The AI era is upon us. For organizations at every level, it’s no longer a question of whether they should adopt an AI strategy, but how to do it. In the race for competitive advantage, building AI-enabled differentiation has become a board-level mandate.
Getting AI-Ready
The pressure to adopt AI is mounting; the opportunities, immense. But to seize the opportunities of the new age, companies need to take steps to become AI-ready.
What it means to be “AI-ready”:
AI readiness is defined as an organization’s ability to successfully adopt and scale artificial intelligence by meeting two essential requirements: first, a modern data and compute infrastructure with the governance, tools, and architecture needed to support the full AI lifecycle; second, the organizational foundation—through upskilling, leadership alignment, and change management—to enable responsible and effective use of AI across teams. Without both, AI initiatives are likely to stall, remain siloed, or fail to generate meaningful business value.
For the purpose of this guide, we’ll explore the first part of AI-readiness: technology. We’ll uncover what’s required to build a “modern AI stack”—a layered, scalable, and modular stack that supports the full lifecycle of AI. Then in part 2, we’ll dive deeper into the data layer—argubaly the most critical element needed to power AI applications.
But first, let’s begin by unpacking what an AI stack is, why it’s necessary, and what makes up its five core layers.
What is a Modern AI Stack?
A “modern AI stack” is a layered, flexible system designed to support the entire AI lifecycle—from collecting and transforming data, to training and serving models, to monitoring performance and ensuring compliance.
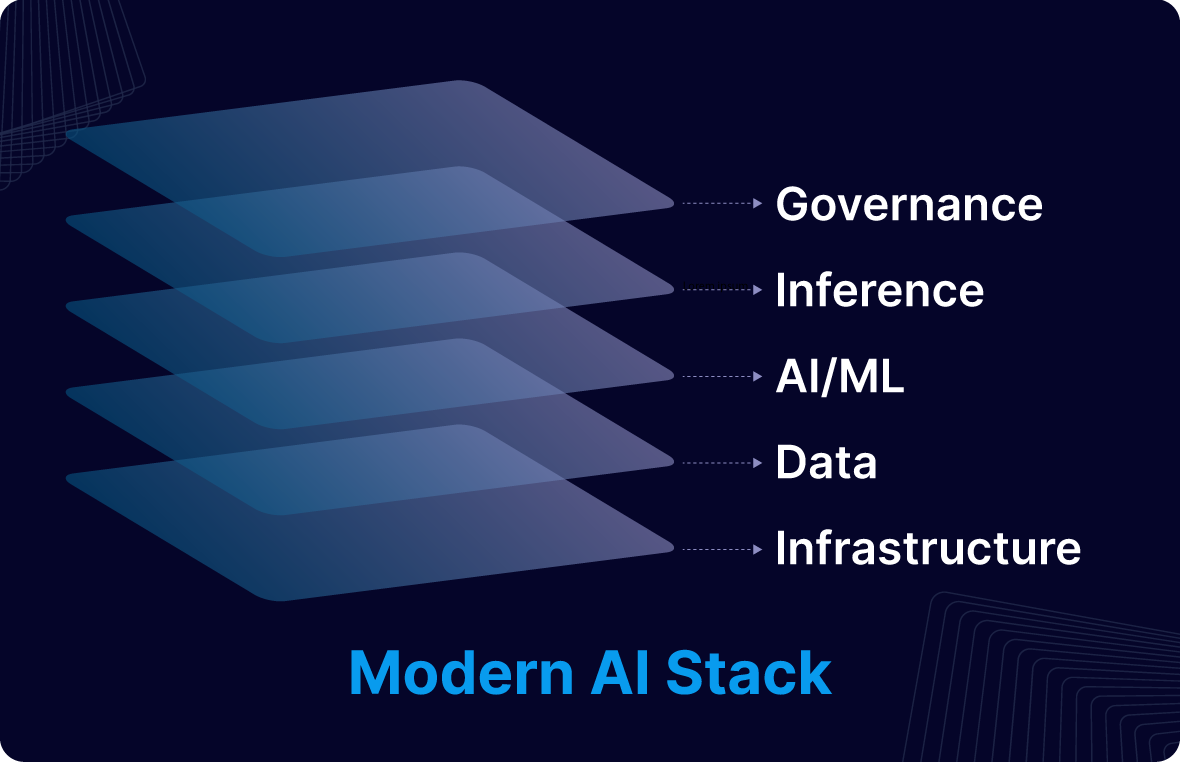
Each layer plays a critical role, from real-time data infrastructure to machine learning operations and governance tools. Together, they form an interconnected foundation that enables scalable, trustworthy, and production-grade AI.
Let’s break down the five foundational layers of the stack and their key components.
The Five Layers of the Modern AI Stack
The Infrastructure Layer

The infrastructure layer is the foundation of any modern AI stack. It’s responsible for delivering the compute power, orchestration, and network performance required to support today’s most demanding AI workloads. It enables everything above it, from real-time data ingestion to model inference and autonomous decisioning. And it must be built with one assumption: change is constant.
Flexibility, scalability are essential
The key considerations here are power, flexibility, and scalability. Start with power. AI workloads are compute-heavy and highly dynamic. Training large models, running inference at scale, and supporting agentic AI systems all demand significant, on-demand resources like GPUs and TPUs. This makes raw compute power a non-negotiable baseline.
Just as critical is flexibility. Data volumes surge. Inference demands spike. New models emerge quickly. A flexible infrastructure (cloud-native, containerized systems) lets teams adapt fast and offer the modularity and responsiveness required to stay agile.
Finally, infrastructure must scale seamlessly. Models evolve, pipelines shift, and teams experiment constantly. Scalable, composable infrastructure allows teams to retrain models, upgrade components, and roll out changes without risking production downtime or system instability.
Here’s a summary of what you need to know about the infrastructure layer.
- What it is: This is the foundational layer of your entire stack— the compute, orchestration, and networking fabric that all other parts of the AI stack depend on.
- Why it’s important: AI is computationally heavy, dynamic, and unpredictable. Your infrastructure needs to flex with it — scale up, scale down, distribute, and recover — seamlessly.
- Core requirements:
- A cloud-native, modular architecture that’s designed to evolve with your business needs and technical demands.
- Elastic compute with support for GPUs/TPUs to handle AI training and inference workloads.
- Built-in support for agentic AI frameworks capable of multi-step, autonomous reasoning.
- Infrastructure resiliency, including zero-downtime upgrades and self-healing orchestration.
Data Layer

Data is the fuel. This layer governs how data is collected, moved, shaped, and stored—both in motion and at rest—ensuring it’s available when and where AI systems need it. Without high-quality, real-time data flowing through a reliable platform, even the most powerful models can’t perform.
That’s why getting real-time, AI-ready data into a reliable, central platform is so crucial. (We’ll cover more on this layer, and how to select a reliable data platform in Part 2 of this series).
AI-ready data is timely, trusted, and accessible.
AI systems need constant access to the most current data to generate accurate and relevant outputs. Especially for real-time use cases such as models driving personalization, fraud detection, or operational intelligence. Even outside of these specific applications, fresh, real-time data is vital for all AI use cases. Stale data leads to inaccurate predictions, lost opportunities, or worse—unhappy customers.
Just as important as timeliness is trust. You can’t rely on AI applications driven by unreliable data—data that’s either incomplete, inconsistent (not following standardized schemas), or inaccurate. This undermines outcomes, erodes confidence, and introduces risk. Robust, high-quality data is essential ensuring accurate, trustworthy AI outputs.
Here’s a quick rundown of the key elements at the data layer.
- What it is: The system of record and real-time delivery that feeds data into your AI stack. It governs how data is captured, integrated, transformed, and stored across all environments. It ensures that data is available when and where AI systems need it.
- Why it’s important: No matter how advanced the model, it’s worthless without relevant, real-time, high-quality data. An AI strategy lives or dies by the data that feeds it.
- Core requirements:
- Real-time data movement from operational systems, transformed mid-flight with Change Data Capture (CDC).
- Open format support, capable of reading/writing in multiple formats to manage real-time integration across lakes, warehouses, and APIs.
- Centralized, scalable storage that can manage raw and enriched data across hybrid environments.
- Streamlined pipelines that enrich data in motion into AI-ready formats, such as vector embeddings for Retrieval-Augmented Generation (RAG), to power real-time intelligence.
AI/ML Layer

The AI/ML layer is where data is transformed into models that power intelligence—models that predict, classify, generate, or optimize. This is the engine of innovation within the AI stack, converting raw data inputs into actionable outcomes through structured experimentation and iterative refinement.
Optimize your development environment—the training ground for AI
To build performant models, you need a development environment that can handle full-lifecycle model training at scale: from data preparation and model training to tuning, validation, and deployment. The flexibility and efficiency of your training environment determine how fast teams iterate, test new architectures, and deploy intelligent systems.
Modern workloads demand support for both traditional ML and emerging LLMs. This includes building real-time vector embeddings, semantic representations that translate unstructured data like emails, documents, code, and tickets into usable inputs for generative and agentic systems. These embeddings provide context awareness and enable deeper reasoning, retrieval, and personalization capabilities.
Let’s summarize what to look out for:
- What it is: This is where raw data is transformed into intelligence—where models are designed, trained, validated, and deployed to generate predictions, recommendations, or content.
- Why it’s important: This is where AI comes to life. Without this layer, there’s no intelligence — you have infrastructure without insight. The quality, speed, and reliability of your models depend on how effectively you manage the training and experimentation process.
- Core requirements:
- Full-lifecycle model development environments for traditional ML and modern LLMs.
- Real-time vector embedding to support LLMs and agentic systems with semantic awareness.
- Access to scalable compute infrastructure (e.g., GPUs, TPUs) for training complex models.
- Integrated MLOps to streamline experimentation, deployment, and monitoring.
Inference and Decisioning Layer

The inference layer is where AI systems are put to work. This is where models are deployed to answer questions, make predictions, generate content, or trigger actions. It’s where AI begins to actively deliver business value through customer-facing experiences, operational automations, and data-driven decisions.
Empower models with real-time context
AI must be responsive, contextual, and real-time. Especially in user-facing or operational settings—like chatbot interfaces, recommendation engines, or dynamic decisioning systems—context is everything.
To deliver accurate, relevant results, inference pipelines should be tightly integrated with retrieval logic (like RAG) to ground outputs in real-world context. Vector databases play a critical role here, enabling semantic search alongside AI to surface the most relevant information, fast. The result: smarter, more reliable AI that adapts to the moment and drives better outcomes.
To sum up, here are the most important considerations for the inference layer:
- What it is: This is the activation point — where trained models are deployed into production and begin interacting with real-world data and applications.
- Why it’s important: Inference is where AI proves its worth. Whether it’s detecting fraud in real time, providing recommendations, or automating decisions, this is the layer that impacts customers and operations directly.
- Core requirements:
- Model serving that hosts trained models for fast, scalable inference.
- The ability to embed AI directly into data streams for live decision-making.
- RAG combines search (using vector databases) alongside AI to ground outputs in real-time context.
- Flexible deployment interfaces (APIs, event-driven, etc.) that integrate easily into business workflows.
Governance Layer

AI is only as trustworthy as the data it’s built on. As AI scales, so do the risks. The governance layer exists to ensure your AI operates responsibly by securing sensitive data from the start, enforcing compliance, and maintaining trust across every stage of the AI lifecycle.
Observe, detect, protect
With the right governance in place, you can be confident that only clean, compliant data is entering your AI systems. Embed observability systems into your data streams to flag sensitive data early. Ideally, automated protection protocols will find and protect sensitive data before it moves downstream—masking or encrypting or tagging PII, PHI, or financial data to comply with regulatory standards.
Effective governance extends to the behavior of the AI itself. Guardrails are needed not only for the data but for the models—monitoring for drift, hallucinations, and unintended outputs. Full traceability, explainability, and auditability must be built into the system, not bolted on after the fact.
To sum up governance:
- What it is: This is your oversight and control center — it governs the flow of sensitive data, monitors AI performance and behavior, and ensures compliance with internal and external standards.
- Why it’s important: You can’t operationalize AI without trust. Governance ensures your data is protected, your models are accountable, your systems are resilient in the face of scrutiny, drift, or regulation, your business is audit-ready.
- Core requirements:
- Built-in observability that tracks performance, ensures data quality, and operational health.
- Proactive detection of sensitive data (PII, financial, health) before it moves downstream.
- Real-time classification and tagging to enforce policies automatically.
- Full traceability and audit logs to meet internal standards and external regulations.
- AI behavior monitoring to detect anomalies, reduce risk, and prevent unintended or non-compliant outputs.
The Foundation for AI Success
The AI era comes with a new set of demands—for speed, scale, intelligence, and trust.
While many organizations already have elements of a traditional tech stack in place: cloud infrastructure, data warehouses, ML tools, those are no longer enough.
A modern AI stack stands apart because it’s designed from the ground up to:
- Operate in real time, ingesting, processing, and reacting to live data as it flows.
- Scale elastically, handling unpredictable surges in compute demand from training, inference, and agentic workflows.
- Enable AI-native capabilities like vector embeddings, RAG, autonomous agents that reason, plan, and act in complex environments.
- Ensure trust and safety by embedding observability, compliance, and control at every layer.
Without this layered, flexible, end-to-end foundation, AI initiatives will stall before they ever generate value. But with it, organizations are positioned to build smarter products, unlock new efficiencies, and deliver world-changing innovations.
This is the moment to get your foundation right. To get AI-ready.
That covers the five main layers in a modern AI-stack. In part 2, we’ll dive deeper into the data layer specifically, and outline how to attain AI-ready data.
