A guide on when real-time data pipelines are the most reliable way to keep production databases and warehouses in sync.

Photo by American Public Power Association on Unsplash
Co-written with John Kutay of Striim
Data warehouses emerged after analytics teams slowed down the production database one too many times. Analytical workloads aren’t meant for transactional databases, which are optimized for high latency reads, writes, and data integrity. Similarly, there’s a reason production applications are run on transactional databases.
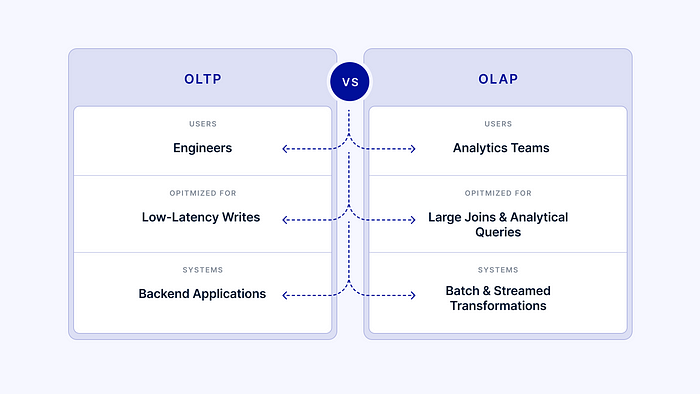
Definition: Transactional (OLTP) data stores are databases that keep ACID (atomicity, consistency, isolation, and durability) properties in a transaction. Examples include PostgreSQL and MySQL, which scale to 20 thousand transactions per second.
Analytics teams aren’t quite so concerned with inserting 20 thousand rows in the span of a second — instead, they want to join, filter, and transform tables to get insights from data. Data warehouses optimize for precisely this using OLAP.
Definition: OLAP (online analytical processing) databases optimize for multidimensional analyses on large volumes of data. Examples included popular data warehouses like Snowflake, Redshift, and BigQuery.
Different teams, different needs, different databases. The question remains: if analytics teams use OLAP data warehouses, how do they get populated?
Use CDC to improve data SLAs
Let’s back up a step. A few examples of areas analytics teams own:
- Customer segmentation data, sent to third party tools to optimize business functions like marketing and customer support
- Fraud detection, to alert on suspicious behavior on the product
If these analyses are run on top of a data warehouse, the baseline amount of data required in the warehouse is just from the production database. Supplemental data from third party tools is very helpful but not usually where analytics teams start. The first approach usually considered when moving data from a database to a data warehouse is batch based.
Definition: Batch process data pipelines involve checking the source database on scheduled intervals and running the pipeline to update data in the target (usually a warehouse).
There are technical difficulties with this approach, most notably the logic required to know what has changed in the source and what needs to be updated in the target. Batch ELT tools have really taken this burden off of data professionals. No batch ELT tool, however, has solved for the biggest caveat of them all: data SLAs. Consider a data pipeline that runs every three hours. Any pipelines that run independently on top of that data, even if running every three hours as well, would in the worst case scenario be six hours out of date. For many analyses, the six hour delay doesn’t move the needle. This begs the question: when should teams care about data freshness and SLAs?
Definition: An SLA (service level agreement) is a contract between a vendor and its customers as to what they can expect from the vendor when it comes to application availability and downtime. A data SLA is an agreement between the analytics team and its stakeholders around how fresh the data is expected to be.
When fresh data makes a meaningful impact on the business, that’s when teams should care. Going back to the examples of analytics team projects, if a fraudulent event happens (like hundreds of fraudulent orders) time is of the essence. A data SLA of 3 hours could be what causes the business to lose thousands of dollars instead of less than $100.
When freshness can’t wait — cue CDC, or change data capture. CDC tools read change logs on databases and mimic those changes in the target data. This happens fairly immediately, with easy reruns if a data pipeline encounters errors.
With live change logs, CDC tools keep two data stores (a production database and analytics warehouse) identical in near-realtime. The analytics team is then running analyses on data fresh as a daisy.
Getting started with CDC
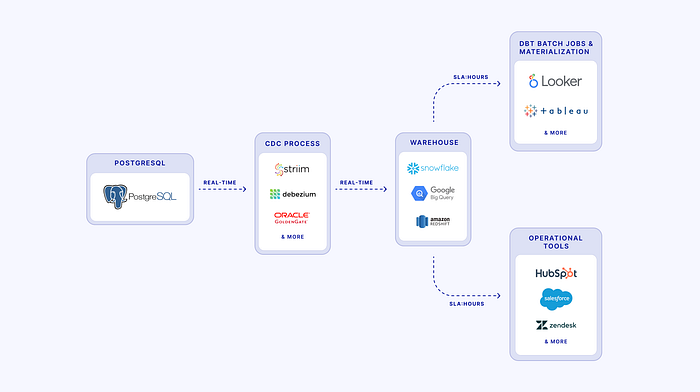
The most common production transactional databases are PostgreSQL and MySQL, which have both been around for decades. Being targets more often than sources, warehouses don’t usually support CDC in the same way (although even this is changing).
To set up a source database for CDC, you need to:
- Make sure WAL (write-ahead) logs are enabled and the WAL timeout is high enough. This occurs in database settings directly.
- Make sure archive logs are stored on the source based on the CDC tool’s current specifications.
- Create a replication slot, where a CDC tool can subscribe to change logs.
- Monitor source and target database infrastructure to ensure neither is overloaded.
On the source database, if a row of data changes to A, then to value B, then to A, this behavior is replayed on the target warehouse. The replay ensures data integrity and consistency.
While open source CDC solutions like Debezium exist, hosted CDC solutions allow users to worry less about infrastructure and more about the business specifications of the pipeline, unique to their business.
As a consultant in analytics & go-to-market for dev-tools, I was previously leading the data engineering function at Perpay and built out a change data capture stack. From my perspective, change data capture isn’t just about real-time analytics. It’s simply the most reliable and scalable way to copy data from an operational database to analytical systems especially when downstream latency requirements are at play.


