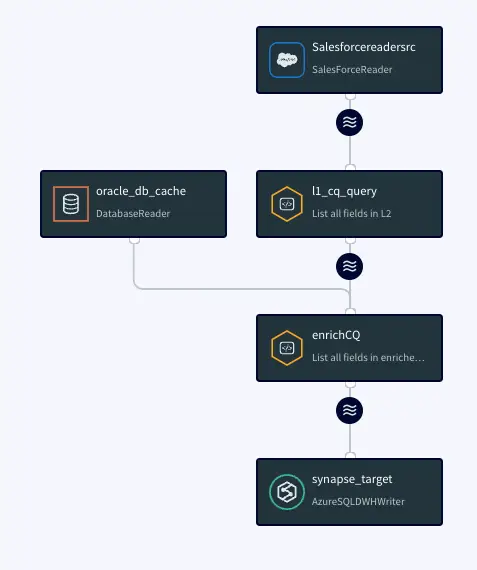
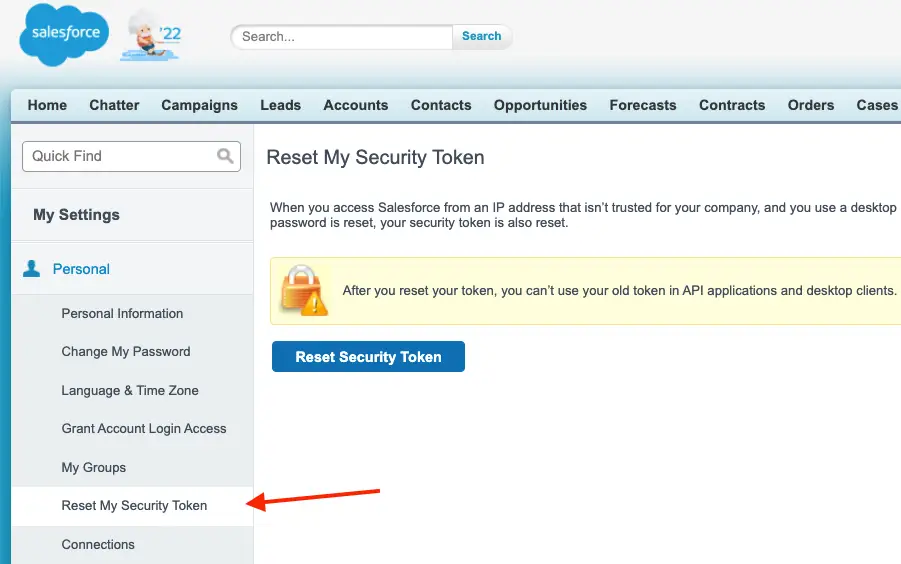
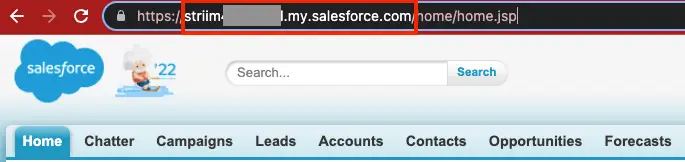
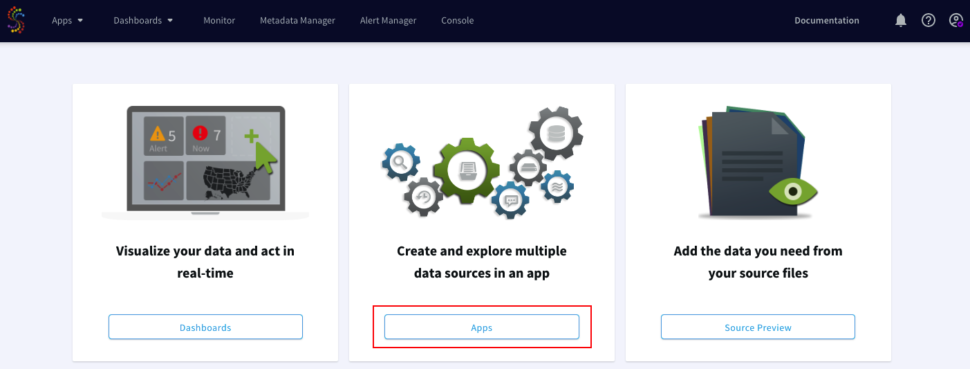



Striim
Striim’s unified data integration and streaming platform connects clouds, data and applications.
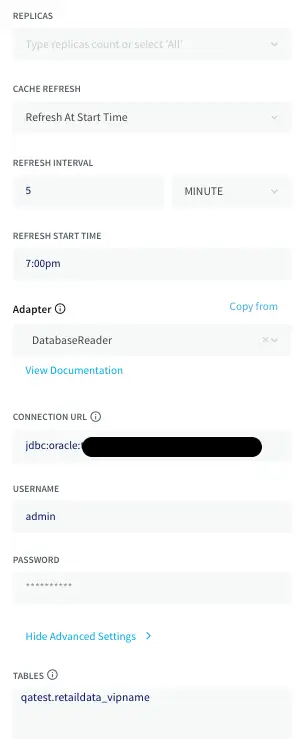
Oracle
Oracle is a multi-model relational database management system.
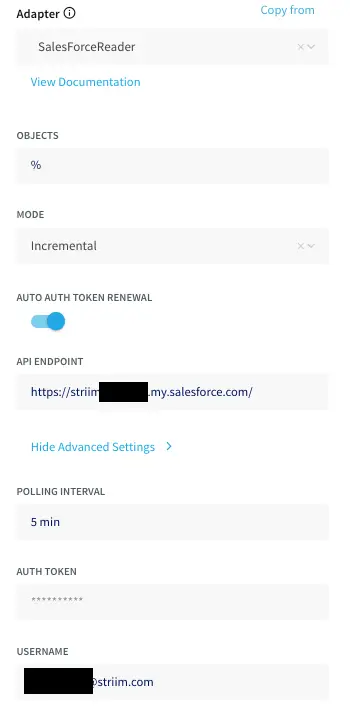
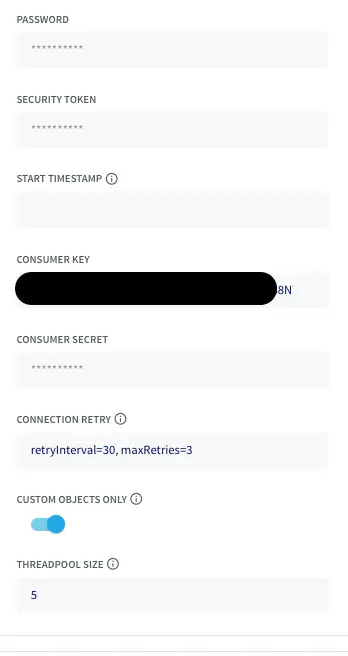
Salesforce
Salesforce is a popular CRM tool for support, sales, and marketing teams worldwide

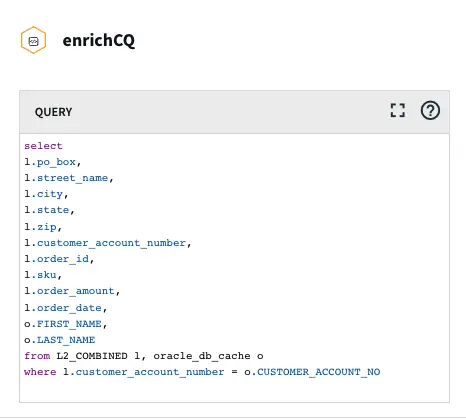
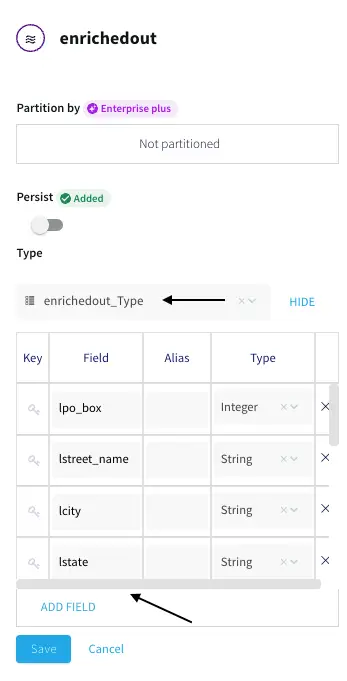
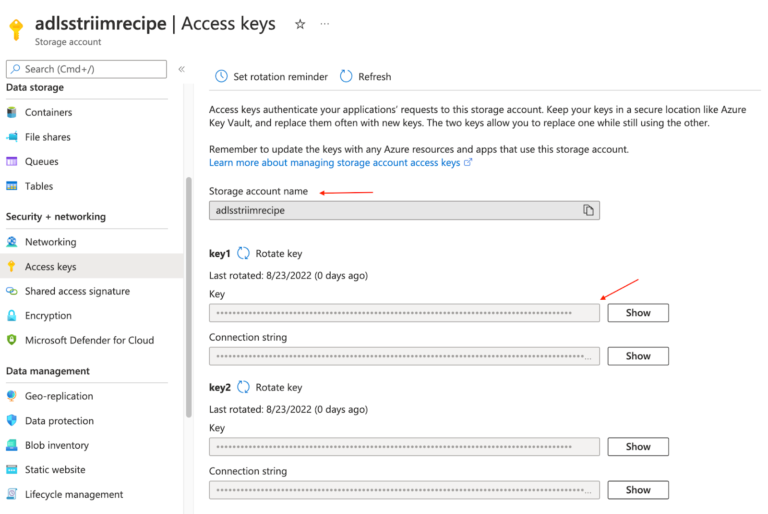
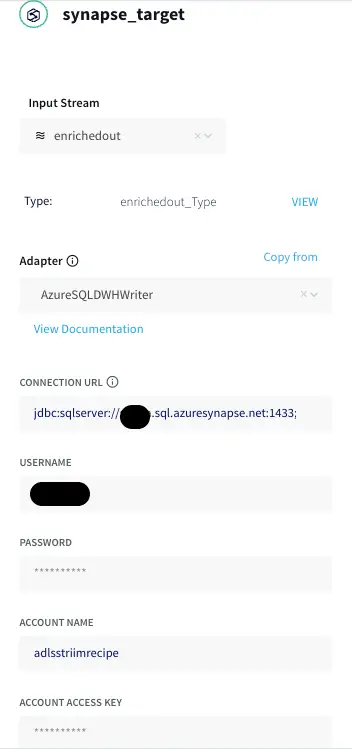
Azure Synapse
Azure Synapse Analytics is a limitless analytics service that brings together data integration, enterprise data warehousing, and big data analytics