










Rapid adoption of Google Cloud Spanner requires data migration from on-premise systems. Cloud Spanner is the first scalable, enterprise-grade, globally-distributed, highly available, and strongly consistent database service. However, most of your existing data resides elsewhere, driving business critical applications. How do you move this data to Cloud Spanner?
Demo
In this demo you will see how you can use Striim to migrate an on-premise Oracle database to Cloud Spanner, through our wizard-based UI and intuitive data pipelines, without requiring application downtime.
When migrating applications to the cloud, your application can be changed to use Cloud Spanner, or Google Cloud SQL, but the data will need to be migrated. And migrations don’t happen instantly. Unless you can stop people from using the application, the data will have changed by the time the migration is finished. You will also want to test the cloud application, to ensure it is working correctly, before flipping the switch and finalizing the transition to the cloud. This validation process can take weeks or even months.
So there are two necessary parts. Firstly, you need to make an initial copy of the database, and secondly you need to apply any changes that happen on-premise to the cloud. The initial copy can be made in many ways, but it is important to start collecting change while, and after, the load is happening to ensure the on-premise and cloud databases are, and remain, identical. Change Data Capture, or CDC is used to collect the change from on-premise databases and apply this change to the cloud. CDC directly intercepts database activity and collects all the inserts, updates and deletes as they happen, ready to stream into Cloud Spanner.
Additionally, CDC-based continuous replication enables “liberation of data” for mission critical systems such as inventory, or supply management, where migration is not an option. This also applies to continually generated data from logs or IoT devices. You can use this data to power your Cloud Spanner based applications without having to immediately migrate, so that you can still drive new value from your most sensitive mission critical systems.
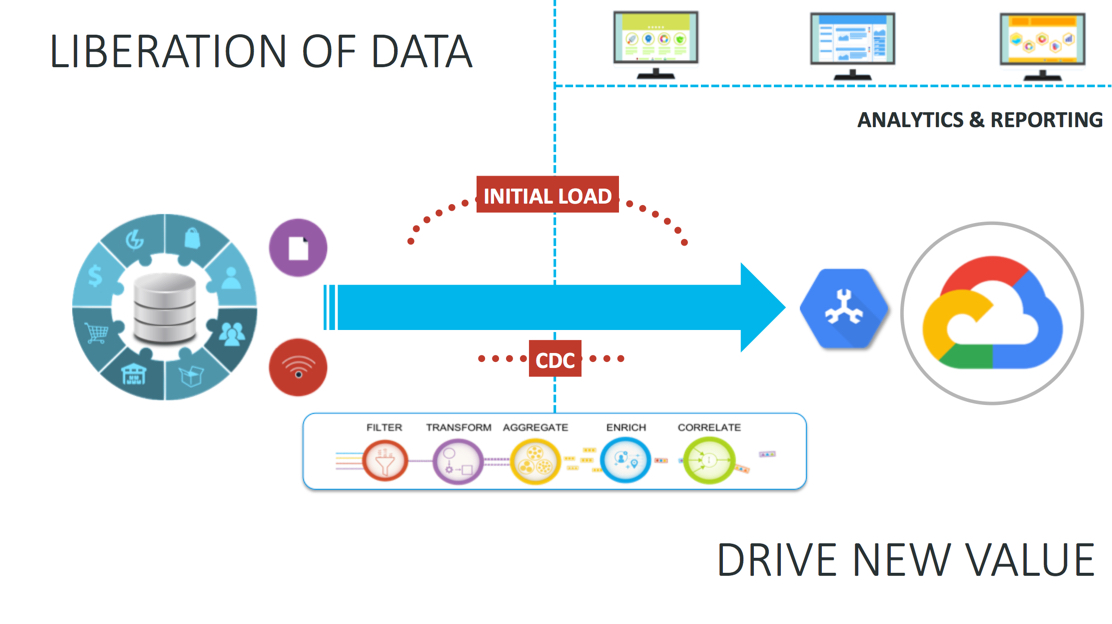 The Striim platform can help with all these requirements and more. Our database adapters support initial loads, and CDC from enterprise or cloud databases. Data from machine logs, devices and messaging systems can also be collected easily, independent of its format, through a variety of high speed adapters and parsers.
The Striim platform can help with all these requirements and more. Our database adapters support initial loads, and CDC from enterprise or cloud databases. Data from machine logs, devices and messaging systems can also be collected easily, independent of its format, through a variety of high speed adapters and parsers.
After being collected continuously, the streaming data can be delivered directly into Cloud Spanner, as well as other Google Cloud targets such as Google Cloud SQL, Storage, Pub/Sub or BigQuery, with very low latency. Or pushed through a data pipeline where it can be pre-processed using SQL-based queries. This enables such things as data denormalization, change detection, de-duplication, and quality checking before the data is ever stored.
In addition to this, because Striim is an enterprise grade platform, it can scale with Cloud Spanner and reliably guarantee delivery of source data while also providing built-in dashboards and verification of data pipelines for operational monitoring purposes.
Migrate an Oracle database to Cloud Spanner
Let’s see how Striim can migrate an Oracle database to Cloud Spanner, by first bulk loading data, followed by applying any changes occurring in the source database to Cloud Spanner in real-time.
The Striim wizard-based UI enables users to rapidly create a new data flow to move data to Cloud Spanner. In this example, real-time change data from Oracle will be continually delivered to Cloud Spanner, to synchronize Spanner with the on-premise database. The wizard walks you through all the configuration steps, checking that everything is set up properly, and results in a data flow application.
You can also create an application to perform an initial load. This flow will move the existing data from the Oracle database table to Cloud Spanner.
To perform the migration we will first start the initial load, followed by applying any changes. Here you can see the table in Cloud Spanner is initially empty. When we start the application, data starts flowing from Oracle to Cloud Spanner. We can monitor the progress through the UI. Once complete all the rows from the Oracle database are present in Cloud Spanner.
Next we start the CDC application. Any changes that we make in the Oracle database will be immediately reflected in Cloud Spanner. As we can see here. We can also monitor the applications in detail, to understand throughput, latency and resource usage.
Striim and Cloud Spanner can change the way you do business. Striim can easily migrate your existing databases to Cloud Spanner, without requiring any source application downtime.
Learn More
- Read today’s press release, “Striim Announces Incremental Data Capture from Google Cloud Spanner“
- Provision Striim for Google Cloud Spanner on the Google Cloud Marketplace




