Power AI models by capturing, transforming, and delivering real-time data
Benefits
- Pave the way for informed decision-making and data-driven insights
- Capture, transform, and cleanse data for model ingest
- Refine raw ML data and securely store it in Google Cloud Storage (GCS)
Striim’s unified data streaming platform empowers organizations to infuse real-time data into AI, analytics, customer experiences and operations. In this blog post, we’ll delve into how Striim’s real-time ingestion and transformation capabilities can be leveraged to refine raw ML data and securely store it in Google Cloud Storage (GCS). This guide will walk you through the steps needed to create a data pipeline that refines and enriches data before storing it in GCS for further analysis and training.
Prerequisite: Before we embark on our data transformation journey, ensure you have a running instance of Striim and access to its console.
Striim Developer: https://signup-developer.striim.com/
Step-by-Step Guide: Transforming Raw ML Data with Striim
The transformation pipeline consists of four key components, each performing a critical role in reading the incoming data, and enabling the transformation of raw into refined ML data. However, prior to creating the Striim pipeline, we will begin by examining the ML Postgres table that serves as the data repository.
Iris Dataset Table:
Table "dms_sample.iris_dataset"
id | integer |
sepal_length | integer |
sepal_width | integer |
petal_length | integer |
petal_width | integer |
species | text |
This table is named “iris_dataset”, and it contains information about various characteristics of iris species, like sepal length, sepal width, petal width, and petal length. These are the measurements of the iris plants. The purpose of collecting this information is to use it later to train a classification model and accurately categorize different types of iris species. Unfortunately, the application responsible for ingesting these records into the “iris_dataset” table contains NULL values and provides species codes rather than species names. For example:
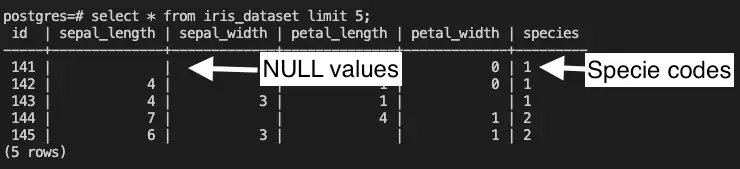
In this scenario, Striim is used for real-time data transformation from the ‘iris_dataset’ table. This involves replacing NULL values with 0 and mapping species codes to their respective names. After this cleansing process, the data is formatted into Delimited Separated Values (DSV), securely stored in GCS, and used to train a classification model, such as a Random Forest Classification Model. This model’s main goal is to predict iris species based on the provided characteristics.
Now that we have a clear understanding of the overall use case, we can proceed to creating our data pipeline within Striim.
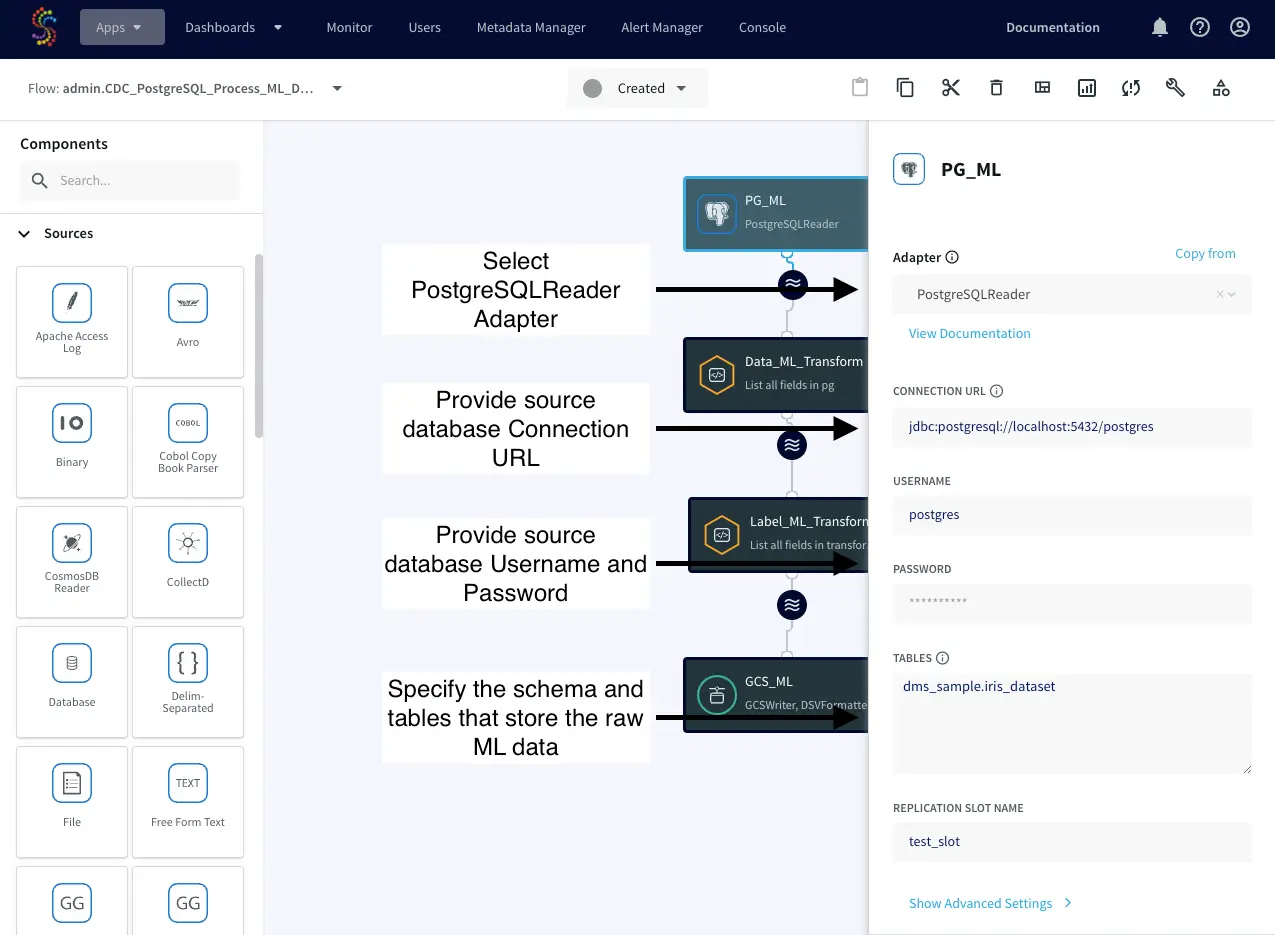
Component 1: PostgreSQL Reader
Start by creating a PostgreSQL Reader in Striim. This component establishes a connection to the source PostgreSQL database, capturing real-time data as it’s generated using Striim’s log-based Change Data Capture (CDC) technology.
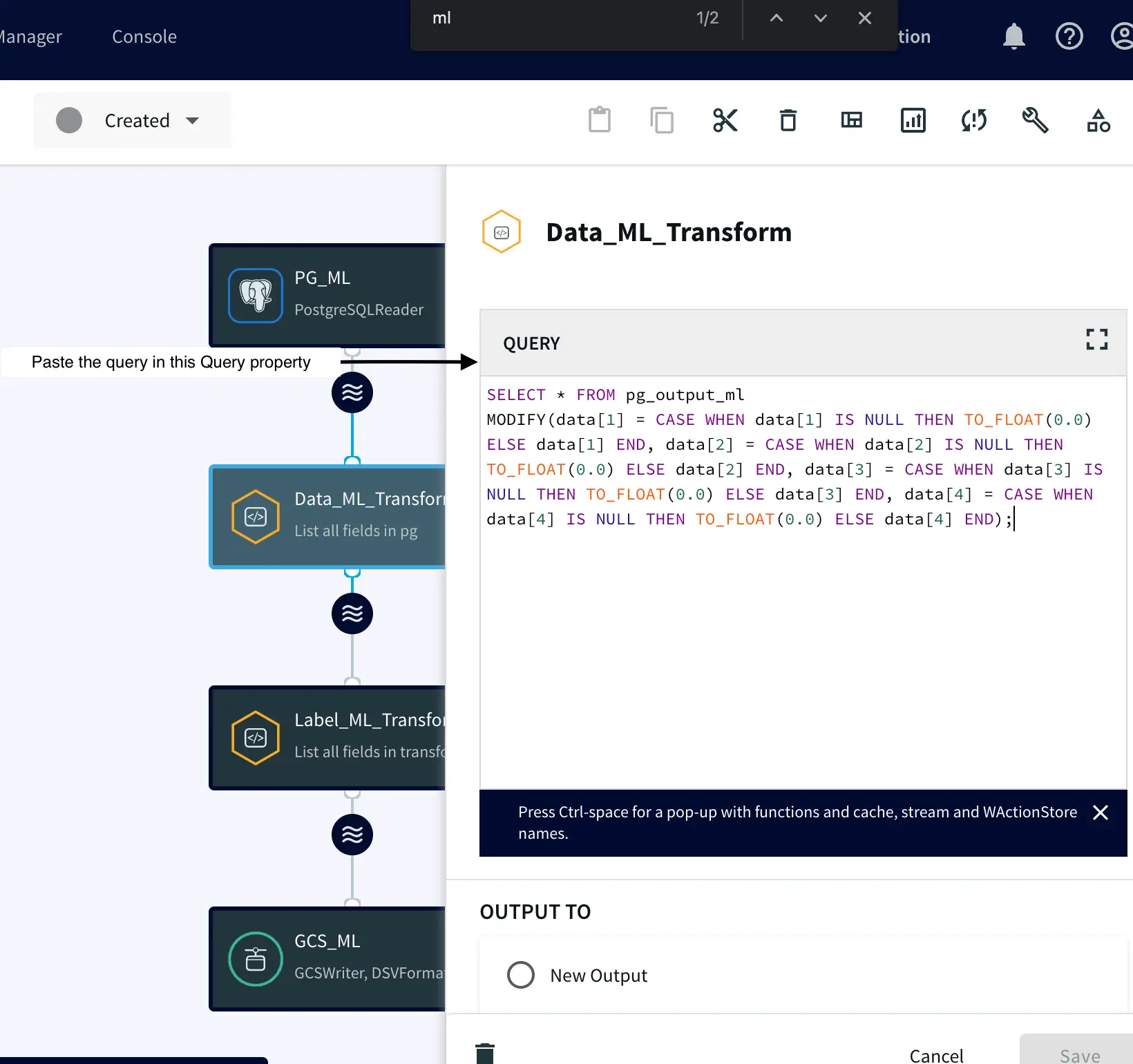
Component 2: Continuous Query – Replacing NULL Values
Attach a Continuous Query to the PostgreSQL Reader. This step involves writing a query that replaces any NULL values in the data with ‘0’.
SELECT * FROM pg_output_ml MODIFY( data[1] = CASE WHEN data[1] IS NULL THEN TO_FLOAT(0.0) ELSE data[1] END, data[2] = CASE WHEN data[2] IS NULL THEN TO_FLOAT(0.0) ELSE data[2] END, data[3] = CASE WHEN data[3] IS NULL THEN TO_FLOAT(0.0) ELSE data[3] END, data[4] = CASE WHEN data[4] IS NULL THEN TO_FLOAT(0.0) ELSE data[4] END);
This code retrieves raw data from the “pg_output_ml” output/stream and replaces any NULL values in the specified columns (sepal_length, sepal_width, petal_length, petal_width) with 0, while retaining the original values for non-NULL entries using the MODIFY Striim function. More information: Click Here
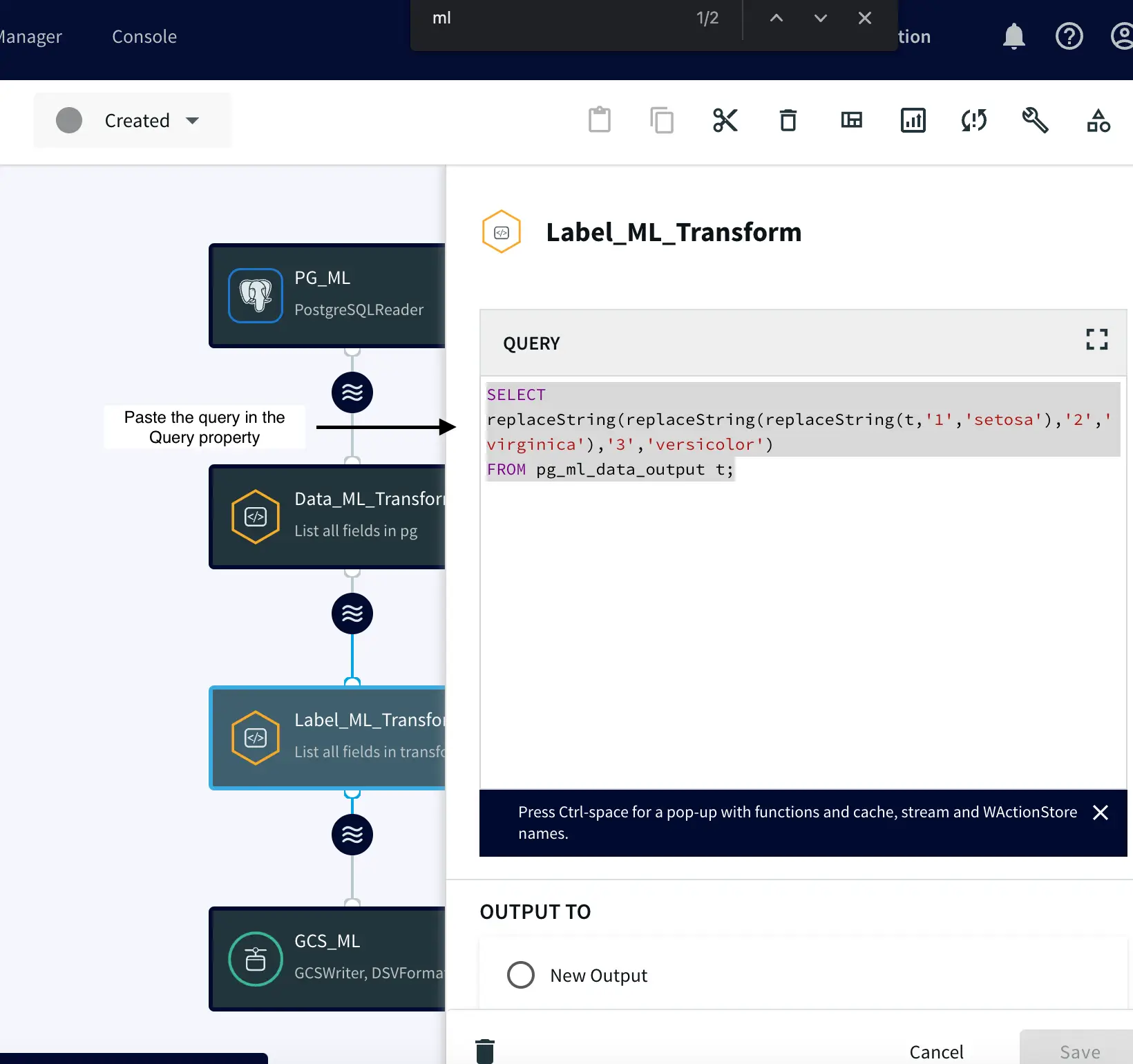
Component 3: Label Transformation
After transforming our data as explained earlier, we proceed to create an additional Continuous Query. This query is pivotal—it replaces numeric labels (1, 2, 3) in the dataset with their corresponding iris species names: setosa, versicolor, and virginica. The labels “setosa,” “versicolor,” and “virginica” are used to denote different iris flower types. This change serves two essential purposes. Firstly, it makes the dataset easier to understand, helping users and stakeholders in intuitively comprehending the data and engaging with model outputs. Secondly, this transformation significantly enhances machine learning model training. By using familiar iris species names instead of numeric codes, models can adeptly capture species distinctions, leading to improved pattern recognition and generalization.
SELECT replaceString(replaceString( replaceString(t,'1','setosa'),'2','virginica'),'3','versicolor') FROM pg_ml_data_output t;
Within this query, we leverage Striim’s replaceString function to seamlessly replace any iris code with its corresponding actual name. More information: https://www.striim.com/docs/en/modifying-the-waevent-data-array-using-replace-functions.html
Component 4: Storing in GCS
Lastly, attach a GCS Writer to the previous step’s output/stream. Configure this component to store the transformed data as a DSV file in your designated GCS bucket. What’s more, the UPLOAD POLICY ensures that a new DSV file is generated either after capturing 10,000 events or every five seconds.
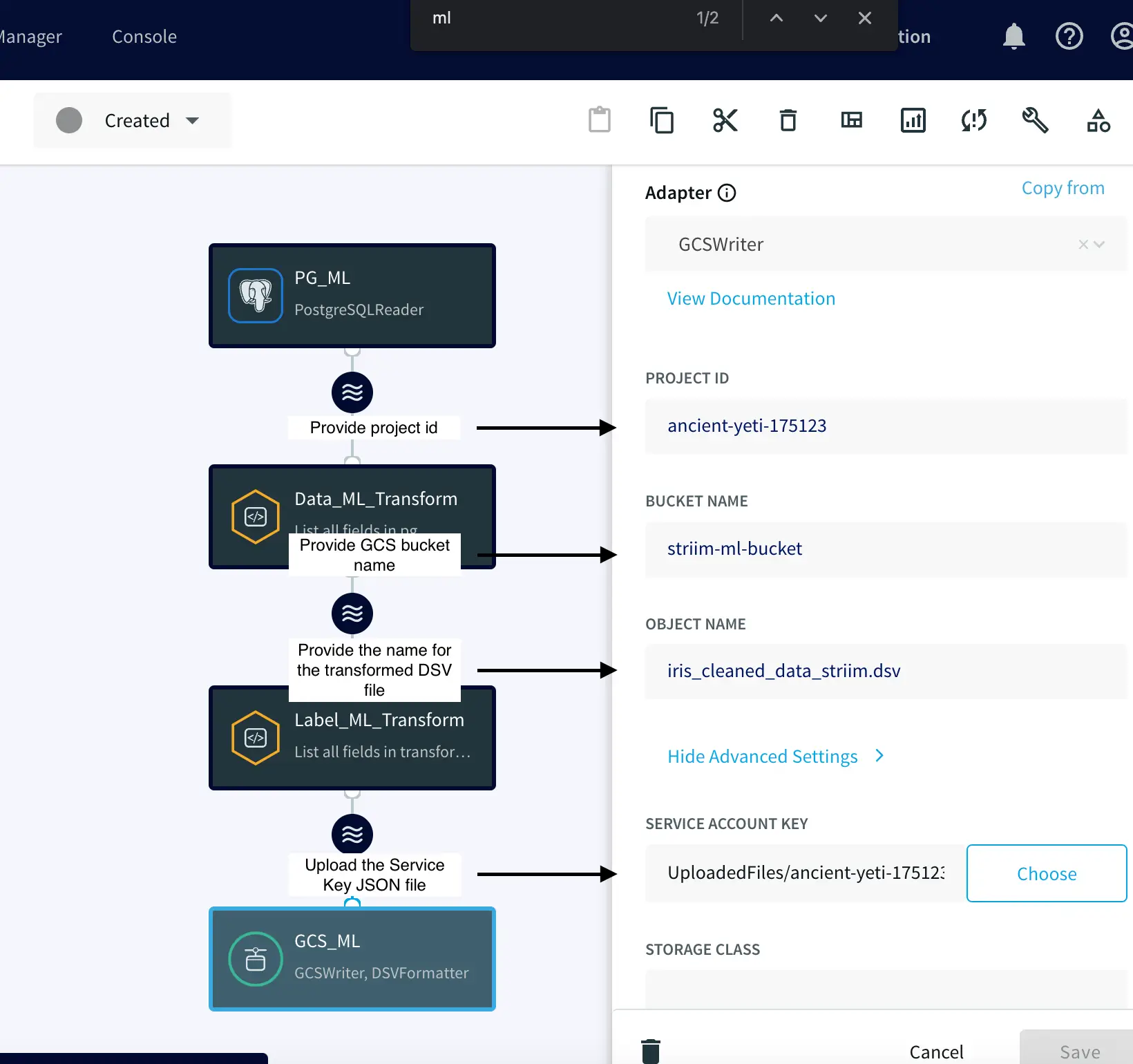
After creating the pipeline, we can proceed to deploy and start it.
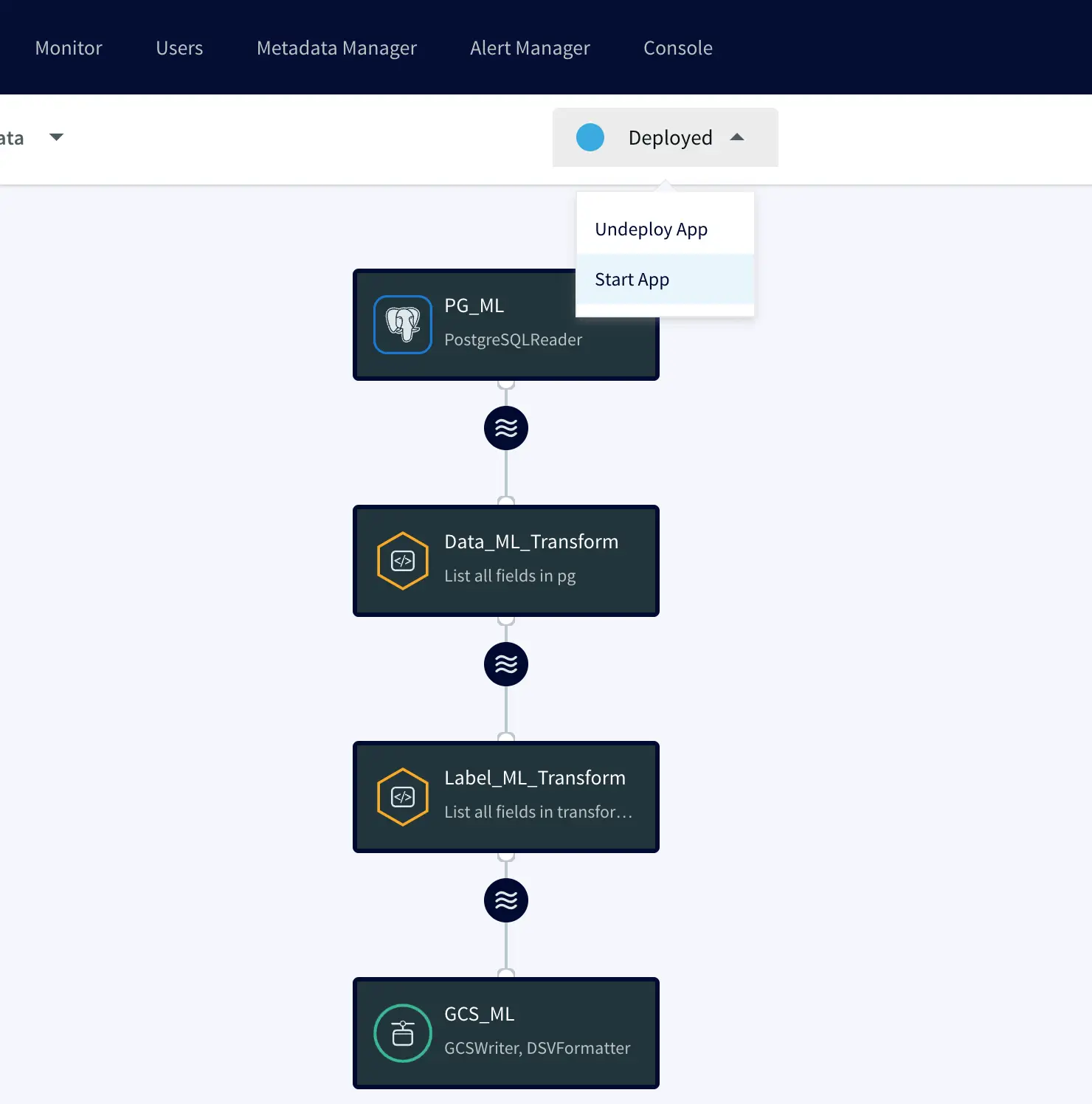
Right after that, Striim began capturing new data in real-time and transforming it on-the-fly:
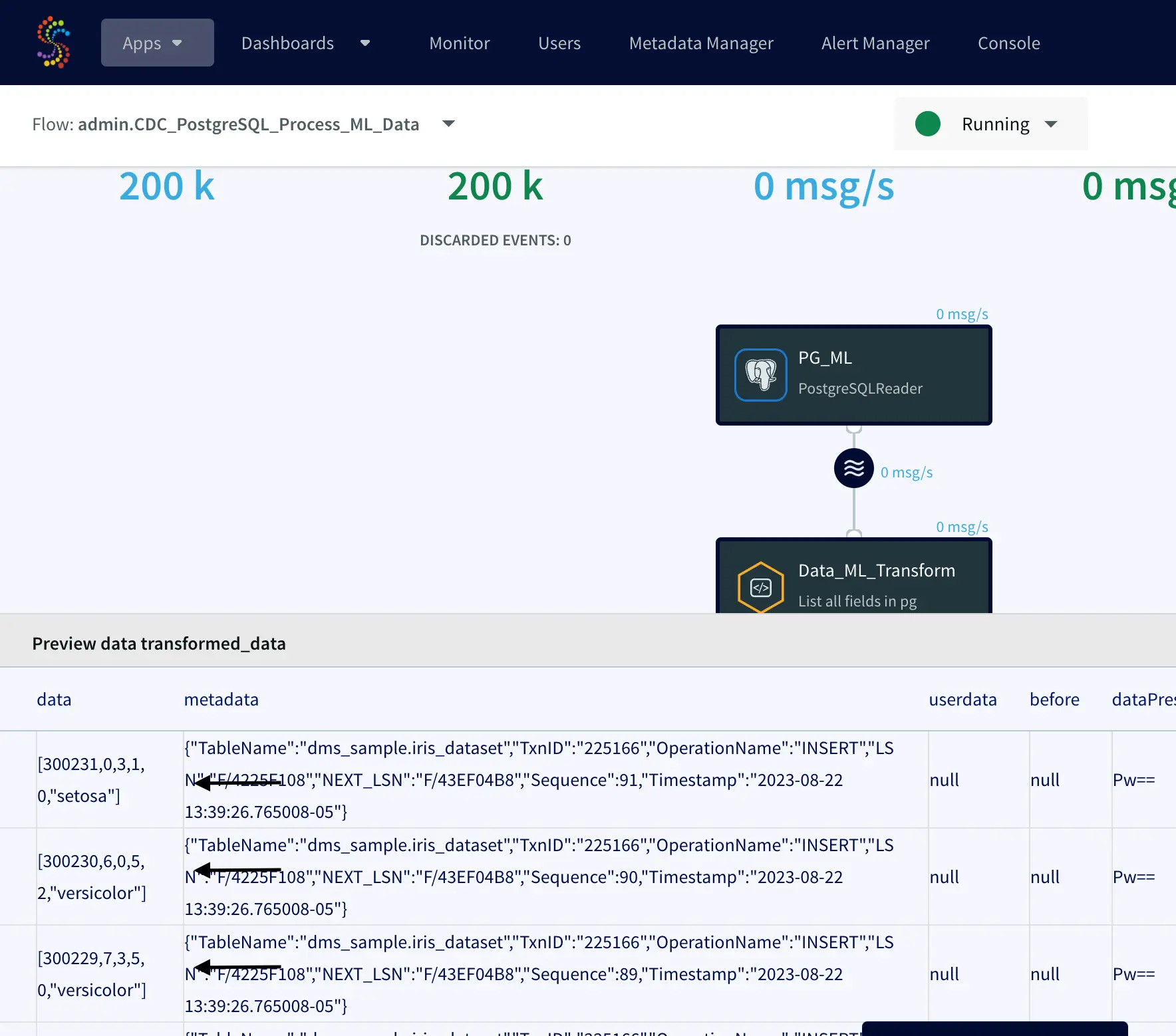
In the screenshot above, we’re previewing the cleaned data and observing how Striim is transforming NULL values to ‘0’ and converting all the iris species codes to their respective names.
Since the Total Input and Total Output values match, it indicates that Striim has successfully generated files in our GCS bucket (striim-ml-bucket). Now, let’s proceed to your Google Cloud Storage account and locate the bucket.
Step 4: Verification and Visualization
Within the bucket, you’ll find the DSV files created by the GCS Writer.
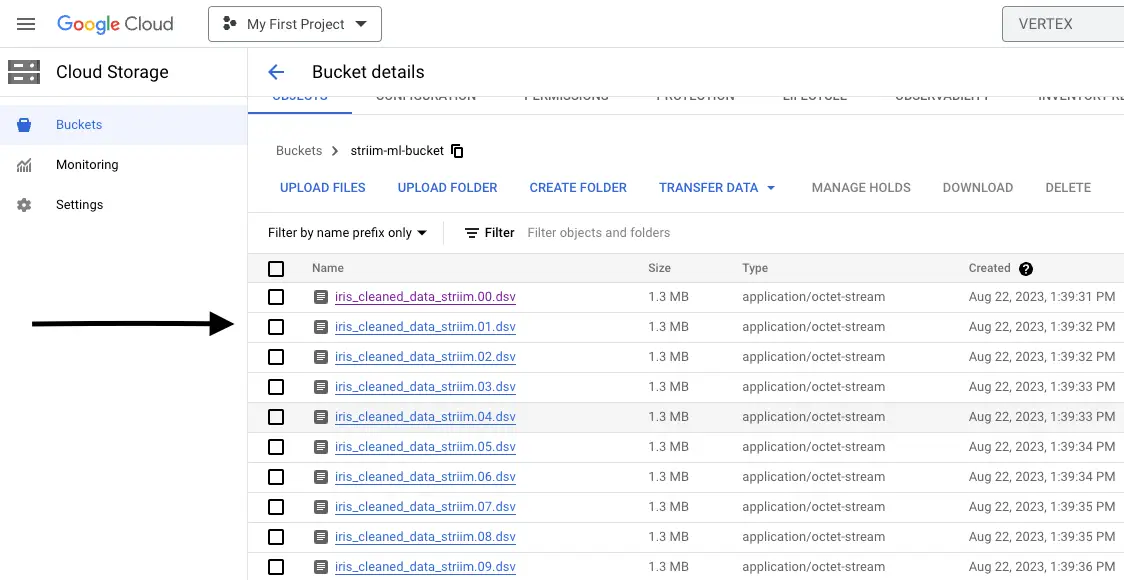
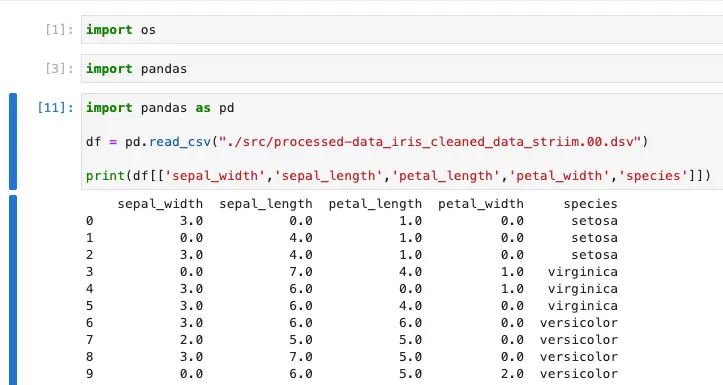
To verify the contents, we’ll leverage the power of Vertex AI and the Pandas Python library. Upload the DSV file to the JupyterLab instance, load the DSV file using Pandas, and explore its contents. This verification step ensures that the transformations have been successfully carried out, paving the way for subsequent machine learning training and analyses.
Conclusion: Transforming Possibilities with Striim and GCS
Striim’s real-time capabilities open doors to limitless possibilities in data transformation. Constructing a streamlined pipeline that captures, cleanses, and enriches data paves the way for Generative AI and machine learning. For additional details regarding Striim and its data processing capabilities, please refer to:
Striim Cloud product information page: https://www.striim.com/product/striim-cloud/
Striim Continuous Query documentation: https://www.striim.com/docs/en/create-cq–query-.html
Striim Open Processor documentation: https://www.striim.com/docs/platform/en/using-striim-open-processors.html

