










Overview
Many companies need to maintain a history of changes on the lifecycle of their customers while keeping the latest ‘source of truth’. When this data is processed in an operational database (PostgreSQL, MySQL, MongoDB), the common method of doing the above is change data capture to a cloud data warehouse (Snowflake, BigQuery, Redshift). However there are challenges here: how do I use the same CDC stream to A) apply the changes as DML to a table in my warehouse and B) maintain a separate table to track the history WITHOUT copying data inefficiently or creating multiple CDC clients on the database (each client adding some processing overhead).
Striim is a unified data streaming and integration product that offers change data capture (CDC) enabling continuous replication from popular databases such as Oracle, SQLServer, PostgreSQL and many others to target data warehouses like BigQuery and Snowflake. The CDC capabilities of Striim makes it a powerful tool to track changes in real time whenever a table is altered.
In this recipe we have shown how we can use Striim to maintain historical records while streaming data that gets frequently updated. For example, when engineering teams have a production table that overwrites data, such as users in a CUSTOMERS table change their addresses and the table is updated with the new data. However, for tax and reporting purposes, a record of the customer’s previous addresses is required. We can use CDC to solve this without requiring engineering effort from the backend teams.
One possible solution is a Batch ETL process directly into Snowflake with dbt Snapshots running regularly to mimic a CDC-like process. The problem with this approach is that it only detects changes when it’s running. If a record changed twice between dbt Snapshots, then the first change is lost forever. To support the CDC-like behavior, you have to run your batch ETL more frequently in order to reduce (but not eliminate) the likelihood of missing a change between runs.
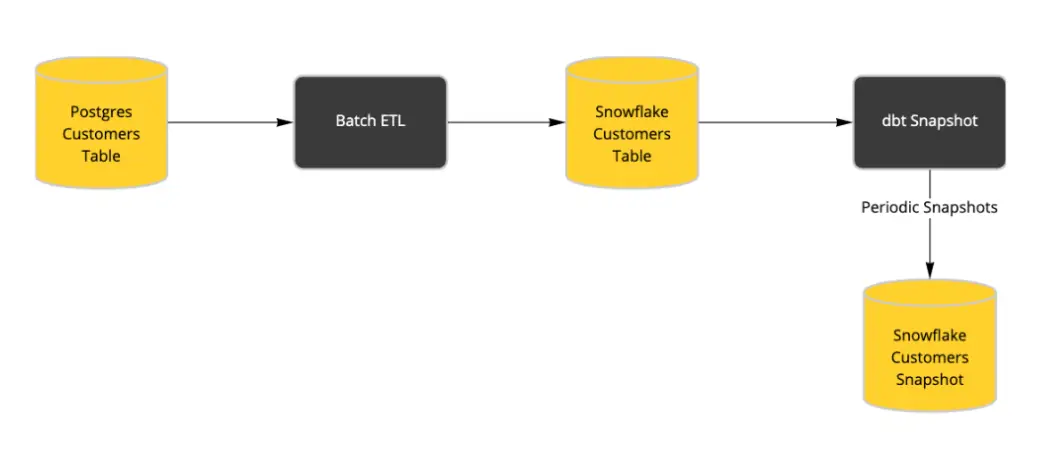
We can leverage Striim to generate a CDC feed from source database (eg. PostgreSQL) that captures all changes as they happen. All new and updated records are appended to an audit/history table and at the same time, we use Snowflake’s merge function to maintain an up-to-date list of current customer information.
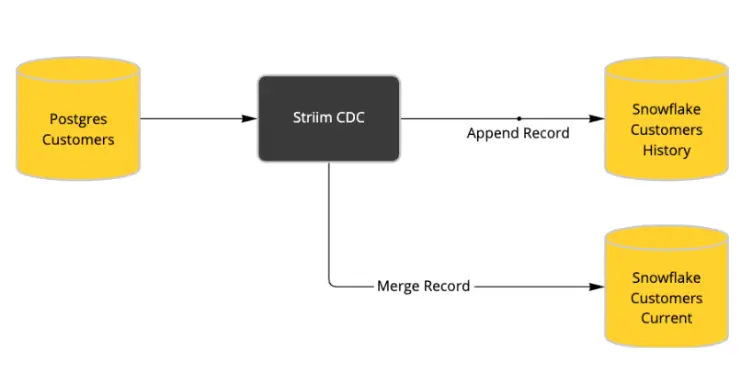
The latter architecture gives correctness and avoids maintainability problems that occur in batch/scheduled snapshots. There is a reduction in cost as updates are run only when the data changes and not on a fixed schedule. The data pipeline is simpler with only one connector/CDC stream for incoming data. Last but not least, this architecture can be easily extended with additional functionality, e.g. Slack Notification when a change occurs.
Please follow the steps below to set up your CDC source and configure the target table for both historical records table and most up-to-date table.
Core Striim Components
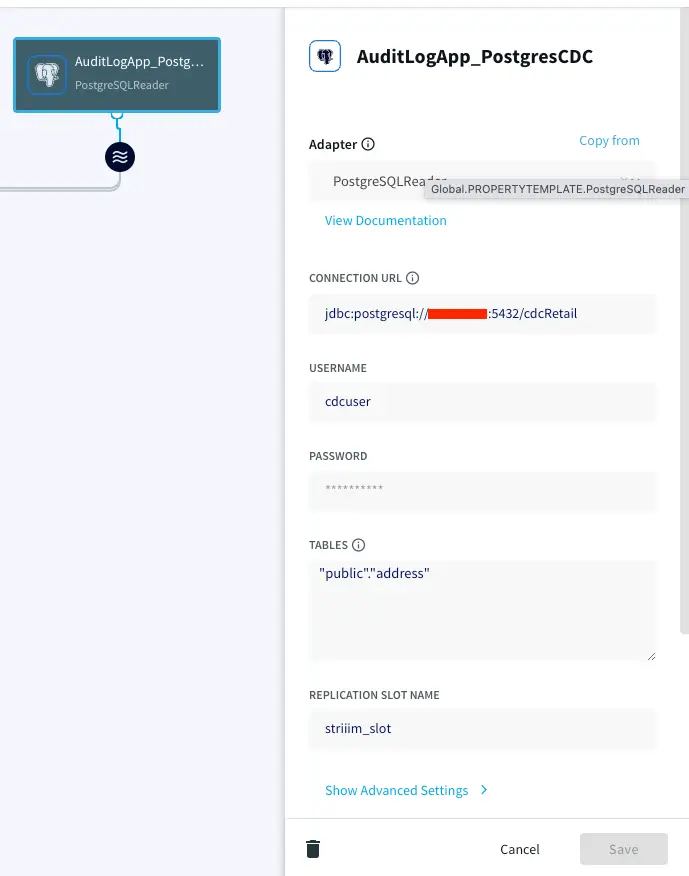
PostgreSQL Reader: PostgreSQL Reader uses the wal2json plugin to read PostgreSQL change data.
Stream: A stream passes one component’s output to one or more other components. For example, a simple flow that only writes to a file might have this sequence.
Snowflake Writer: Striim’s Snowflake Writer writes to one or more existing tables in Snowflake. Events are staged to local storage, Azure Storage, or AWS S3, then written to Snowflake as per the Upload Policy setting.
Step 1: Set up your Source Database
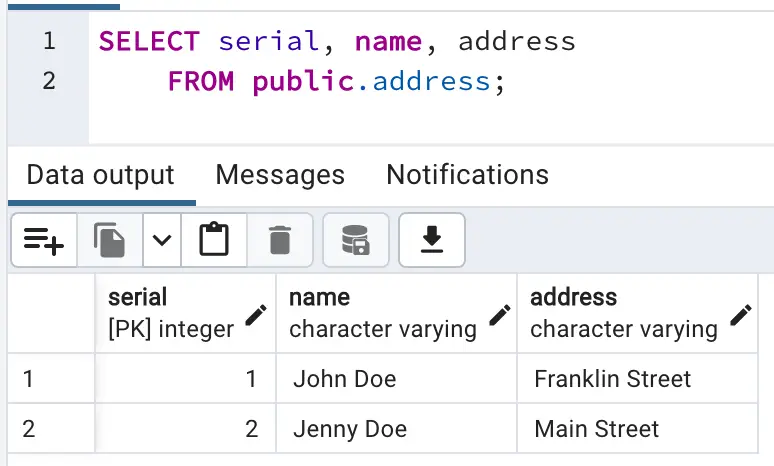
For this recipe, our source database is PostgreSQL. A table containing customer names and addresses is updated when a customer changes their address. It is very important to have a Primary Key column to capture DMLs like Update and Delete operations.
Step 2: Set up your Snowflake Targets
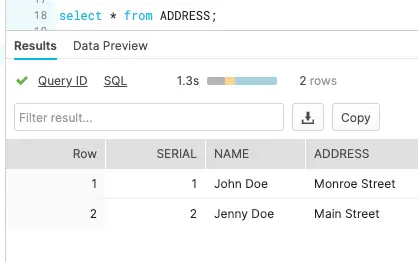
The target tables for this streaming application are hosted in snowflake data warehouse. There is an AUDIT table that stores all new as well as historical records for each customer and a second table called ADDRESS stores the most recent records for each customer.
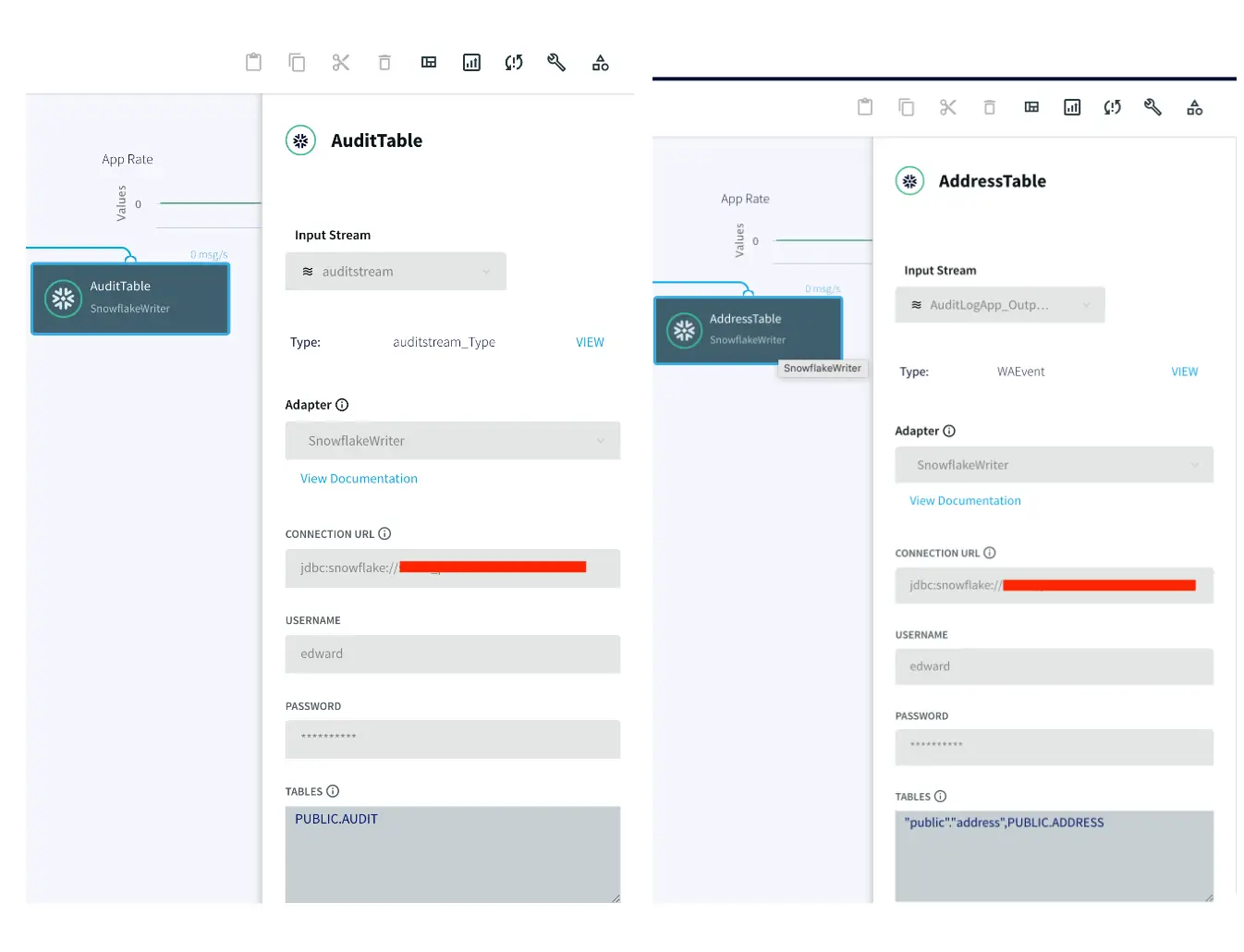
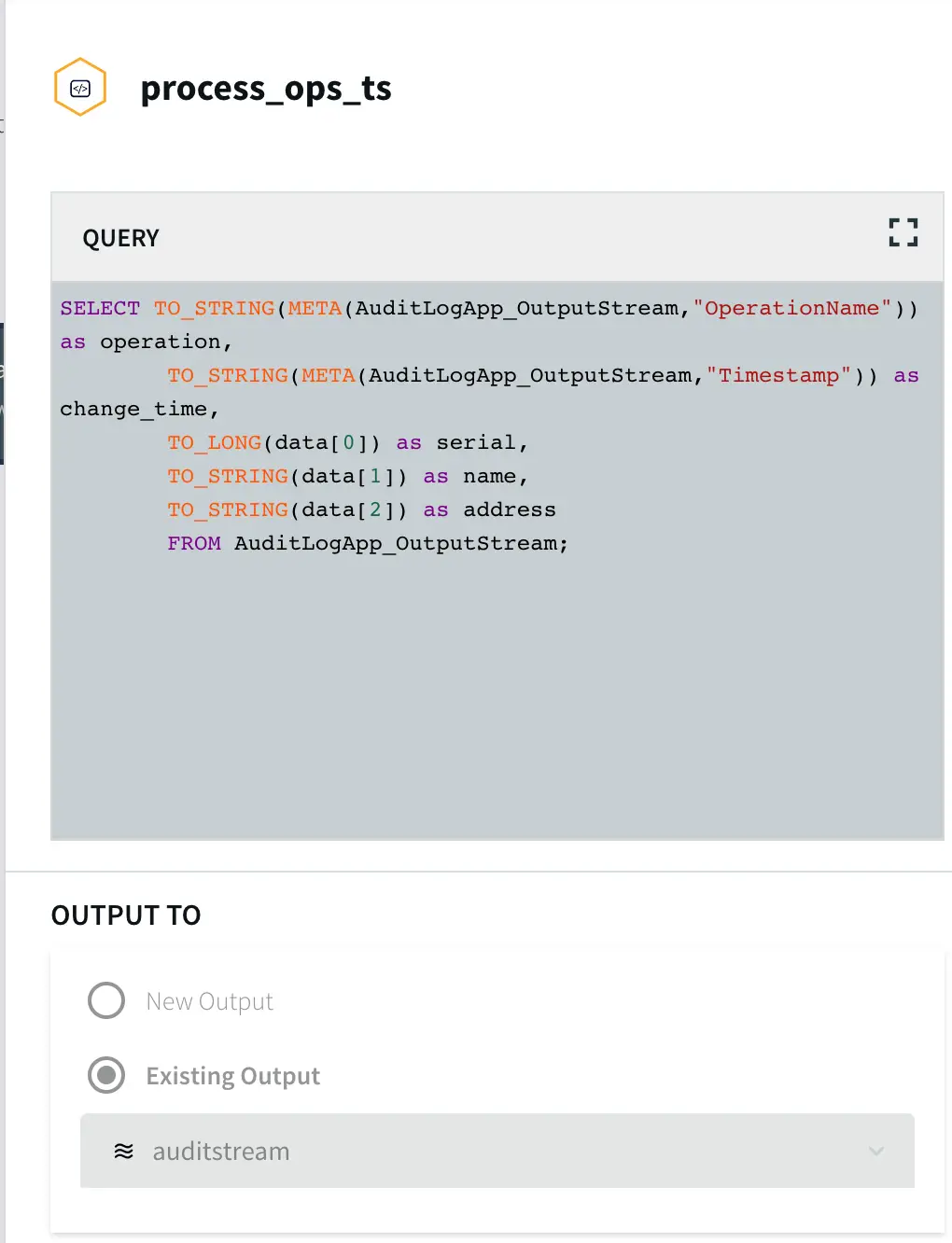
To insert data into AUDIT table, we process the input stream with a Continuous Query to include operation time and Timestamp when CDC occurred using the metadata. The APPEND ONLY setting is set to True that handles the updates and deletes as inserts in the target.
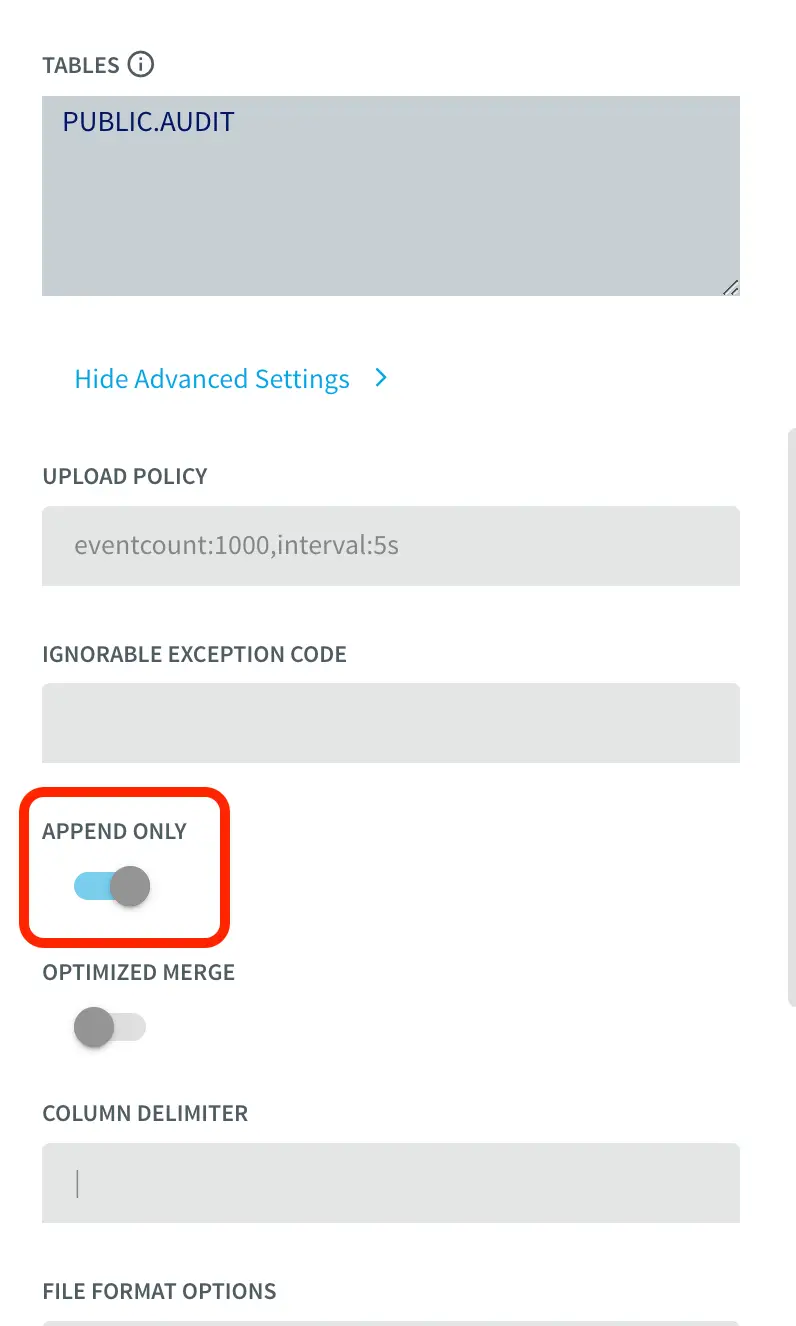
With the default value of False, updates and deletes in the source are handled as updates and deletes in the target. With Append Only set to True, Primary key updates result in two records in the target, one with the previous value and one with the new value. For more information on Snowflake Writer, please follow the Striim documentation.
Step 3: Run the app and update your source table
Once the source and target adapters are configured, deploy and run the Striim app and update your source table to stream both updated and historical data into the target tables. You can download the app TQL file from our github repo. Perform the following DMLs on your source table:
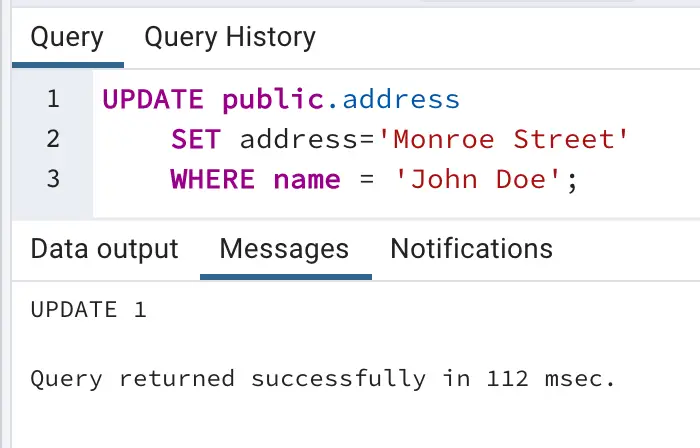
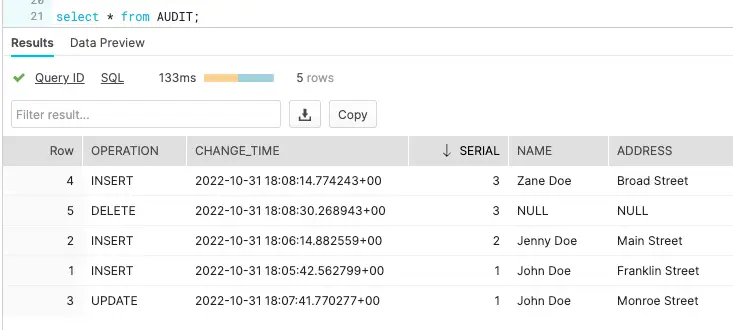
- Update address for ‘John Doe’ from ‘Franklin Street’ to ‘Monroe Street’
- Insert a new record for customer ‘Zane Doe’
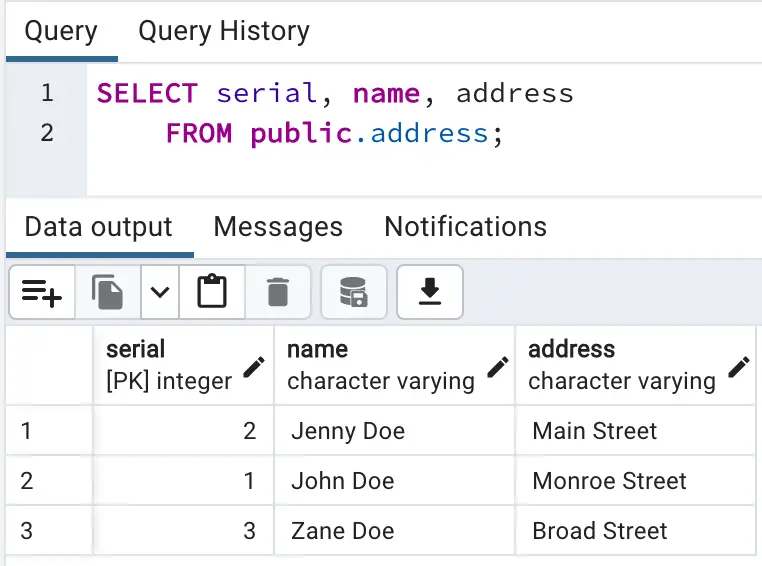
- Delete the row containing information about ‘Zane Doe’
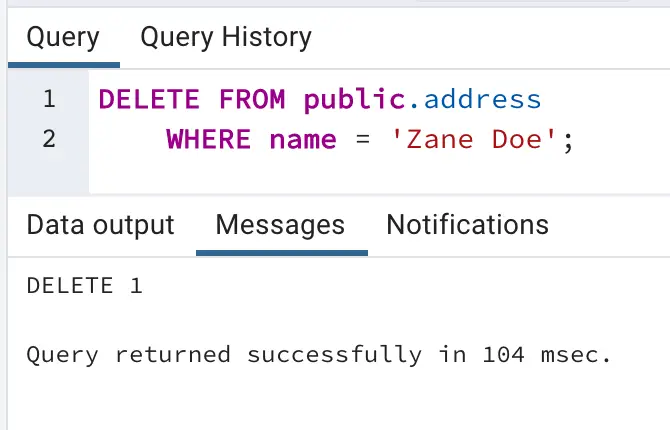
We can check the target table and preview the data stream between source and target adapters after each DML to confirm if the target table has been populated with desired records. As shown below, when a row is updated (Preview 3), an UPDATE operation on metadata is streamed, similarly for INSERT (Preview 4) and DELETE (Preview 5), operations in the source table are reflected.
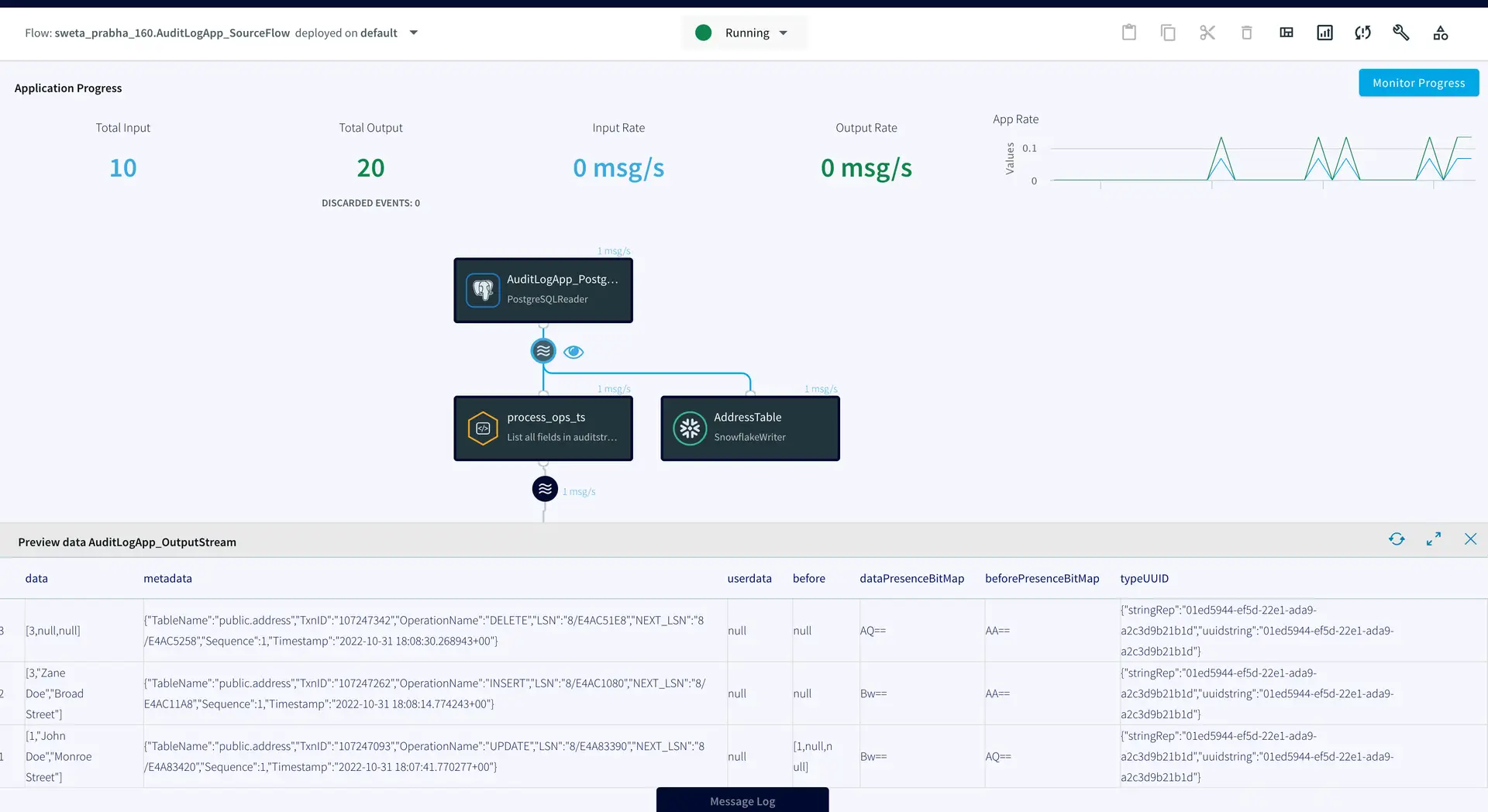
The ADDRESS table in the snowflake data warehouse has the most updated record whereas AUDIT table stored all the previous records.

Striim
Striim’s unified data integration and streaming platform connects clouds, data and applications.
PostgreSQL
PostgreSQL is an open-source relational database management system.

Snowflake
Snowflake is a cloud-native relational data warehouse that offers flexible and scalable architecture for storage, compute and cloud services.
