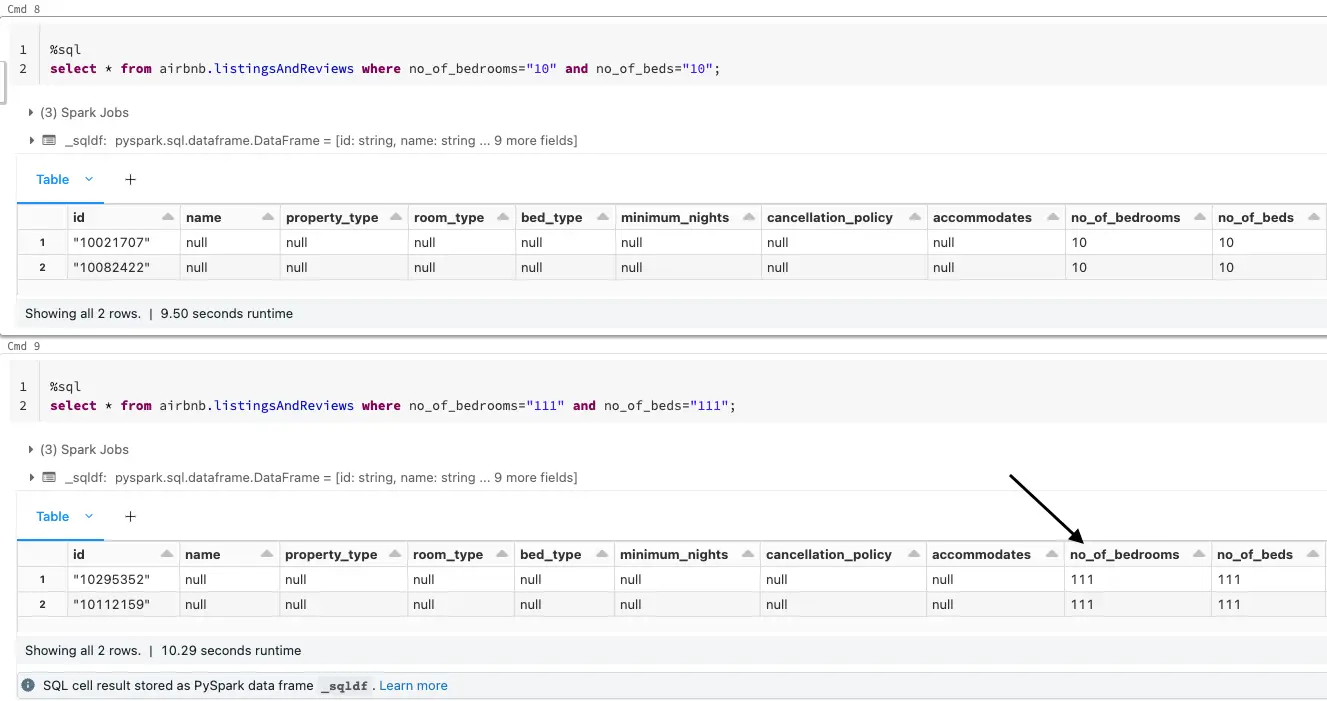
For instance, when the values for certain fields have been updated as shown below, Striim CDC application is able to pick up the CDC data and convert them into Parquet files on the fly before landing in ADLS.

Striim
Striim’s unified data integration and streaming platform connects clouds, data and applications.

Databricks
Databricks combines data warehouse and Data lake into a Lakehouse architecture

Azure ADLS Gen2
Azure ADLS Gen2 storage is built on top of Blob Storage and provides low-cost, file system semantics and security at scale.

MongoDB
NoSQL database that provides support for JSON-like storage with full indexing support.