Striim is a real-time data integration platform that integrates with over 100 data sources and targets, including Google BigQuery. In this post, we’ll share how Striim’s new partition pruning feature can help BigQuery users optimize their query costs and performance.
- How Striim Writes Data to Data Warehouses
- What are BigQuery Partitioned Tables?
- How BigQuery Partitioned Tables Reduce Query Costs (and Improve Query Performance) in BigQuery
- NEW: Striim’s BigQuery Writer Now Supports BigQuery Partition Pruning
How Striim Writes Data to Data Warehouses
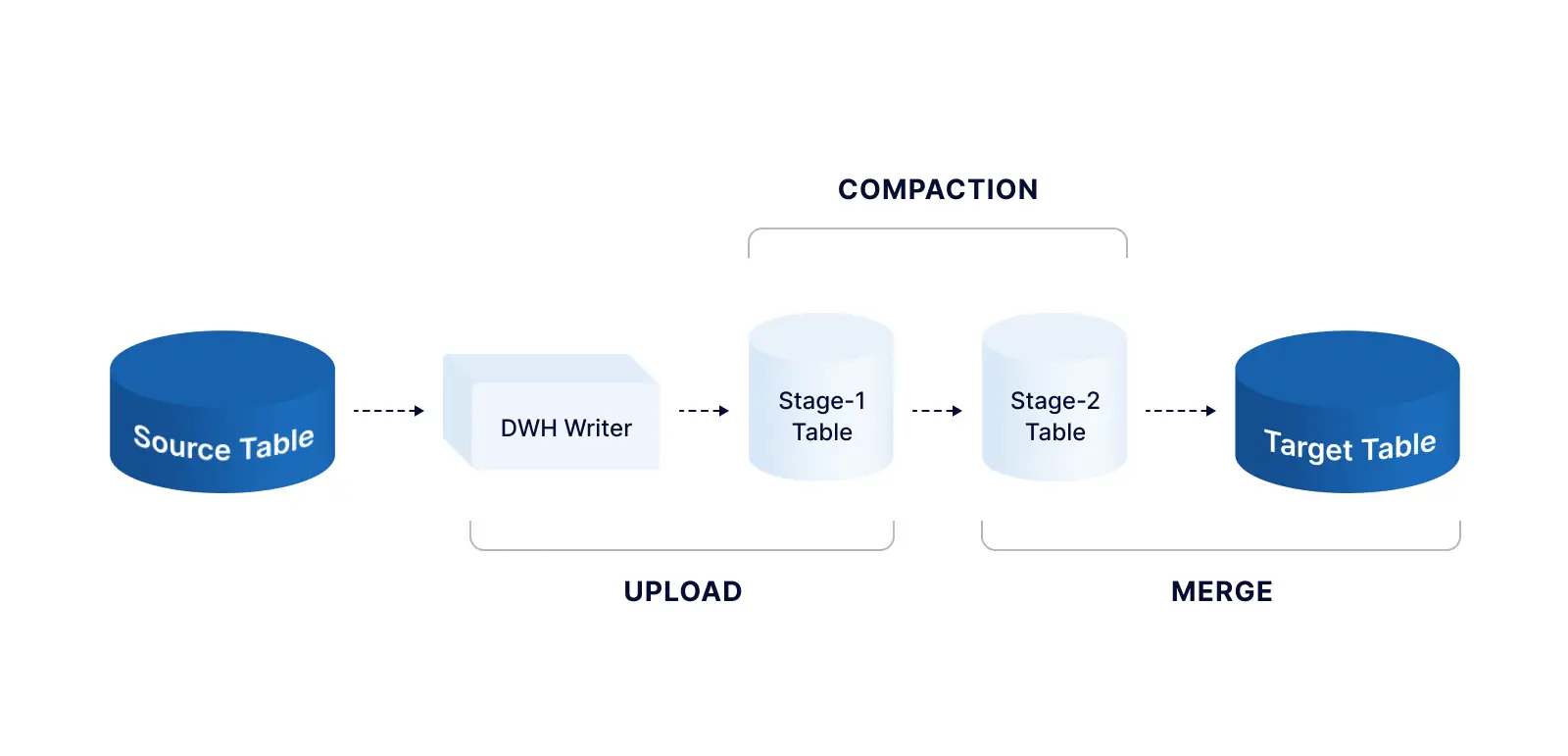
Striim ingests data from a range of data sources including databases, files/logs, messaging systems, IoT devices, and data warehouses. BigQuery is a popular data target used by companies to efficiently analyze large datasets. Striim moves data into BigQuery in three steps when using the MERGE mode (which allows users to combine updates, inserts, deletes into a single statement):
- Upload from source table to stage-1 table
- Compact by moving only the most recent snapshot of each record to the stage-2 table
- Merge from stage-2 table to the target table in BigQuery
In step 3 (Merge), the MERGE query has to scan the entire table to search for matching records and update (or delete) them, or insert a new record if one doesn’t already exist. However, scanning through an entire table is both costly and time-consuming.
What are Partitioned Tables?
Partitioned tables are tables that have been divided into segments. Table partitioning enables users to improve query performance and optimize their costs.
For example, the diagram below depicts an integer-range partitioned table where the target table is partitioned according to User ID values (integers). Partition 1 contains the records with User IDs 1-5, partition 2 contains User IDs 6-10, and so on.
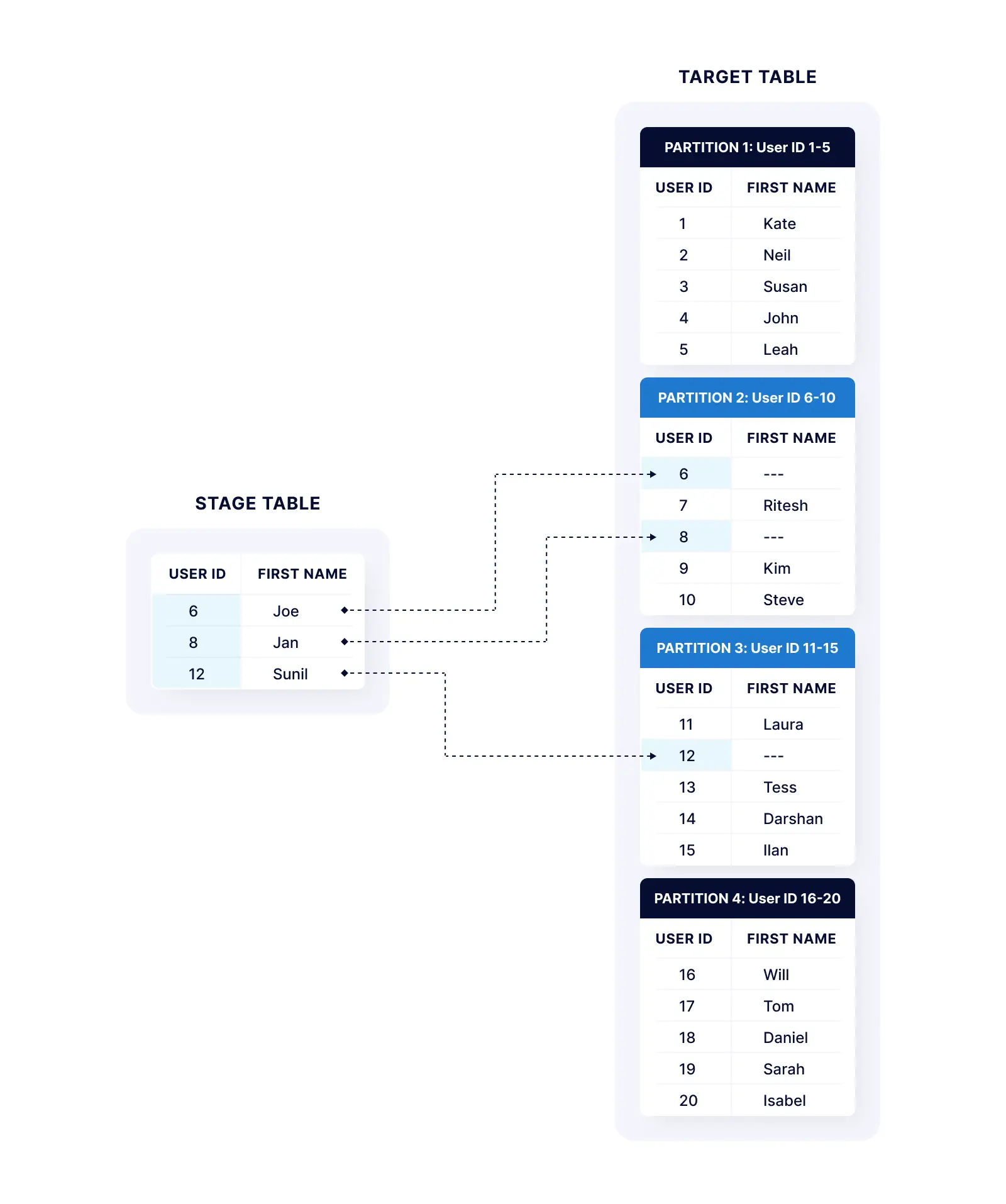
In this example, a user wants to update three customer records with their first names. Partitioned tables allow the user to denote the partition(s) to be searched (also known as partition pruning). Without table partitioning, the user would need to search the full table to locate and update the corresponding records. With table partitioning, the records that need to be updated with user names are located in partitions 2 and 3, so only those partitions need to be searched.
How BigQuery Partitioned Tables Reduce Query Costs (and Improve Query Performance) in BigQuery
In BigQuery, tables can be partitioned by the following types of columns:
- TIMESTAMP, DATE, or DATETIME columns
- Integer-type columns (as shown in the example above)
- Ingestion time (virtual column) based on a timestamp from when BigQuery ingests data
BigQuery officially supports partition pruning when using a MERGE query with a filter in the merge_condition.
If you use a query to filter based on partition column value, BigQuery will only scan the partitions that match the filter values.
In the example below, the destination table is partitioned based on the “ID” column (the partitioning column). The MERGE query on the right includes a filter based on a range of the “ID” column values. The MERGE query on the left does not include a partition filter, which means that the full table will be scanned (resulting in 61.12 MB processed vs 4.01 MB processed).
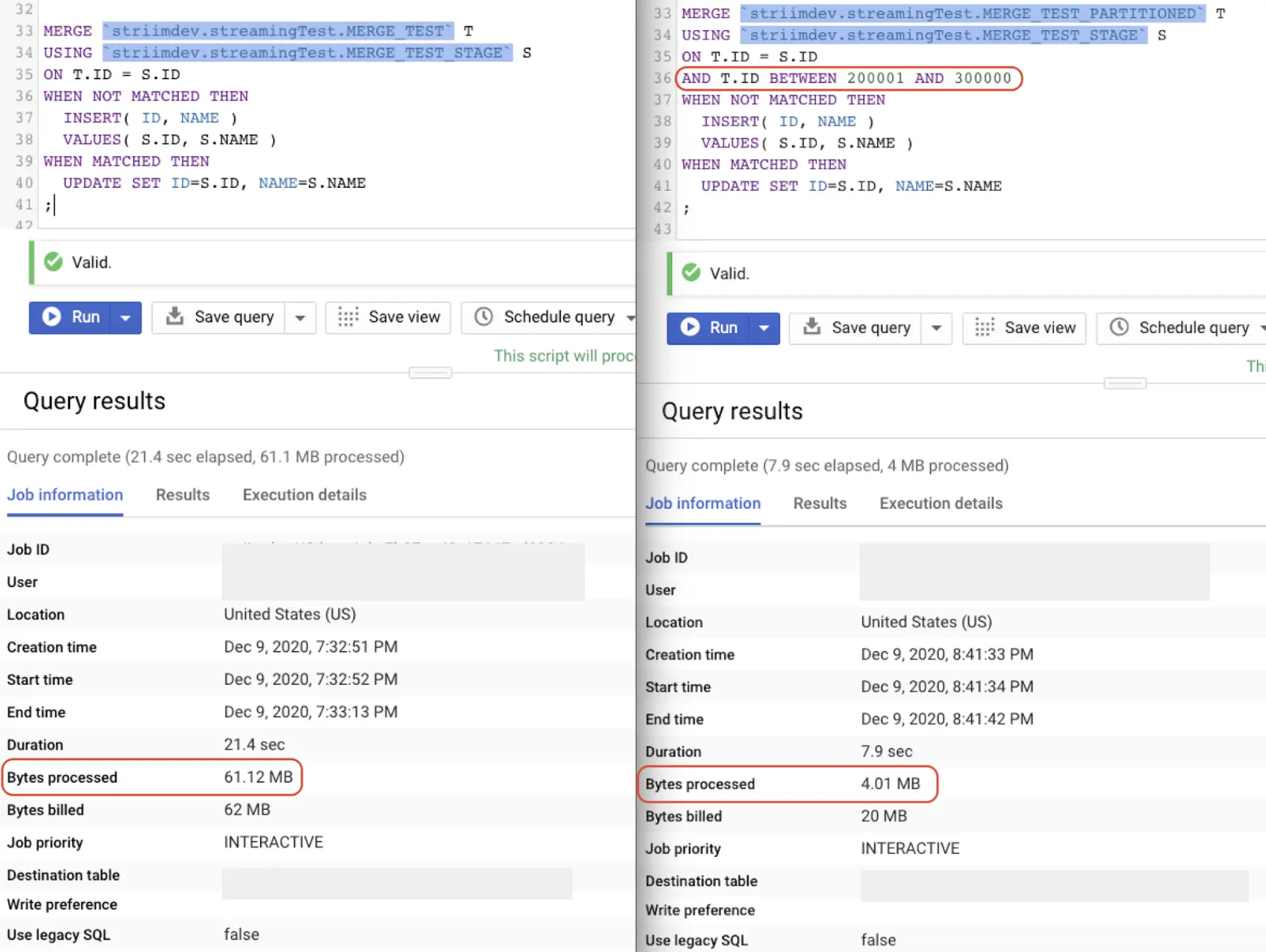
Even better, since partition pruning is performed before running the query, users can calculate their query costs ahead of time. This is especially compelling for users who take advantage of BigQuery’s on-demand pricing.
New: Striim’s BigQuery Writer Now Supports BigQuery Partition Pruning
Striim recently added support for partition pruning in BigQuery, so you can start optimizing your BigQuery performance and costs today. Ready to try this new feature? Make sure that a) the partitioning column in your source database has supplemental logging enabled and b) your target table in BigQuery is partitioned.
With this newly added functionality, Striim’s BigQuery Writer will detect the partitioned column and automatically optimize the merge without any user input. The optimized MERGE query will scan only the required partitions, resulting in faster query execution and lower costs.
Ready to see how Striim can help you make the most of BigQuery? Request a personalized demo of the Striim platform or start your free trial today!


