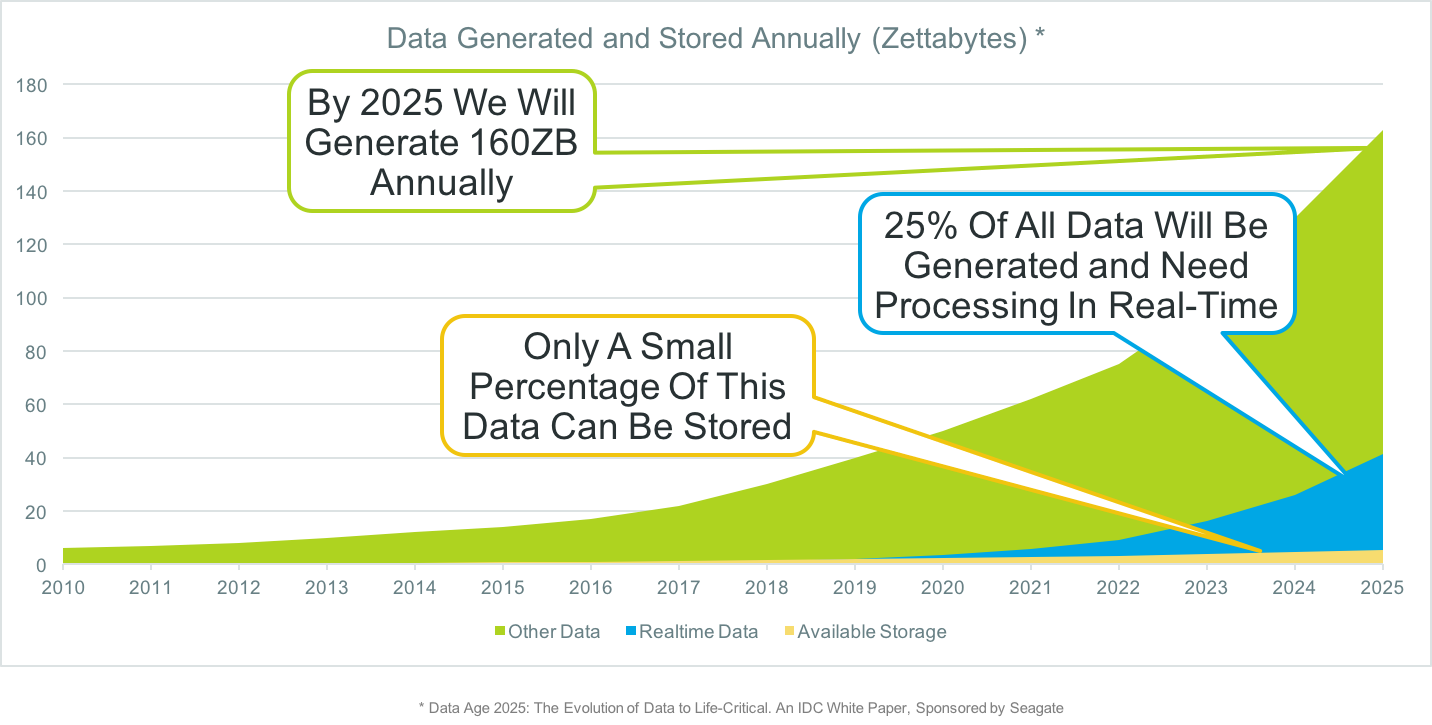
 In a recent contributed article for RTInsights, The Rise of Real-Time Data: Prepare for Exponential Growth, I explained how the predicted huge increase in data sources and data volumes will impact the way we need to think about data.
In a recent contributed article for RTInsights, The Rise of Real-Time Data: Prepare for Exponential Growth, I explained how the predicted huge increase in data sources and data volumes will impact the way we need to think about data.
The key takeaway is that, if we can’t possibly store all the data being generated, “the only logical conclusion is that it must be collected, processed and analyzed in-memory, in real-time, close to where the data is generated.”
The article explains general concepts, but doesn’t go into details of how this can be achieved in a practical sense. The purpose of this post is to dive deeper by showing how Striim can be utilized for data modernization tasks, and help companies handle the oncoming tsunami of data.
The first thing to understand is that Striim is a complete end-to-end, in-memory platform. This means that we do not store data first and analyze it afterwards. Using one of our many collectors to ingest data as it’s being generated, you are fully in the streaming world. All of our processing, enrichment, and analysis is performed in-memory using arbitrarily complex data flows.
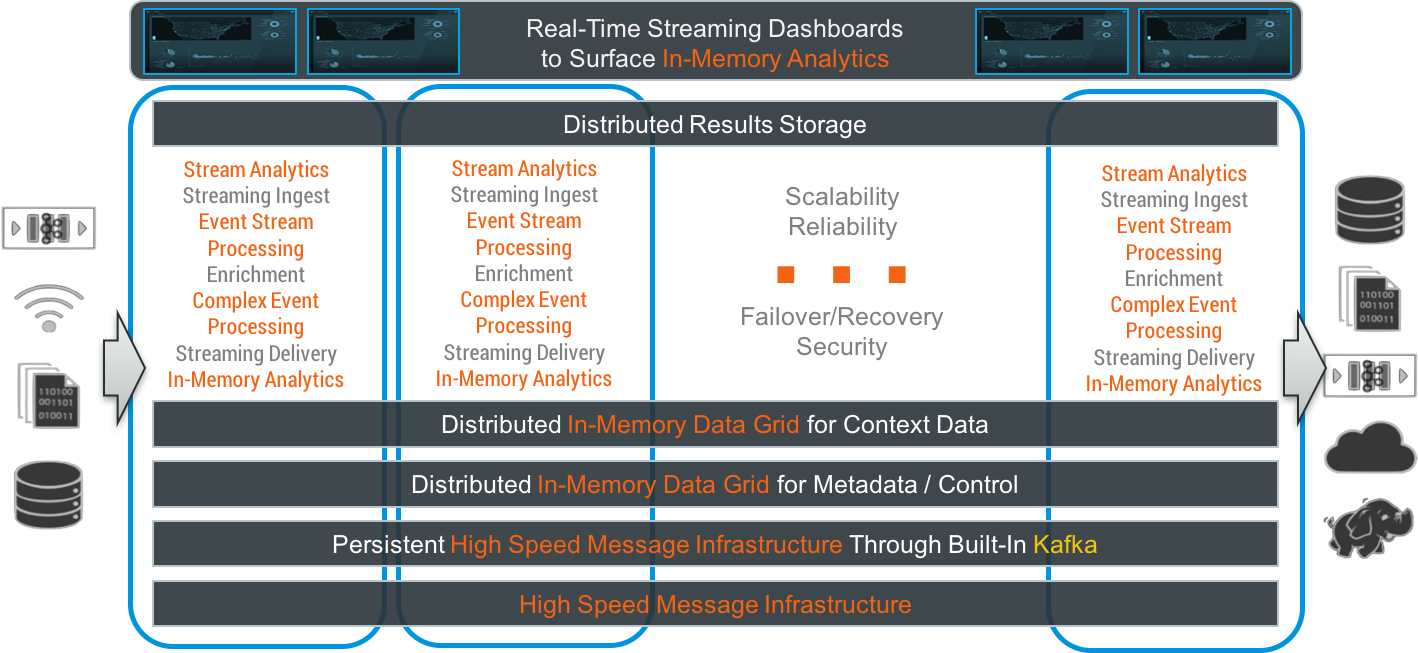
This diagram shows how Striim combines multiple, previously separate, in-memory components to provide an easy-to-use platform – a new breed of middleware – that only requires knowledge of SQL to be productive.
It is the use of SQL that makes filtering, transformation, aggregation and enrichment of data so easy. Almost all developers, business analysis and data scientists know SQL, and through our time-series extensions, windows and complex event processing syntax, it’s quite simple to do all of these things.
Let’s start with something easy first – filtering. Anyone that knows SQL will recognize immediately that filtering is done with a WHERE clause. Our platform is no different. Here’s an example piece of a large data flow that analyzes web and application activity for SLA monitoring purposes.
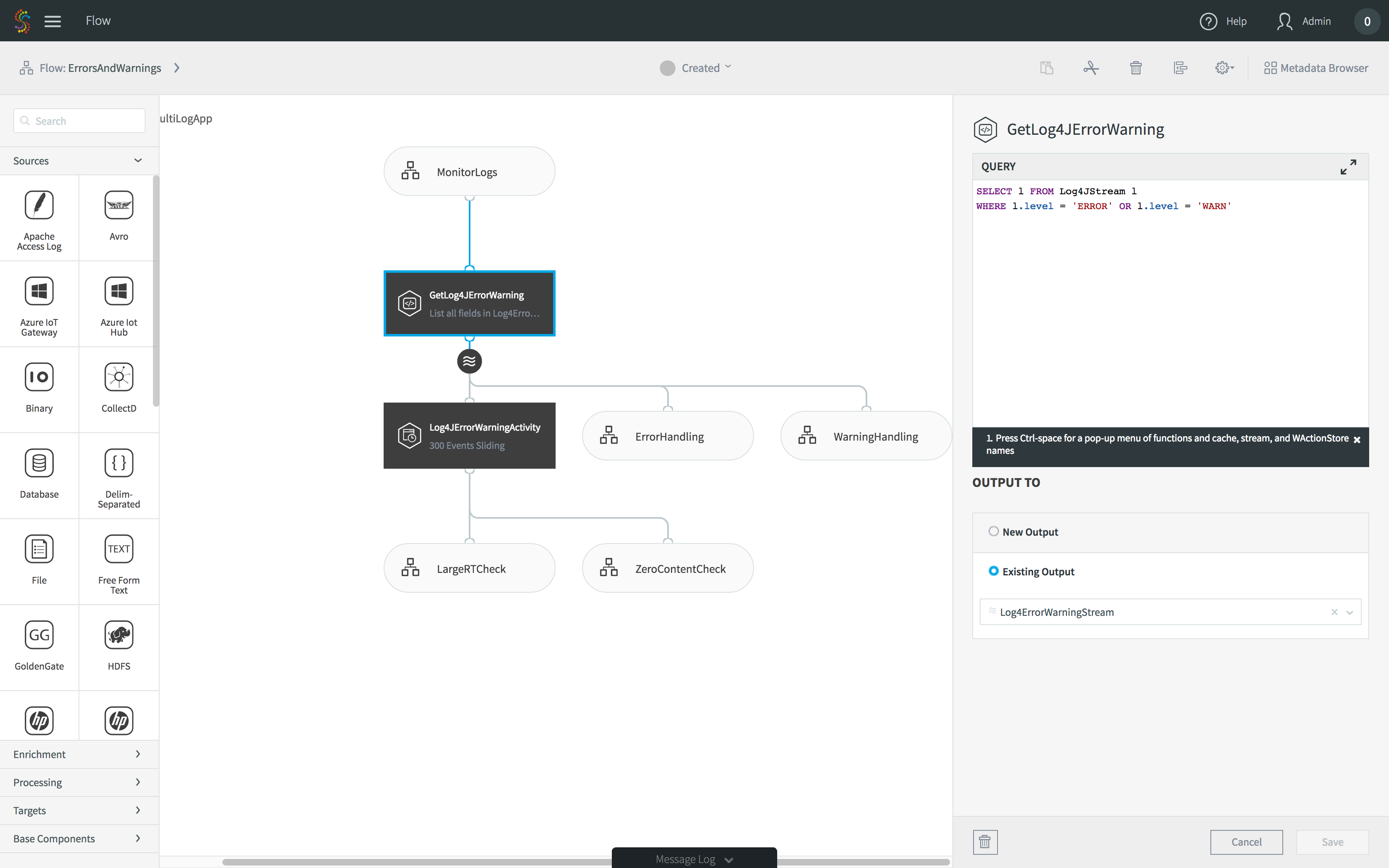
The application contains many parts, but this aspect of the data flow is really simple. The source is a real-time feed from Log4J files. In this data flow, we only care about the errors and warnings, so we need to filter out everything but them. The highlighted query does just that. Only Log4J entries with status ERROR or WARN will make it to the next stage of the processing.
If you have hundreds of servers generating files, you don’t need the excess traffic and storage for the unwanted entries; they can be filtered at the edge.
Aggregation is similarly obvious to anyone that knows SQL – you use aggregate functions and GROUP BY. However, for streaming real-time data you need to add in an additional concept – windows. You can’t simply aggregate data on a stream because it is inherently unbounded and continuous. Any aggregate would just keep on increasing forever. You need to set bounds, and this is where windows come in.
and GROUP BY. However, for streaming real-time data you need to add in an additional concept – windows. You can’t simply aggregate data on a stream because it is inherently unbounded and continuous. Any aggregate would just keep on increasing forever. You need to set bounds, and this is where windows come in.
In this example on the right, we have a 10-second window of sensor data, and we will output new aggregates for each sensor whenever the window changes.
This query could then be used to detect anomalous behavior, based on values jumping two standard deviations up or down, or extended to calculate other statistical functions.
The final basic concept to understand is enrichment – this is akin to a JOIN in SQL, but has been optimized to function for streaming real-time data. Key to this is the converged in-memory architecture and Striim’s inclusion of a built-in In-Memory Data Grid. Striim’s clustered architecture has been designed specifically to enable large amounts of data to be loaded in distributed caches, and joined with streaming data without slowing down the data flow. Customers have loaded tens of millions of records into memory, and still maintained very high throughput and low latency in their applications.
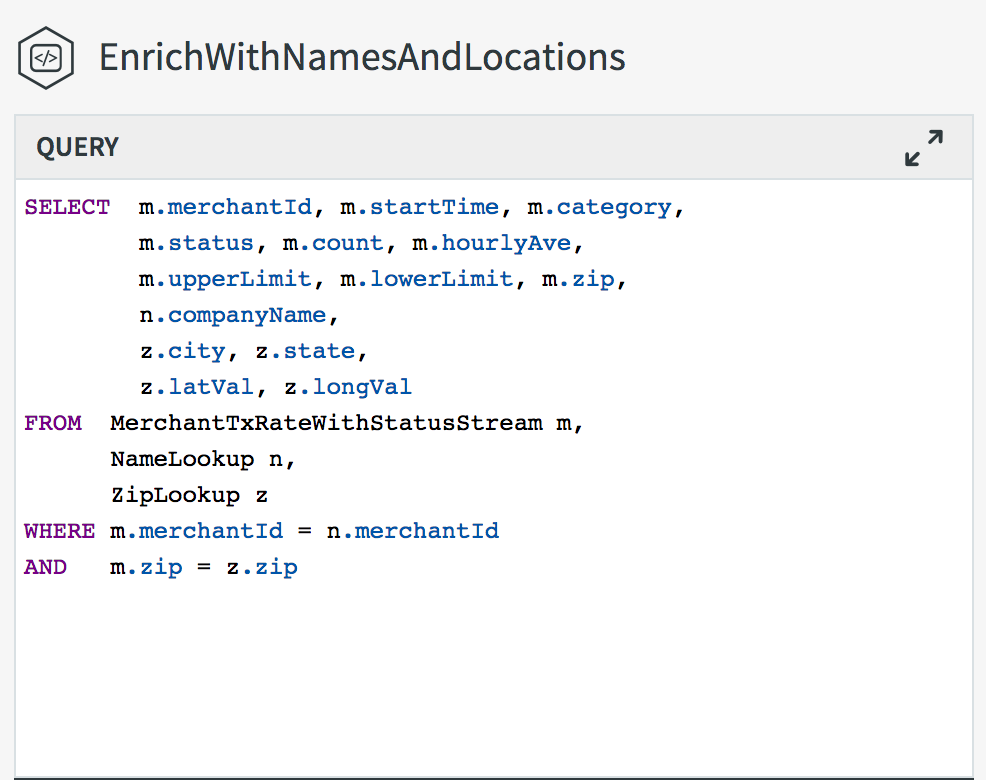 The example on the left is taken from one of our sample applications. Data is coming from point of sale machines, and has already been aggregated by merchant by the time it reaches this query.
The example on the left is taken from one of our sample applications. Data is coming from point of sale machines, and has already been aggregated by merchant by the time it reaches this query.
Here we are joining with address information that includes a latitude and longitude, and merchant data to enrich the original record.
Previously, we only had the merchant id to work with, without any further meaning. Having this additional context makes the data more understandable, and enhances our ability to perform analytics.
While these things are important for streaming integration of enterprise data, they are essential in the world of IoT. But, as I mentioned in my previous blog post, Why Striim Is Repeatedly Recognized as the Best IoT Solution, IoT is not a single technology or market… it is an eco-system and does not belong in a silo. You need to think of IoT data as part of the corporate data assets, and increase its value by correlating with other enterprise data.
As the data volumes increase, more and more processing and analytics will be pushed to the edge, so it is important to consider a flexible architecture like Striim’s that enables applications to be split between the edge, on-premise and the cloud.
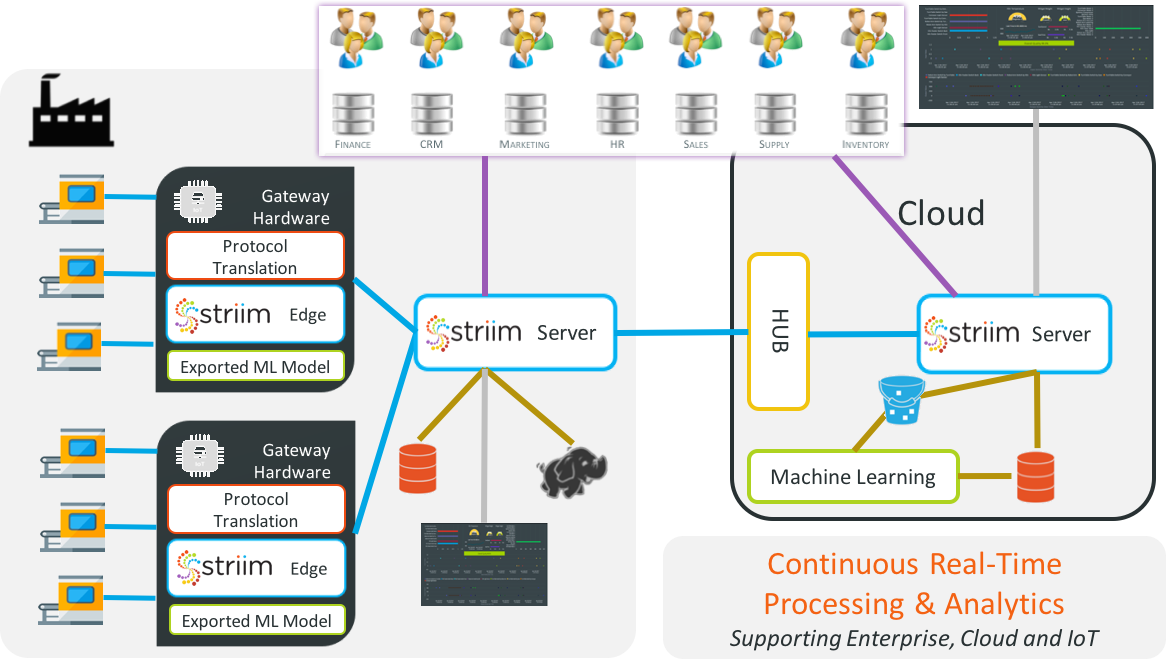
So how can Striim help you prepare for exponential growth in data volumes? You can start by transitioning, use-case by use-case, to a streaming-first architecture, collecting data in real-time rather than batches. This will ensure that data flows are continuous and predictable. As the data volumes increase, collection, processing and analytics can all be scaled by adding more edge, on-premise, and cloud servers. Over time, more and more processing and analytics is handled in real-time, and the tsunami of data becomes something you have planned for and can manage.


